


1、Set基本数据类型
a、set集合,是一个无序且不重复的元素集合
class set(object):
"""
set() -> new empty set object
set(iterable) -> new set object
Build an unordered collection of unique elements.
"""
def add(self, *args, **kwargs): # real signature unknown
"""
Add an element to a set,添加元素
This has no effect if the element is already present.
"""
pass
def clear(self, *args, **kwargs): # real signature unknown
""" Remove all elements from this set. 清楚内容"""
pass
def copy(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a set. 浅拷贝 """
pass
def difference(self, *args, **kwargs): # real signature unknown
"""
Return the difference of two or more sets as a new set. A中存在,B中不存在
(i.e. all elements that are in this set but not the others.)
"""
pass
def difference_update(self, *args, **kwargs): # real signature unknown
""" Remove all elements of another set from this set. 从当前集合中删除和B中相同的元素"""
pass
def discard(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set if it is a member.
If the element is not a member, do nothing. 移除指定元素,不存在不保错
"""
pass
def intersection(self, *args, **kwargs): # real signature unknown
"""
Return the intersection of two sets as a new set. 交集
(i.e. all elements that are in both sets.)
"""
pass
def intersection_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the intersection of itself and another. 取交集并更更新到A中 """
pass
def isdisjoint(self, *args, **kwargs): # real signature unknown
""" Return True if two sets have a null intersection. 如果没有交集,返回True,否则返回False"""
pass
def issubset(self, *args, **kwargs): # real signature unknown
""" Report whether another set contains this set. 是否是子序列"""
pass
def issuperset(self, *args, **kwargs): # real signature unknown
""" Report whether this set contains another set. 是否是父序列"""
pass
def pop(self, *args, **kwargs): # real signature unknown
"""
Remove and return an arbitrary set element.
Raises KeyError if the set is empty. 移除元素
"""
pass
def remove(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set; it must be a member.
If the element is not a member, raise a KeyError. 移除指定元素,不存在保错
"""
pass
def symmetric_difference(self, *args, **kwargs): # real signature unknown
"""
Return the symmetric difference of two sets as a new set. 对称交集
(i.e. all elements that are in exactly one of the sets.)
"""
pass
def symmetric_difference_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the symmetric difference of itself and another. 对称交集,并更新到a中 """
pass
def union(self, *args, **kwargs): # real signature unknown
"""
Return the union of sets as a new set. 并集
(i.e. all elements that are in either set.)
"""
pass
def update(self, *args, **kwargs): # real signature unknown
""" Update a set with the union of itself and others. 更新 """
