


先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下:

只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF!
所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少。
最后实现的功能:
1、输入要爬取的微博用户的user_id,获得该用户的所有微博
2、文字内容保存到以%user_id命名文本文件中,所有高清原图保存在weibo_image文件夹中
具体操作:
首先我们要获得自己的cookie,这里只说chrome的获取方法。
1、用chrome打开新浪微博移动端
2、option+command+i调出开发者工具
3、点开Network,将Preserve log选项选中
4、输入账号密码,登录新浪微博
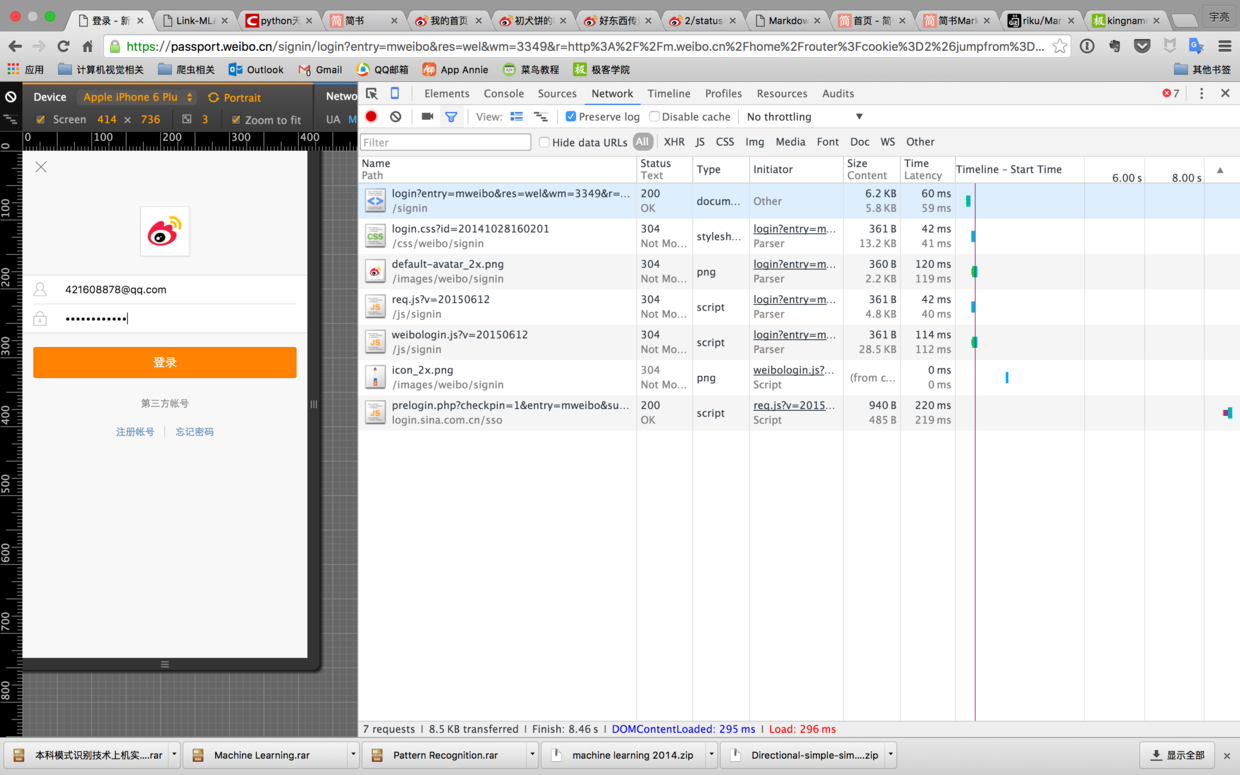
5、找到m.weibo.cn->Headers->Cookie,把cookie复制到代码中的#your cookie处
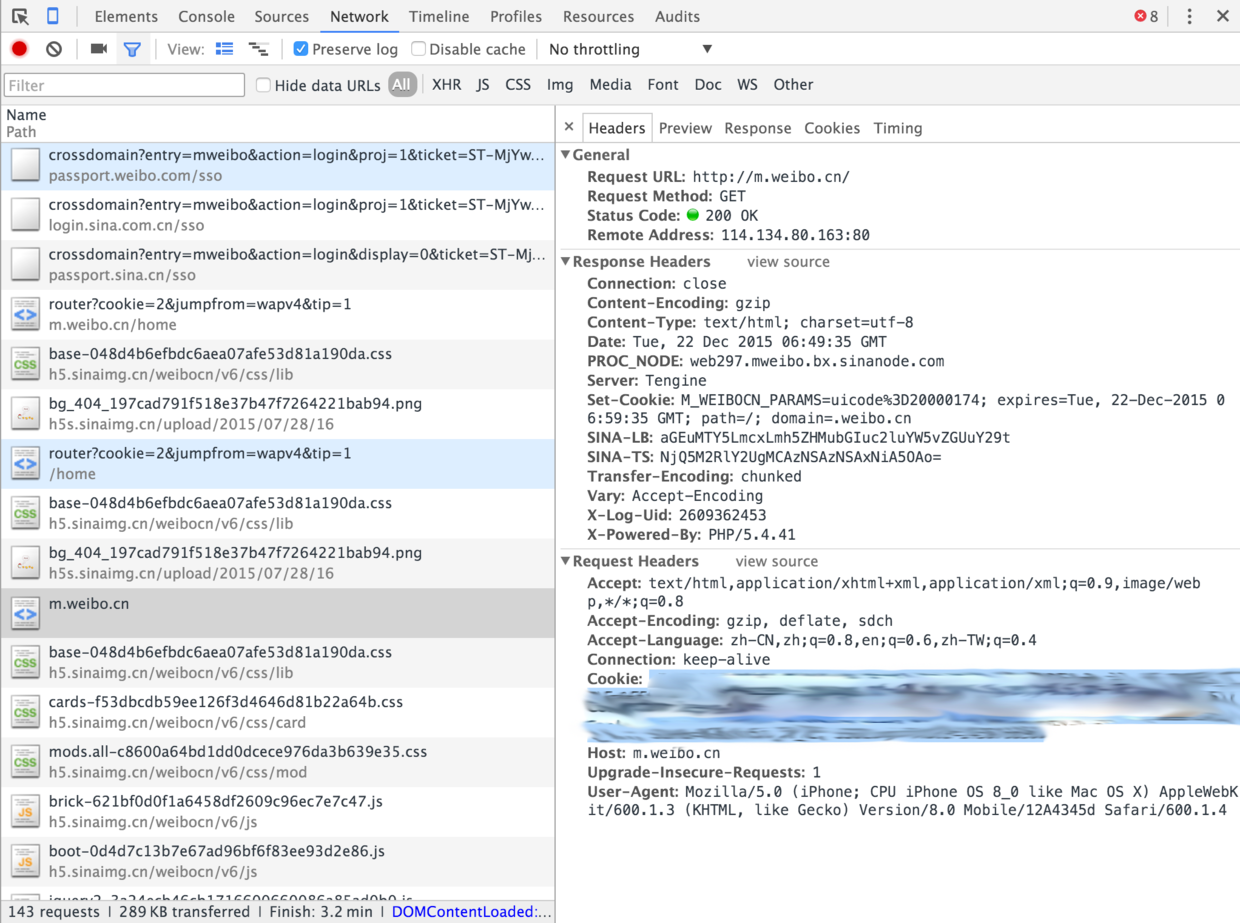
然后再获取你想爬取的用户的user_id,这个我不用多说啥了吧,点开用户主页,地址栏里面那个号码就是user_id
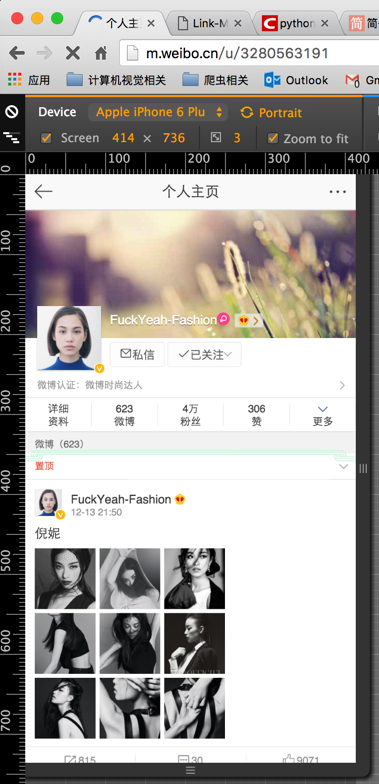
将python代码保存到weibo_spider.py文件中
定位到当前目录下后,命令行执行python weibo_spider.py user_id
