


SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。 有人说: select count(1)
SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。
有人说:
select count(1) from table
select count(primarykey) from table
比较快,一定不要用
select count(*) from table
可我要说的是,count(*)更快一些,为什么呢,count(*)是什么意思?事实上,它真正的含义是找一个占用空间最小的索引字段,然后对它进行记数,不要一看到*就认为“大”,在count命令中,它指的是“任意一个“。
对于一个大表来说,如果你的字段有bit类型,,如性别字段,表示真假关系的字段,我们需要为它加上索引,加上之后,我们的count速度就提交几十倍,真的,呵呵
首先为我们的bit类型字段加索引IsSync添加聚集索引
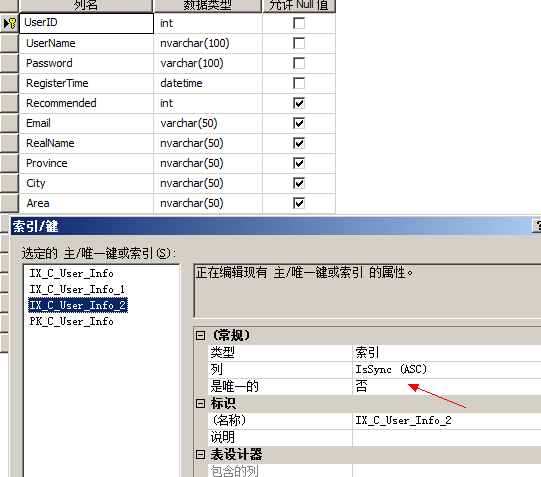
如果数据表太大,我们需要在命令行中去运行

 Python竟然还可以计算农历!Apr 30, 2023 am 09:43 AM
Python竟然还可以计算农历!Apr 30, 2023 am 09:43 AM最近处理工作任务的时候遇到了转换农历的问题。农历,是我国现行的传统历法。它是根据月相的变化周期,每一次月相朔望变化为一个月,参考太阳回归年为一年的长度,并加入二十四节气与设置闰月以使平均历年与回归年相适应[1]。对于我们处理数据来说,并不需要去详细研究农历与公历之间的转换关系。在Python中,ZhDate库支持农历-公历互相转换、日期加减以及全中文日期生成,内置了1900-2100年的农历数据,仅依赖Python内置模块。github.com/CutePandaSh/zhdate由于ZhDat
 如何在 Rocky Linux 9 / AlmaLinux 9 上安装 KVMJun 09, 2023 pm 10:07 PM
如何在 Rocky Linux 9 / AlmaLinux 9 上安装 KVMJun 09, 2023 pm 10:07 PMKVM是内核虚拟机KernelVirtualizationMachine与大多数虚拟化平台一样,它将硬件资源(如CPU、内存、存储、网络、图形等)抽象化,并将它们分配给独立于宿主机运行的客户机。先决条件预装RockyLinux9/AlmaLinux9具有管理员权限的sudo用户互联网连接1、验证是否启用了硬件虚拟化首先,你需要验证你的系统是否启用了虚拟化功能。在大多数现代系统上,此功能已在BIOS中启用。但可以肯定的是,你可以验证是否如图所示启用了虚拟化。该命令探测是否存在VMX(虚拟机扩展Vi
 如何查看和管理 Linux 命令历史记录Aug 01, 2023 pm 09:17 PM
如何查看和管理 Linux 命令历史记录Aug 01, 2023 pm 09:17 PM如何在Linux中查看命令历史记录在Linux中,我们使用history命令来查看所有以前执行的命令的列表。它有一个非常简单的语法:history与历史记录命令配对的一些选项包括:选项描述-c清除当前会话的命令历史记录-w将命令历史记录写入文件-r从历史记录文件重新加载命令历史记录-n限制最近命令的输出数量只需运行history命令即可在Linux终端中查看所有以前执行的命令的列表:除了查看命令历史记录之外,您还可以管理命令历史记录并执行修改先前执行的命令、反向搜索命令历史记录甚至完全删除历史记
 counta和count的区别Nov 20, 2023 am 10:01 AM
counta和count的区别Nov 20, 2023 am 10:01 AMCount函数用于计算指定范围内数字的个数。它忽略文本、逻辑值和空值,但会将空单元格计算在内,Count函数只计算包含实际数字的单元格数量。而CountA函数用于计算指定范围内非空单元格的个数。它不仅计算包含实际数字的单元格,还计算包含文本、逻辑值和公式等非空单元格的数量。
 在 Windows 11 上安装 VMware Workstation 只需一个简单的命令Sep 12, 2023 pm 08:33 PM
在 Windows 11 上安装 VMware Workstation 只需一个简单的命令Sep 12, 2023 pm 08:33 PM步骤1:打开PowerShell或命令提示符在您的Windows11或10系统上,转到搜索框并根据您的选择键入CMD或Powershell。这里我们使用PowerShell。当它出现在结果中时,选择“以管理员身份运行”。这是因为我们需要管理员用户访问权限才能运行命令以在Windows上安装任何软件。第2步:检查Winget可用性好吧,尽管所有最新版本的Windows10和11默认情况下都带有Winget工具。但是,让我们首先检查它是否可以使用。类型:winget作为回报,您将看到可与命令一起使用
 如何在 Ubuntu 22.04 / 20.04 上配置 FreeIPA 客户端Jun 09, 2023 pm 02:18 PM
如何在 Ubuntu 22.04 / 20.04 上配置 FreeIPA 客户端Jun 09, 2023 pm 02:18 PMFreeIPA是一个强大的开源身份管理系统,提供集中的身份验证、授权和计费服务。在我们之前的帖子中,我们已经讨论了FreeIPA服务器在RHEL8/RokcyLinux8/AlmaLinux8上的安装步骤。在FreeIPA服务器上创建用户进行集中认证登录到你的FreeIPA服务器并创建一个名为sysadm的用户,运行以下命令:$sudokinitadminPasswordforadmin@LINUXTECHI.LAN:$$sudoipaconfig-mod--defaultshell=/bin/
 超全!Python获取某一日期是“星期几”的六种方法!Apr 19, 2023 am 09:28 AM
超全!Python获取某一日期是“星期几”的六种方法!Apr 19, 2023 am 09:28 AM在Python进行数据分析时,按照日期进行分组汇总也是被需要的,比如会找到销量的周期性规律。那么在用Python进行数据统计之前,就需要额外增加一步:从指定的日期当中获取星期几。比如2022年2月22日,还正好是正月廿二星期二,于是乎这一天登记结婚的人特别多。本文就以2022-02-22为例,演示Python获取指定日期是“星期几”的6种方法!weekday()datetime模块是一个Python内置库,无需再进行pip安装,它除了可以显示日期和时间之外,还可以进行日期和时间的运算以及格式化。
 怎么解决pip不是内部或外部命令问题Jan 01, 2021 pm 01:46 PM
怎么解决pip不是内部或外部命令问题Jan 01, 2021 pm 01:46 PM解决pip不是内部或外部命令问题的方法:1、右键点击此电脑,打开属性;2、切换到高级栏目,点击环境变量选项;3、找到PATH变量,将pip所在路径添加到属性值中即可。


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

Dreamweaver Mac版
시각적 웹 개발 도구