pass
b、数据类型模块举例
se = {11,22,33,44,55}
be = {44,55,66,77,88}
# se.add(66)
# print(se) #添加元素,不能直接打印!
#
#
#
# se.clear()
# print(se) #清除se集合里面所有的值,不能清除单个
#
#
#
# ce=be.difference(se) #se中存在,be中不存在的值,必须赋值给一个新的变量
# print(ce)
#
#
# se.difference_update(be)
# print(se) #在se中删除和be相同的值,不能赋值给一个新的变量,先输入转换,然后打印,也不能直接打印!
# se.discard(11)
# print(se) #移除指定元素,移除不存在的时候,不会报错
# se.remove(11)
# print(se) #移除指定的元素,移除不存在的会报错
# se.pop()
# print(se) #移除随机的元素
#
#
# ret=se.pop()
# print(ret) #移除元素,并且可以把移除的元素赋值给另一个变量
# ce = se.intersection(be)
# print(ce) #取出两个集合的交集(相同的元素)
# se.intersection_update(be)
# print(se) #取出两个集合的交集,并更新到se集合中
# ret = se.isdisjoint(be)
# print(ret) #判断两个集合之间又没有交集,如果有交集返回False,没有返回True
# ret=se.issubset(be)
# print(ret) #判断se是否是be集合的子序列,如果是返回True,不是返回Flase
# ret = se.issuperset(be)
# print(ret) #判断se是不是be集合的父序列,如果是返回True,不是返回Flase
# ret=se.symmetric_difference(be)
# print(ret) #对称交集,取出除了不相同的元素
# se.symmetric_difference_update(be)
# print(se) #对称交集,取出不相同的元素并更新到se集合中
# ret = se.union(be)
# print(ret) #并集,把两个元素集合并在一个新的变量中
2、深浅拷贝
a、数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
import copy # ######### 数字、字符串 ######### n1 = 123 # n1 = "i am alex age 10" print(id(n1)) # ## 赋值 ## n2 = n1 print(id(n2)) # ## 浅拷贝 ## n2 = copy.copy(n1) print(id(n2)) # ## 深拷贝 ## n3 = copy.deepcopy(n1) print(id(n3))
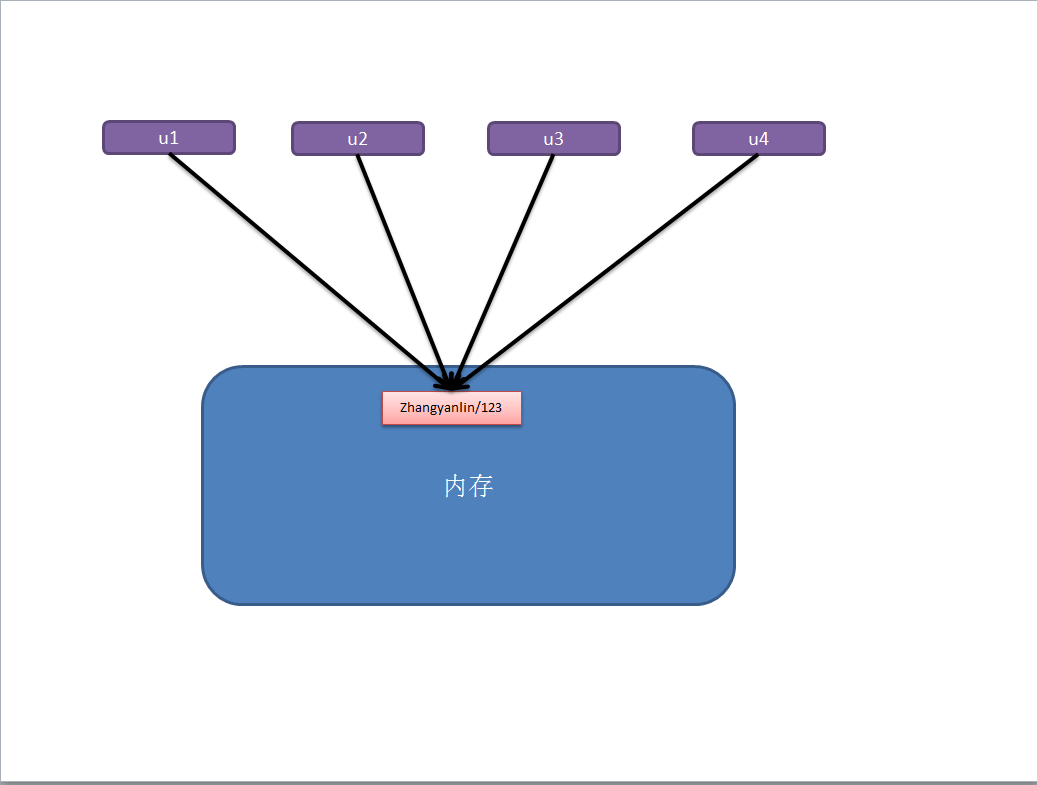
b、其他基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "zhangyanlin", "k2": 123, "k3": ["Aylin", 456]}
n2 = n1
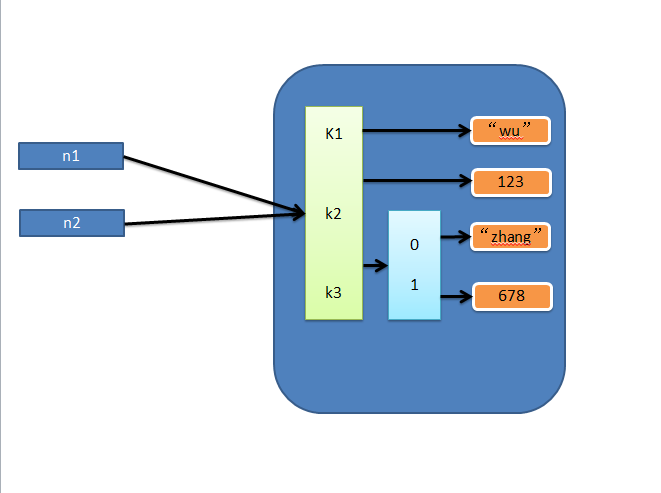
2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
import copy
n1 = {"k1": "zhangyanlin", "k2": 123, "k3": ["aylin", 456]}
n3 = copy.copy(n1)
3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
