


目前XML解析的方法主要用两种: 1、dom解析:(Document Object Model,即文档对象模型)是W3C组织推荐的解析XML的一种方式。 使用dom解析XML文档,该解析器会先把XML文档加载到内存中,生成该XML文档对应的document对象,然后把XML文档中的各个标签元素变成
目前XML解析的方法主要用两种:
1、dom解析:(Document Object Model,即文档对象模型)是W3C组织推荐的解析XML的一种方式。使用dom解析XML文档,该解析器会先把XML文档加载到内存中,生成该XML文档对应的document对象,然后把XML文档中的各个标签元素变成相应的Element对象,文本会变成Text对象,属性会变成Attribute对象,并按这些标签、文本、属性在XML文档中的关系保存这些对象的关系。
缺点:消耗内存,所以使用dom解析XML文档时不能解析太大的XML文档,否则有可能会造成内存溢出。
优点:使用dom解析XML文档可以很方便的执行增删改查操作(可以直接根据节点对应的对象进行操作)。
2、sax解析:Simple API for XML,不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它。
使用sax解析XML文档,该解析器会从上往下读,读一行,解析一行;
优点:因为它解析XML文档是采取读一行,解析一行的方式,所以它不会对内存造成压力。缺点:不适合执行增删改查的操作(也是因为它解析XML文档时采取的读一行解析一行的方式,所以它不能往回操作),只适合对XML文档进行读取操作。
======================================================================================================
补充:
XML解析开发包:Jaxp(sun)、Jdom、dom4j;
======================================================================================================
调整JVM内存大小:
当我们要解析的XML文档内存比较大、而且要对该XML中的节点数据进行相关的操作时,使用这两种解析方式显然都会不方便,这时就需要调整JVM内存的大小了。
JVM默认的允许最大内存容量是64M(根据jdk的版本不同,默认的最大容量值不一样,jdk5.0版本的是64MB,jdk7版本的是170MB)。
调整JVM内存大小的方法(相应的命令为:-Xmx内存大小值单位):
在Eclipse中的项目导航框中右击相应的Java程序》》Run As》》Open Run Dialog...》》打开Run对话框》》选择Arguments选项,在开窗口中有两个输入框,第一个是程序的参数输入框,第二个是VM的参数输入框,在第二个VM的参数输入框中输入Xmx200M》》点击右下角的Run按钮,执行相应的Java程序,就不会报OutOfMemoryError的错误了。
======================================================================================================
XML解析开发包:
1、JAXP:JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成。
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到XML文档的dom或sax的解析器,从而实现对XML文档的解析。
首先、创建工厂:
DocumentBuilderFactory factory = DocumentBuilderFactroy.newInstance();//因为DocumentBuilderFactory类是抽象类,不能new出它的对象只能调用它的静态方法获取它的对象。
其次、得到dom解析器:
DocumentBuilder builder = factory.newDocumentBuilder();
然后、加载XML文档,得到代表文档的Document对象:
Document document = builder.parse("*.xml");
拿到代表XML文档的document对象就可以操作XML文档中的各个节点了。
======================================================================================================
补充:
dom解析下,XML文档的每一个组成部分都会用一个对象表示,例如标签用Element,属性用Attribute,但不管什么对象,都是Node的子类,所以在开发中可以把获取到的任意节点都当作Node对待。
XML编程(CRUD)
create、read、update、delete
添加、查询、更新、删除;
除了这两种解析方法外,还有另外的解析方法。。。
======================================================================================================
在对XML文档进行添加、修改和删除操作时,不仅要更新document对象还要更新XML文档(把更新后的document对象重写到XML文档中)。
javax.xml.transform包中的Transformer类用于把代表XML文档的Document对象转换为某种格式后输出,例如把XML文档应用样式表后转换成一个HTML文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文档中。源和目的地。可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
Transformer类通过transform方法完成转换操作,该方法接收个
(工厂对象(TransformerFactory)》》》转换器对象(Transformer)》》》转换方法(transform(DOMSource 源,StreamResult 目的地);))
======================================================================================================
SAX解析:
SAX解析采用事件处理的方式解析XML文件,利用SAX解析XML文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个指定部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的XML文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松的得到SAX解析器解析到的数据,从而可以决定如何对数据进行处理。
1、创建解析工厂;
SAXParserFactory fac = SAXParserFactory.newInstance();
2、获取解析器;
SAXParser sp = fac.newSAXParser();
3、得到读取器;
XMLReader re = sp.getXMLReader();
4、设置内容处理器;
re.setContentHandler(new ContentHandler(){ /*实现接口的代码块*/});
(或者:re.setContentHandler(new DefaultHandler());/*参数为DefaultHandler类的子类*/)
第一种方法是解析整个XML文档,第二种方法可以只解析某个标签;
其实还有一种内容处理器,也是先继承DefaultHandler类,然后把解析的内容封装到bean对象中。
5、读取XML文档内容;
re.parse("*.xml");
======================================================================================================
XML解析开发包:
2、dom4j:
SAXReader saxReader = new SAXReader();
Document doc = saxReader.read(new File());
OutputFormat format = OutputFormat.createPrettyPrint();//该对象标明格式按漂亮的格式进行输出;另外还有一个对象是按紧凑的格式进行输出;
format.setEncoding("UTF-8");
XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(),format);
xmlWriter.write(doc);//如果xmlWriter对象采用的流是字节流,那么该对象会先把doc对象按format对象给定的编码格式转换成字节,然后把数据交给字节流进行操作。
writer.close();//最后要关闭资源
======================================================================================================
XPath:
使用XPath可以快速定位到某个节点;
List list = document.selectNodes("//foo/bar");//获取foo节点下的所有bar节点;
Node node = document.selectSingleNode("//foo/bar");//获取foo节点下的第一个bar节点;
单斜杠是绝对路径即从根节点开始;
双斜杠是相对路径即从所有当前节点开始;
星号“*”表示选择所有由星号之前的路径所定位的元素;
例如:
/aa/bb/*表示选择所有路径依附于/aa/bb的元素;
/*/*/*/bbb表示选择所有的有3个祖先元素的bbb元素;
//bb[@*]表示选择有任意属性的bb元素;
//bb[not(@*)]表示选择没有属性的bb元素;
//bb[@id='b1']表示选择含有属性id='b1'的bb元素;

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
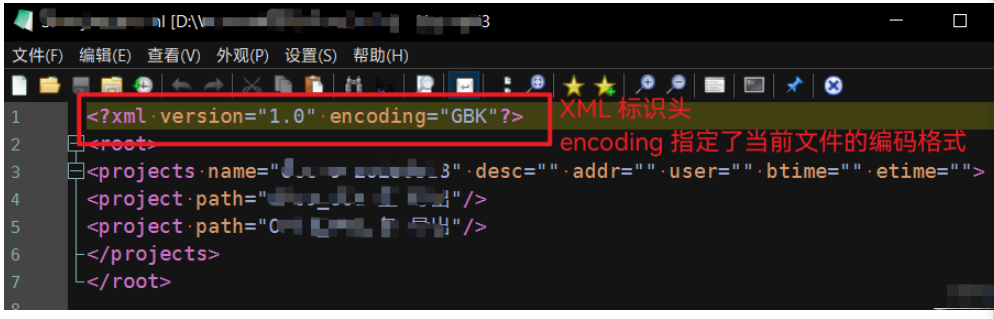 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

드림위버 CS6
시각적 웹 개발 도구

WebStorm Mac 버전
유용한 JavaScript 개발 도구