当然如果你忘记在后面加user_id,执行的时候命令行也会提示你输入
最后执行结束
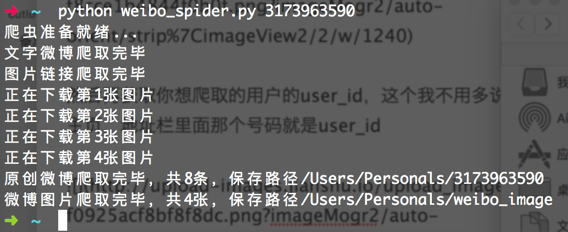
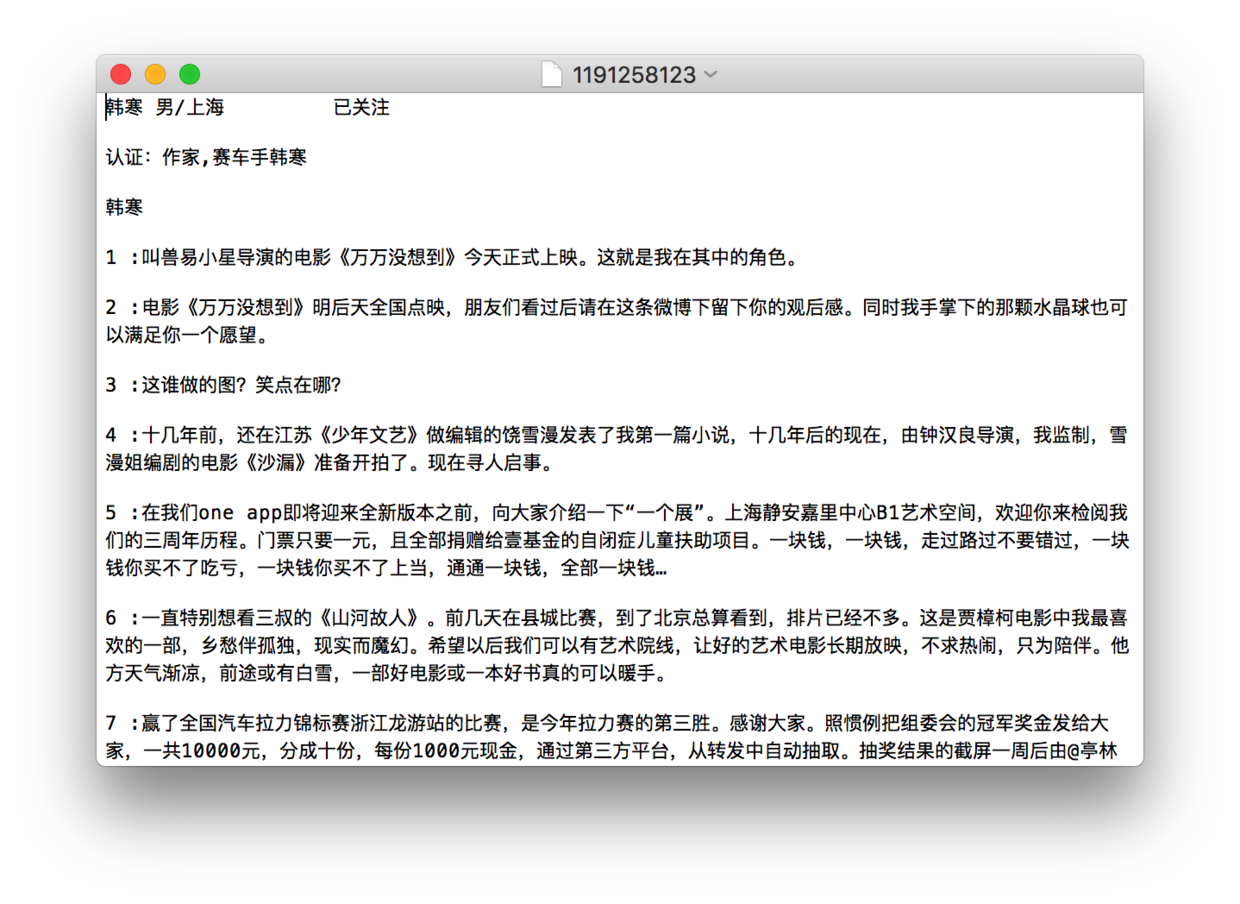
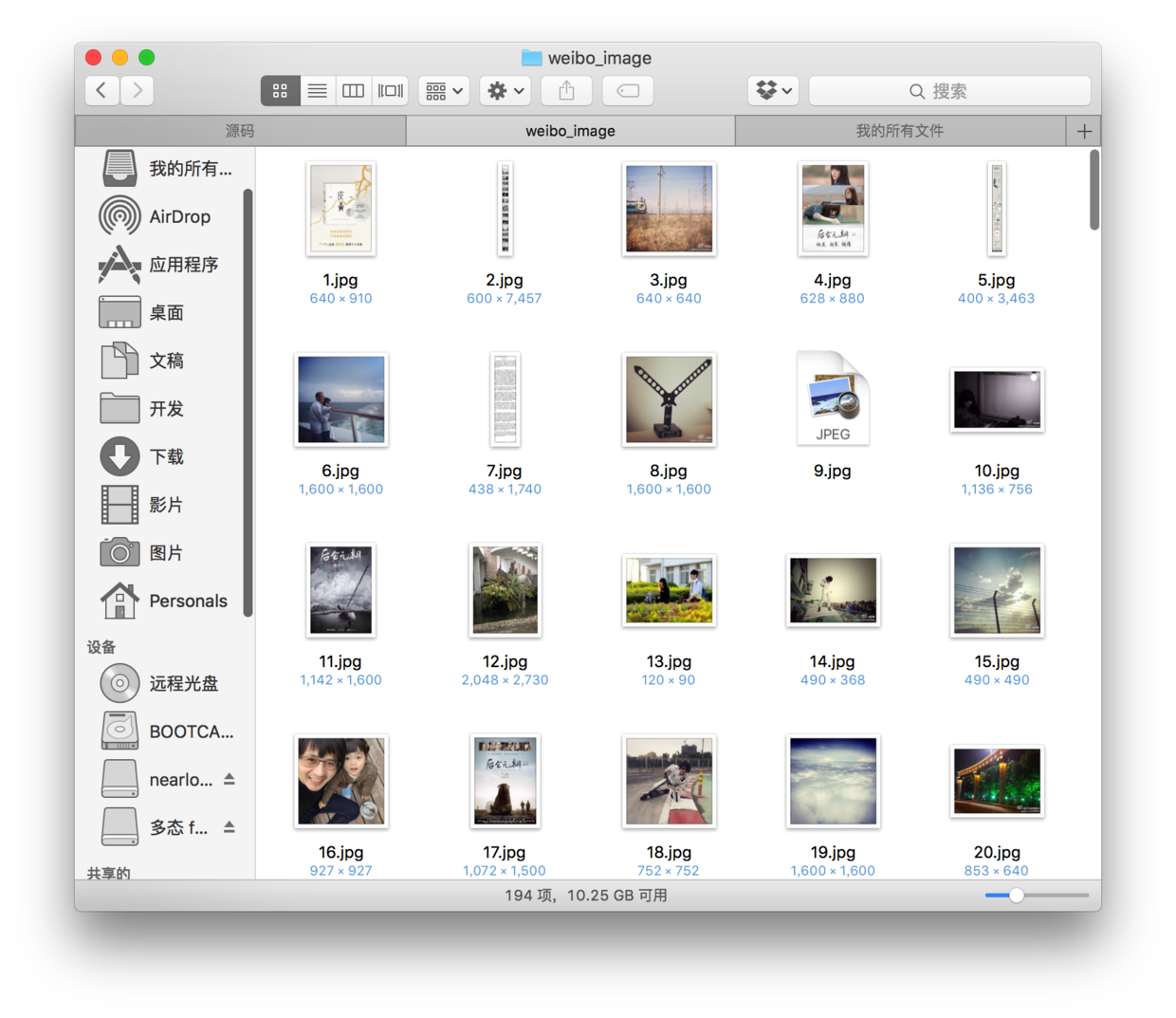
小问题:在我的测试中,有的时候会出现图片下载失败的问题,具体原因还不是很清楚,可能是网速问题,因为我宿舍的网速实在太不稳定了,当然也有可能是别的问题,所以在程序根目录下面,我还生成了一个userid_imageurls的文本文件,里面存储了爬取的所有图片的下载链接,如果出现大片的图片下载失败,可以将该链接群一股脑导进迅雷等下载工具进行下载。
另外,我的系统是OSX EI Capitan10.11.2,Python的版本是2.7,依赖库用sudo pip install XXXX就可以安装,具体配置问题可以自行stackoverflow,这里就不展开讲了。
下面我就给出实现代码
#-*-coding:utf8-*-
import re
import string
import sys
import os
import urllib
import urllib2
from bs4 import BeautifulSoup
import requests
from lxml import etree
reload(sys)
sys.setdefaultencoding('utf-8')
if(len(sys.argv)>=2):
