


'통역 모드'란 무엇인가요?
먼저 "GOF"를 열고 정의를 살펴보세요.
언어가 주어지면 문법 표현을 정의하고 이 표현을 사용하여 언어의 문장을 해석하는 인터프리터를 정의합니다.
시작하기 전에 몇 가지 개념을 대중화해야 합니다.
추상 구문 트리:
통역사 모드에서는 추상 구문을 만드는 방법을 설명하지 않습니다. 나무. 구문 분석은 포함되지 않습니다. 추상 구문 트리는 테이블 기반 파서로 완성되거나, 손으로 직접 작성한(일반적으로 재귀 하강) 파서로 생성되거나, 클라이언트에서 직접 제공될 수 있습니다.
파서:
은 클라이언트 호출 요구 사항을 설명하는 표현식을 구문 분석하여 추상 구문 트리를 형성하는 프로그램을 의미합니다.
통역기:
은 추상 구문 트리를 해석하고 각 노드에 해당하는 기능을 실행하는 프로그램을 말합니다.
통역 모드를 사용하려면 문법이라고도 하는 일련의 문법 규칙을 정의하는 것이 중요한 전제 조건입니다. 이 문법의 규칙이 단순하든 복잡하든 상관없이 인터프리터 모드는 이러한 규칙에 따라 해당 기능을 구문 분석하고 수행하기 때문에 이러한 규칙이 있어야 합니다.
먼저 통역사 모드의 구조 다이어그램과 설명을 살펴보겠습니다.

AbstractExpression: 인터프리터의 인터페이스를 정의하고 인터프리터의 통역 작업에 동의합니다.
TerminalExpression: 터미널 인터프리터는 문법 규칙에서 터미널 기호와 관련된 작업을 구현하는 데 사용됩니다. 더 이상 다른 인터프리터를 포함하지 않고 추상 구문 트리를 구축하는 데 사용됩니다. 복합 모드의 리프 개체에는 여러 터미널 해석기가 있을 수 있습니다.
비터미널 표현: 문법 규칙에서 비터미널 기호와 관련된 작업을 구현하는 데 사용되는 비터미널 인터프리터입니다. 일반적으로 하나의 인터프리터는 문법 규칙에 해당하며 결합 모드를 사용하는 경우 다른 인터프리터를 포함할 수 있습니다. 추상 구문 트리에서는 조합 패턴의 조합 개체와 동일합니다. 비터미널 인터프리터가 여러 개 있을 수 있습니다.
컨텍스트: 컨텍스트에는 일반적으로 각 인터프리터에 필요한 데이터 또는 공용 기능이 포함됩니다.
클라이언트: 클라이언트는 인터프리터를 사용하는 클라이언트를 말합니다. 일반적으로 언어의 문법에 따라 만들어진 표현을 인터프리터 객체를 사용하여 기술된 추상 구문 트리로 변환한 후 설명합니다. 작업.
아래에서는 인터프리터 모드를 이해하기 위해 XML 예제를 사용합니다.
우선 표현식에 대한 간단한 문법을 설계해야 합니다. 보편성을 위해 루트 요소, abc 등을 나타냅니다. 요소를 표현하기 위한 간단한 xml은 다음과 같습니다.
& lt;? xml 버전 = "1.0"인코딩 "UTF-8"& gt; & lt; root id = "rootid"& gt; /c & gt; & gt; /d & gt;
🎜>
합의된 표현의 문법은 다음과 같습니다.
1. 단일 요소의 값을 가져옵니다. 루트 요소에서 시작하여 값을 가져오려는 요소로 이동합니다. 루트 요소 앞에 "/"를 추가하지 마세요. 예를 들어, "root/a/b/c"라는 표현은 루트 요소 아래의 a 요소, a 요소, b 요소, c 요소의 값을 얻는다는 의미입니다.
2. 단일 요소의 속성 값을 가져옵니다. 물론 값을 가져오는 속성은 마지막 요소 뒤에 "."를 추가해야 합니다. 그런 다음 속성의 이름을 추가합니다. 예를 들어, "root/a/b/c.name"이라는 표현은 루트 요소 아래에 있는 요소 a, 요소 b, 요소 c의 name 속성 값을 얻는다는 의미입니다.