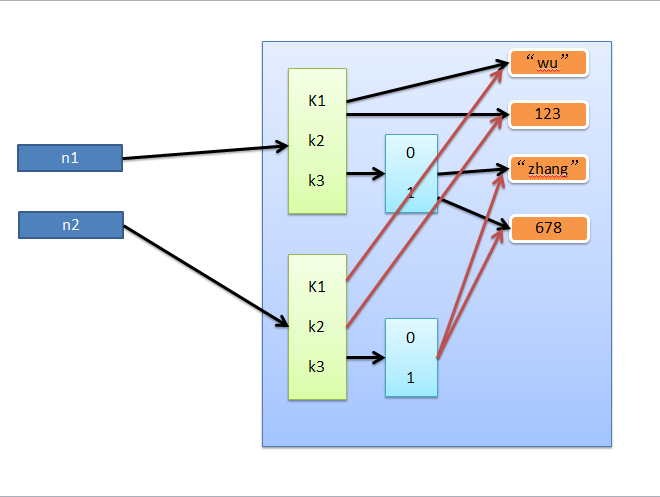
3、函数
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
面向对象:对函数进行分类和封装,让开发“更快更好更强...
.函数的定义主要有如下要点:
def:表示函数的关键字
函数名:函数的名称,日后根据函数名调用函数
函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
参数:为函数体提供数据
返回值:当函数执行完毕后,可以给调用者返回数据。
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
以上要点中,比较重要有参数和返回值:
def 发送短信():
发送短信的代码...
if 发送成功:
return True
else:
return False
while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作
result = 发送短信()
if result == False:
短信发送失败...
函数的有三中不同的参数:
普通参数
# ######### 定义函数 #########
# name 叫做函数func的形式参数,简称:形参
def func(name):
print name
# ######### 执行函数 #########
# 'zhangyanlin' 叫做函数func的实际参数,简称:实参
func('zhangyanlin')
默认参数
def func(name, age = 18):
print "%s:%s" %(name,age)
# 指定参数
func('zhangyanlin', 19)
# 使用默认参数
func('nick')
注:默认参数需要放在参数列表最后
动态参数
def func(*args): print args # 执行方式一 func(11,33,4,4454,5) # 执行方式二 li = [11,2,2,3,3,4,54] func(*li)
def func(**kwargs):
print args
# 执行方式一
func(name='wupeiqi',age=18)
# 执行方式二
li = {'name':'wupeiqi', age:18, 'gender':'male'}
func(**li)
def func(*args, **kwargs): print args print kwargs
邮件实例:
def email(p,j,k):
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
set = True
try:
msg = MIMEText('j', 'plain', 'utf-8') #j 邮件内容
msg['From'] = formataddr(["武沛齐",'wptawy@126.com'])
msg['To'] = formataddr(["走人",'424662508@qq.com'])
msg['Subject'] = "k" #k主题
server = smtplib.SMTP("smtp.126.com", 25)
server.login("wptawy@126.com", "WW.3945.59")
server.sendmail('wptawy@126.com', [p], msg.as_string())
server.quit()
except:
set = False
return True
formmail = input("请你输入收件人邮箱:")
zhuti = input("请您输入邮件主题:")
neirong = input("请您输入邮件内容:")
aa=email(formmail,neirong,zhuti)
if aa:
print("邮件发送成功!")
else:
print("邮件发送失败!")