user_id = (int)(sys.argv[1])
else:
user_id = (int)(raw_input(u"请输入user_id: "))
cookie = {"Cookie": "#your cookie"}
url = 'http://weibo.cn/u/%d?filter=1&page=1'%user_id
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum = (int)(selector.xpath('//input[@name="mp"]')[0].attrib['value'])
result = ""
urllist_set = set()
word_count = 1
image_count = 1
print u'爬虫准备就绪...'
for page in range(1,pageNum+1):
#获取lxml页面
url = 'http://weibo.cn/u/%d?filter=1&page=%d'%(user_id,page)
lxml = requests.get(url, cookies = cookie).content
#文字爬取
selector = etree.HTML(lxml)
content = selector.xpath('//span[@class="ctt"]')
for each in content:
text = each.xpath('string(.)')
if word_count>=4:
text = "%d :"%(word_count-3) +text+"\n\n"
else :
text = text+"\n\n"
result = result + text
word_count += 1
#图片爬取
soup = BeautifulSoup(lxml, "lxml")
urllist = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first = 0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url)
image_count +=1
fo = open("/Users/Personals/%s"%user_id, "wb")
fo.write(result)
word_path=os.getcwd()+'/%d'%user_id
print u'文字微博爬取完毕'
link = ""
fo2 = open("/Users/Personals/%s_imageurls"%user_id, "wb")
for eachlink in urllist_set:
link = link + eachlink +"\n"
fo2.write(link)
print u'图片链接爬取完毕'
if not urllist_set:
print u'该页面中不存在图片'
else:
#下载图片,保存在当前目录的pythonimg文件夹下
image_path=os.getcwd()+'/weibo_image'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp= image_path + '/%s.jpg' % x
print u'正在下载第%s张图片' % x
try:
urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp)
except:
print u"该图片下载失败:%s"%imgurl
x+=1
print u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path)
print u'微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path)
一个简单的微博爬虫就完成了,希望对大家的学习有所帮助。

 파이썬에서 두 목록을 연결하는 대안은 무엇입니까?May 09, 2025 am 12:16 AM
파이썬에서 두 목록을 연결하는 대안은 무엇입니까?May 09, 2025 am 12:16 AMPython에는 두 개의 목록을 연결하는 방법이 많이 있습니다. 1. 연산자 사용 간단하지만 큰 목록에서는 비효율적입니다. 2. 효율적이지만 원래 목록을 수정하는 확장 방법을 사용하십시오. 3. 효율적이고 읽기 쉬운 = 연산자를 사용하십시오. 4. 메모리 효율적이지만 추가 가져 오기가 필요한 itertools.chain function을 사용하십시오. 5. 우아하지만 너무 복잡 할 수있는 목록 구문 분석을 사용하십시오. 선택 방법은 코드 컨텍스트 및 요구 사항을 기반으로해야합니다.