3. 동일한 요소 이름의 값을 가져옵니다. 물론 값을 가져오는 요소는 표현식의 마지막 요소여야 하며, 마지막 요소 뒤에 "$"를 추가합니다. 예를 들어 "root/a/b/d$"라는 표현은 루트 요소 아래, a 요소 아래, b 요소 아래에 있는 여러 d 요소의 값 집합을 얻는다는 의미입니다.
4. 동일한 요소 이름을 가진 속성 값을 가져옵니다. 물론 요소가 여러 개 있습니다. 속성 값을 가져오는 요소는 표현식의 마지막 요소여야 하며 마지막 요소 뒤에 "$"를 추가합니다. 예를 들어, "root/a/b/d$.id$"라는 표현은 루트 요소 아래, a 요소 아래, b 요소 아래에 있는 여러 d 요소의 id 속성 값 집합을 얻는다는 의미입니다.
위 xml, 해당 추상 구문 트리, 가능한 구조는 그림과 같습니다.
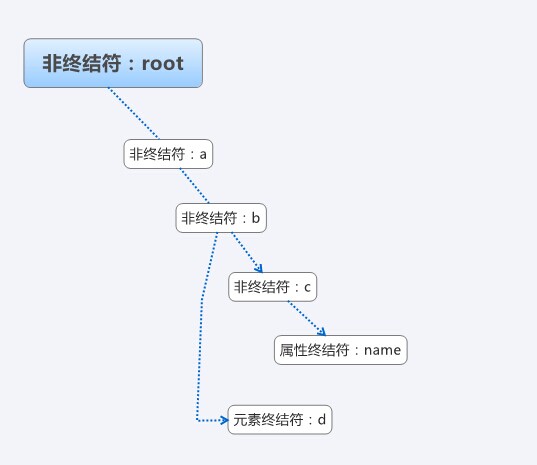
구체적인 코드를 살펴보겠습니다:
1. 컨텍스트 정의:
/**
* 인터프리터에 필요한 일부 전역 정보를 포함하는 데 사용되는 컨텍스트
* @param {String} filePathName [읽어야 하는 xml의 경로 및 이름]
*/
function Context(filePathName) {
// 이전에 처리된 요소
this.preEle = null;
// xml 문서 객체
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 컨텍스트 다시 초기화
reInit: function () {
this.preEle = null;
},
/**
* 다양한 표현식에서 공통적으로 사용되는 메소드
* 상위 요소 이름과 현재 요소를 기준으로 현재 요소 가져오기
* @param {Element} pEle [상위 요소]
* @param {String} eleName [현재 요소 이름]
* @return {Element|null} [현재 요소 발견]
*/
getNowEle: 함수(pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1)
if (nowEle .nodeName === eleName)
지금Ele ;
null 반환;
getPreEle: 함수() {
return this.preEle;
},
setPreEle: 함수(preEle) {
this.preEle = preEle;
},
getDocument: 함수 () {
return this.document;
}
};
// 도구 객체
// xml을 구문 분석하고 해당 Document 객체를 얻습니다.
var ;
var xmldom =parser.parseFromString('
xmldom 반환; ~
다음은 인터프리터 코드입니다.
코드 복사
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
해석: 함수(컨텍스트) {
var pEle = context.getPreEle();
var ele = null;
if(!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
요소의 값을 가져옵니다.
/**
* 터미널 기호로 속성에 해당하는 해석기
* @param {String} propName [속성 이름]
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
Interpret: function (context) {
// 마지막 요소 속성의 값을 직접 가져옵니다
}
};
먼저 단일 요소의 값을 얻기 위해 인터프리터를 사용하는 방법을 살펴보겠습니다.