 파이썬에서 튜플 이해력이 가능합니까? 그렇다면, 어떻게 그리고 그렇지 않다면?Apr 28, 2025 pm 04:34 PM
파이썬에서 튜플 이해력이 가능합니까? 그렇다면, 어떻게 그리고 그렇지 않다면?Apr 28, 2025 pm 04:34 PM기사는 구문 모호성으로 인해 파이썬에서 튜플 이해의 불가능성에 대해 논의합니다. 튜플을 효율적으로 생성하기 위해 튜플 ()을 사용하는 것과 같은 대안이 제안됩니다. (159 자)
 파이썬의 모듈과 패키지는 무엇입니까?Apr 28, 2025 pm 04:33 PM
파이썬의 모듈과 패키지는 무엇입니까?Apr 28, 2025 pm 04:33 PM이 기사는 파이썬의 모듈과 패키지, 차이점 및 사용법을 설명합니다. 모듈은 단일 파일이고 패키지는 __init__.py 파일이있는 디렉토리이며 관련 모듈을 계층 적으로 구성합니다.
 파이썬에서 Docstring이란 무엇입니까?Apr 28, 2025 pm 04:30 PM
파이썬에서 Docstring이란 무엇입니까?Apr 28, 2025 pm 04:30 PM기사는 Python의 Docstrings, 사용법 및 혜택에 대해 설명합니다. 주요 이슈 : 코드 문서 및 접근성에 대한 문서의 중요성.
 람다 기능이란 무엇입니까?Apr 28, 2025 pm 04:28 PM
람다 기능이란 무엇입니까?Apr 28, 2025 pm 04:28 PM기사는 Lambda 기능, 일반 기능과의 차이 및 프로그래밍 시나리오에서의 유틸리티에 대해 설명합니다. 모든 언어가 그들을 지원하는 것은 아닙니다.
 휴식은 무엇입니까, 계속해서 파이썬을 통과합니까?Apr 28, 2025 pm 04:26 PM
휴식은 무엇입니까, 계속해서 파이썬을 통과합니까?Apr 28, 2025 pm 04:26 PM기사는 파괴, 계속 및 Python을 통과시켜 루프 실행 및 프로그램 흐름을 제어하는 역할을 설명합니다.
 파이썬의 패스는 무엇입니까?Apr 28, 2025 pm 04:25 PM
파이썬의 패스는 무엇입니까?Apr 28, 2025 pm 04:25 PM이 기사는 기능 및 클래스와 같은 코드 구조에서 자리 표시 자로 사용되는 NULL 작업 인 Python의 'Pass'명령문에 대해 설명하여 구문 오류없이 향후 구현을 허용합니다.
 파이썬에서 인수로 기능을 전달할 수 있습니까?Apr 28, 2025 pm 04:23 PM
파이썬에서 인수로 기능을 전달할 수 있습니까?Apr 28, 2025 pm 04:23 PM기사는 파이썬의 인수와 같은 기능을 전달하는 것에 대해 논의하며, 모듈성과 같은 이점 및 분류 및 장식기와 같은 사용 사례를 강조합니다.
 파이썬에서 //의 차이점은 무엇입니까?Apr 28, 2025 pm 04:21 PM
파이썬에서 //의 차이점은 무엇입니까?Apr 28, 2025 pm 04:21 PM기사는 Python의 / 및 // 연산자에 대해 논의합니다 : / True Division, // for floor division. 주요 이슈는 차이점과 사용 사례를 이해하는 것입니다. 문자 수 : 158


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