 파이썬 : 두 목록을 병합하는 효율적인 방법May 09, 2025 am 12:15 AM
파이썬 : 두 목록을 병합하는 효율적인 방법May 09, 2025 am 12:15 AMPython 목록을 병합하는 방법에는 여러 가지가 있습니다. 1. 단순하지만 큰 목록에 대한 메모리 효율적이지 않은 연산자 사용; 2. 효율적이지만 원래 목록을 수정하는 확장 방법을 사용하십시오. 3. 큰 데이터 세트에 적합한 itertools.chain을 사용하십시오. 4. 사용 * 운영자, 한 줄의 코드로 중소형 목록을 병합하십시오. 5. Numpy.concatenate를 사용하십시오. 이는 고성능 요구 사항이있는 대규모 데이터 세트 및 시나리오에 적합합니다. 6. 작은 목록에 적합하지만 비효율적 인 Append Method를 사용하십시오. 메소드를 선택할 때는 목록 크기 및 응용 프로그램 시나리오를 고려해야합니다.
 편집 된 vs 해석 언어 : 장단점May 09, 2025 am 12:06 AM
편집 된 vs 해석 언어 : 장단점May 09, 2025 am 12:06 AMCompiledLanguagesOfferSpeedSecurity, while InterpretedLanguagesProvideeaseofusEandportability
 파이썬 : 가장 완전한 가이드 인 루프를 위해May 09, 2025 am 12:05 AM
파이썬 : 가장 완전한 가이드 인 루프를 위해May 09, 2025 am 12:05 AMPython에서, for 루프는 반복 가능한 물체를 가로 지르는 데 사용되며, 조건이 충족 될 때 반복적으로 작업을 수행하는 데 사용됩니다. 1) 루프 예제 : 목록을 가로 지르고 요소를 인쇄하십시오. 2) 루프 예제 : 올바르게 추측 할 때까지 숫자 게임을 추측하십시오. 마스터 링 사이클 원리 및 최적화 기술은 코드 효율성과 안정성을 향상시킬 수 있습니다.
 Python은 문자열로 나열됩니다May 09, 2025 am 12:02 AM
Python은 문자열로 나열됩니다May 09, 2025 am 12:02 AM목록을 문자열로 연결하려면 Python의 join () 메소드를 사용하는 것이 최선의 선택입니다. 1) join () 메소드를 사용하여 목록 요소를 ''.join (my_list)과 같은 문자열로 연결하십시오. 2) 숫자가 포함 된 목록의 경우 연결하기 전에 맵 (str, 숫자)을 문자열로 변환하십시오. 3) ','. join (f '({fruit})'forfruitinfruits와 같은 복잡한 형식에 발전기 표현식을 사용할 수 있습니다. 4) 혼합 데이터 유형을 처리 할 때 MAP (str, mixed_list)를 사용하여 모든 요소를 문자열로 변환 할 수 있도록하십시오. 5) 큰 목록의 경우 ''.join (large_li
 Python의 하이브리드 접근법 : 컴파일 및 해석 결합May 08, 2025 am 12:16 AM
Python의 하이브리드 접근법 : 컴파일 및 해석 결합May 08, 2025 am 12:16 AMPythonuseSahybrideactroach, combingingcompytobytecodeandingretation.1) codeiscompiledToplatform-IndependentBecode.2) bytecodeistredbythepythonvirtonmachine, enterancingefficiency andportability.
 Python 's 'for'와 'whind'루프의 차이점을 배우십시오May 08, 2025 am 12:11 AM
Python 's 'for'와 'whind'루프의 차이점을 배우십시오May 08, 2025 am 12:11 AM"for"and "while"loopsare : 1) "에 대한"loopsareIdealforitertatingOverSorkNowniterations, whide2) "weekepindiTeRations.Un
 Python Concatenate는 중복과 함께 목록입니다May 08, 2025 am 12:09 AM
Python Concatenate는 중복과 함께 목록입니다May 08, 2025 am 12:09 AMPython에서는 다양한 방법을 통해 목록을 연결하고 중복 요소를 관리 할 수 있습니다. 1) 연산자를 사용하거나 ()을 사용하여 모든 중복 요소를 유지합니다. 2) 세트로 변환 한 다음 모든 중복 요소를 제거하기 위해 목록으로 돌아가지 만 원래 순서는 손실됩니다. 3) 루프 또는 목록 이해를 사용하여 세트를 결합하여 중복 요소를 제거하고 원래 순서를 유지하십시오.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