코드 복사
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b' );
var cEle = new ElementTerminalExpression ('c');
// 조합
root.addEle(aEle);
aEle.addEle(bEle); bEle.addEle(cEle);
console.log('c의 값은 ' root.interpret(c));
}();
출력: c 값 = 12345
코드 복사
void function () {
var c = new Context();
// d 요소의 id 속성을 가져오려고 합니다. 이는 다음 표현식의 값입니다. "a/ b/c .name"
// c는 현재 종료되지 않았으므로 c를 ElementExpression
으로 수정해야 합니다. var root = new ElementExpression('root');
var aEle = new ElementExpression(' a');
var bEle = new ElementExpression('b');
var cEle = new ElementExpression('c');
var prop = new PropertyTerminalExpression('name');
// 조합
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('c의 속성 이름 값은 ' root.interpret(c));
// 동일한 컨텍스트를 연속 파싱에 사용하려면 컨텍스트 객체를 다시 초기화해야 합니다.
// 예를 들어 속성 이름, 물론 요소를 다시 결합할 수 있습니다.
// 다시 구문 분석합니다. 동일한 컨텍스트를 사용하는 한 컨텍스트 개체를 다시 초기화해야 합니다.
));
} ();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
인터프리터 객체가 문법 규칙을 담당하는 방식 때문에 새로운 문법을 확장하는 것이 매우 쉽습니다. 새로운 구문을 확장하려면 해당 인터프리터 객체를 생성하고 추상 구문 트리를 생성할 때 이 새로운 인터프리터 객체를 사용하기만 하면 됩니다.
단점:
복잡한 구문에는 적합하지 않습니다
문법이 특히 복잡한 경우 인터프리터 모드에 필요한 추상 구문 트리를 구축하는 작업이 매우 어렵고 여러 추상 구문 트리를 구축해야 할 수도 있습니다. 따라서 통역사 모드는 복잡한 문법에는 적합하지 않습니다. 파서나 컴파일러 생성기를 사용하는 것이 더 나을 수도 있습니다.
언제 사용하나요?
해석하고 실행해야 하는 언어가 있고, 해당 언어의 문장을 추상 구문 트리로 표현할 수 있는 경우에는 해석기 모드 사용을 고려해 볼 수 있습니다.
통역 모드를 사용할 때 고려해야 할 두 가지 특징이 있습니다. 하나는 구문이 상대적으로 단순해야 한다는 것입니다. 또 하나는 너무 책임감 있는 문법은 통역 모드를 사용하기에 적합하지 않다는 것입니다. 요구 사항이 그다지 높지 않아 사용하기에 적합하지 않습니다.
이전 글에서는 단일 요소의 값과 단일 요소 속성의 값을 구하는 방법에 대해 소개했습니다. 이전 테스트뿐만 아니라 여러 요소를 인위적으로 조립한 추상 구문 트리의 경우 이전에 정의된 문법을 준수하는 표현식을 이전에 구현된 인터프리터의 추상 구문 트리로 변환하기 위해 다음과 같은 간단한 구문 분석기도 구현했습니다. 직접:
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
ele = ele.replace(DOLLAR, '');
mapPath[ele] = pm;
listEle.push(ele);
}
// 두 번째 단계를 깨닫기 시작합니다 -------------------------- -

 JavaScript 댓글 : / / * * /사용 안내서May 13, 2025 pm 03:49 PM
JavaScript 댓글 : / / * * /사용 안내서May 13, 2025 pm 03:49 PMjavaScriptUSTWOTYPESOFSOFCOMMENTS : 단일 라인 (//) 및 multi-line (//)
 Python vs. JavaScript : 개발자를위한 비교 분석May 09, 2025 am 12:22 AM
Python vs. JavaScript : 개발자를위한 비교 분석May 09, 2025 am 12:22 AMPython과 JavaScript의 주요 차이점은 유형 시스템 및 응용 프로그램 시나리오입니다. 1. Python은 과학 컴퓨팅 및 데이터 분석에 적합한 동적 유형을 사용합니다. 2. JavaScript는 약한 유형을 채택하며 프론트 엔드 및 풀 스택 개발에 널리 사용됩니다. 두 사람은 비동기 프로그래밍 및 성능 최적화에서 고유 한 장점을 가지고 있으며 선택할 때 프로젝트 요구 사항에 따라 결정해야합니다.
 Python vs. JavaScript : 작업에 적합한 도구 선택May 08, 2025 am 12:10 AM
Python vs. JavaScript : 작업에 적합한 도구 선택May 08, 2025 am 12:10 AMPython 또는 JavaScript를 선택할지 여부는 프로젝트 유형에 따라 다릅니다. 1) 데이터 과학 및 자동화 작업을 위해 Python을 선택하십시오. 2) 프론트 엔드 및 풀 스택 개발을 위해 JavaScript를 선택하십시오. Python은 데이터 처리 및 자동화 분야에서 강력한 라이브러리에 선호되는 반면 JavaScript는 웹 상호 작용 및 전체 스택 개발의 장점에 없어서는 안될 필수입니다.
 파이썬 및 자바 스크립트 : 각각의 강점을 이해합니다May 06, 2025 am 12:15 AM
파이썬 및 자바 스크립트 : 각각의 강점을 이해합니다May 06, 2025 am 12:15 AM파이썬과 자바 스크립트는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구와 개인 선호도에 따라 다릅니다. 1. Python은 간결한 구문으로 데이터 과학 및 백엔드 개발에 적합하지만 실행 속도가 느립니다. 2. JavaScript는 프론트 엔드 개발의 모든 곳에 있으며 강력한 비동기 프로그래밍 기능을 가지고 있습니다. node.js는 풀 스택 개발에 적합하지만 구문은 복잡하고 오류가 발생할 수 있습니다.
 JavaScript의 핵심 : C 또는 C에 구축 되었습니까?May 05, 2025 am 12:07 AM
JavaScript의 핵심 : C 또는 C에 구축 되었습니까?May 05, 2025 am 12:07 AMjavaScriptisNotBuiltoncorc; it'SangretedLanguageThatrunsonOngineStenWrittenInc .1) javaScriptWasDesignEdasAlightweight, 해석 hanguageforwebbrowsers.2) Endinesevolvedfromsimpleplemporectreterstoccilpilers, 전기적으로 개선된다.
 JavaScript 응용 프로그램 : 프론트 엔드에서 백엔드까지May 04, 2025 am 12:12 AM
JavaScript 응용 프로그램 : 프론트 엔드에서 백엔드까지May 04, 2025 am 12:12 AMJavaScript는 프론트 엔드 및 백엔드 개발에 사용할 수 있습니다. 프론트 엔드는 DOM 작업을 통해 사용자 경험을 향상시키고 백엔드는 Node.js를 통해 서버 작업을 처리합니다. 1. 프론트 엔드 예 : 웹 페이지 텍스트의 내용을 변경하십시오. 2. 백엔드 예제 : node.js 서버를 만듭니다.
 Python vs. JavaScript : 어떤 언어를 배워야합니까?May 03, 2025 am 12:10 AM
Python vs. JavaScript : 어떤 언어를 배워야합니까?May 03, 2025 am 12:10 AMPython 또는 JavaScript는 경력 개발, 학습 곡선 및 생태계를 기반으로해야합니다. 1) 경력 개발 : Python은 데이터 과학 및 백엔드 개발에 적합한 반면 JavaScript는 프론트 엔드 및 풀 스택 개발에 적합합니다. 2) 학습 곡선 : Python 구문은 간결하며 초보자에게 적합합니다. JavaScript Syntax는 유연합니다. 3) 생태계 : Python에는 풍부한 과학 컴퓨팅 라이브러리가 있으며 JavaScript는 강력한 프론트 엔드 프레임 워크를 가지고 있습니다.
 JavaScript 프레임 워크 : 현대적인 웹 개발 파워May 02, 2025 am 12:04 AM
JavaScript 프레임 워크 : 현대적인 웹 개발 파워May 02, 2025 am 12:04 AMJavaScript 프레임 워크의 힘은 개발 단순화, 사용자 경험 및 응용 프로그램 성능을 향상시키는 데 있습니다. 프레임 워크를 선택할 때 : 1. 프로젝트 규모와 복잡성, 2. 팀 경험, 3. 생태계 및 커뮤니티 지원.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

