


【原文:http://www.cnblogs.com/mikewolf2002/p/3474188.html】 前面一篇文章中提到,我们在一副脸部图像上选取76个特征点来描述脸部形状特征,本文中我们会把这些特征点映射到一个标准形状模型。 通常,脸部形状特征点能够参数化分解为两个变量,一个是全
【原文:http://www.cnblogs.com/mikewolf2002/p/3474188.html】
前面一篇文章中提到,我们在一副脸部图像上选取76个特征点来描述脸部形状特征,本文中我们会把这些特征点映射到一个标准形状模型。
通常,脸部形状特征点能够参数化分解为两个变量,一个是全局的刚体变化,一个是局部的变形。全局的刚体变化主要是指脸部能够在图像中移动,旋转,缩放,局部的变形则是指脸部的表情变化,不同人脸的特征等等。
形状模型类主要成员如下:
class shape_model
{ //2d linear shape model
public:
Mat p; //parameter vector (kx1) CV_32F,参数向量
Mat V; //shape basis (2nxk) CV_32F, line subspace,线性子空间
Mat e; //parameter variance (kx1) CV_32F 参数方差
Mat C; //connectivity (cx2) CV_32S 连通性
//把一个点集投影到一个可信的脸部形状空间
void calc_params(const vector
const Mat weight = Mat(), //weight of each point (nx1) CV_32F 点集的权重
const float c_factor = 3.0); //clamping factor
//该函数用人脸模型V和e,把向量p转化为点集
vector
...
void train(const vector
const vector
const float frac = 0.95, //fraction of variation to retain
const int kmax = 10); //maximum number of modes to retain
...
}
本文中,我们通过Procrustes analysis来处理特征点,移去全局刚性变化,Procrustes analysis算法可以参考:http://en.wikipedia.org/wiki/Procrustes_analysis
在数学上,Procruster analysis就是寻找一个标准形状,然后把所有其它特征点数据都和标准形状对齐,对齐的时候采用最小平方距离,用迭代的方法不断逼近。下面通过代码来了解如何实现Procrustes analysis。
//Procrustes分析的基本思想是最小化所有形状到平均形状的距离和
Mat shape_model::procrustes(const Mat &X,
const int itol, //最大迭代次数
const float ftol //精度
)
{
X矩阵就是多副样本图像76个特征点组成的矩阵,共152行,列数为图像的个数,每列表示一个样本图像特征点的x,y坐标。
int N = X.cols,n = X.rows/2;
//remove centre of mass
//所有的形状向量(特征)对齐到原点,即每个向量的分量减去其平均值,每列是一个形状向量。
Mat P = X.clone();
for(int i = 0; i
{
Mat p = P.col(i); //第i个向量
float mx = 0,my = 0;
for(int j = 0; j //x,y分别计算得到平均值。
{
mx += p.fl(2*j);
my += p.fl(2*j+1);
}
mx /= n; my /= n;
for(int j = 0; j
{
p.fl(2*j) -= mx;
p.fl(2*j+1) -= my;
}
}
//optimise scale and rotation
Mat C_old;
for(int iter = 0; iter
{
注意下边的一行代码,会把每个图像对齐到原点特征点x,y分别加起来,求平均值,得到一个152*1的矩阵,然后对该矩阵进行归一化处理。
Mat C = P*Mat::ones(N,1,CV_32F)/N; //计算形状变换后的平均值
normalize(C,C); //canonical shape (对x-进行标准化处理)
if(iter > 0) //converged?//收敛?当两个标准形状或者标准形状的误差小于某一值这里是ftol则,停止迭代。
{
norm函数默认是矩阵各元素平方和的根范式
if(norm(C,C_old)
break;
}
C_old = C.clone(); //remember current estimate//记下当前的矩阵,和下一次进行比较
for(int i = 0; i
{
rot_scale_align函数求每副图像的特征点向量和平均向量满足最小乘法时候的旋转矩阵。即求得a,b值组成的旋转矩阵。


该函数的代码:
Mat shape_model::rot_scale_align(<span>const</span> Mat &src, <span>const</span> Mat &dst)
{
<span>//construct linear system</span>
<span>int</span> n = src.rows/2;
<span>float</span> a=0,b=0,d=0;
<span>for</span>(<span>int</span> i = 0; i //x*x+y*y
a += src.fl(2*i) * dst.fl(2*i ) + src.fl(2*i+1) * dst.fl(2*i+1);
b += src.fl(2*i) * dst.fl(2*i+1) - src.fl(2*i+1) * dst.fl(2*i );
}
a /= d;
b /= d;
<span>//solved linear system</span>
<span>return</span> (Mat_float>(2,2)
<br>
<br>
Mat R = this->rot_scale_align(P.col(i),C); <span>//求两个形状之间的误差满足最小二乘时的旋转矩阵。即相当于两个形状"最靠近"时,需要的旋转的仿射矩阵 <br>
</span> for(int j = 0; j
{ <span>//apply similarity transform//应用相似变换,这对形状中的每一个点,应用仿射矩阵。 变化后,该特征点向量会靠近平均特征向量。之后经过反复迭代,直到平均向量和上次比较变化很小时,退出迭代。 <br>
</span> float x = P.fl(2*j,i),y = P.fl(2*j+1,i); <br>
P.fl(2*j ,i) = R.fl(0,0)*x + R.fl(0,1)*y; <br>
P.fl(2*j+1,i) = R.fl(1,0)*x + R.fl(1,1)*y; <br>
} <br>
} <br>
} <br>
return P; <br>
} <br>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
<span> 通过<span>Procrustes analysis对齐的特征向量,我们要用一个统一的矩阵把平移和旋转统一起来表示<span>(成为线性表示),</span>然后把该矩阵追加到局部变形空间,注意对该矩阵表示,我们最后进行了史密斯正交处理。</span></span></p>
<p>
<img src="/static/imghwm/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fimages.cnitblog.com%2Fblog%2F361409%2F201312%2F14113411-9fdaefb021b14f52a72d2e3dae833c22.png&refer=http%3A%2F%2Fblog.csdn.net%2Fzhazhiqiang%2Farticle%2Fdetails%2F20158453" class="lazy" alt="OpenCV 脸部跟踪(2)" ></p>
<p>
<span>我们通过函数 calc_rigid_basis得到该矩阵表示:</span></p>
<p>
<span>Mat shape_model::calc_rigid_basis(const Mat &X) <br>
{ <br>
<span>//compute mean shape</span> <br>
int N = X.cols,n = X.rows/2; <br>
Mat mean = X*Mat::ones(N,1,CV_32F)/N;</span></p>
<p>
<span> <span>//construct basis for similarity transform <br>
</span> Mat R(2*n,4,CV_32F); <br>
for(int i = 0; i
{ <br>
R.fl(2*i,0) = mean.fl(2*i ); <br>
R.fl(2*i+1,0) = mean.fl(2*i+1); <br>
R.fl(2*i,1) = -mean.fl(2*i+1); <br>
R.fl(2*i+1,1) = mean.fl(2*i ); <br>
R.fl(2*i,2) = 1.0; <br>
R.fl(2*i+1,2) = 0.0; <br>
R.fl(2*i,3) = 0.0; <br>
R.fl(2*i+1,3) = 1.0; <br>
} <br>
<span>//Gram-Schmidt orthonormalization <br>
</span> for(int i = 0; i
{ <br>
Mat r = R.col(i); <br>
for(int j = 0; j
{ <br>
Mat b = R.col(j); <br>
r -= b*(b.t()*r); <br>
} <br>
normalize(r,r); <br>
} <br>
return R; <br>
}</span></p>
<p>
</p>
<p>
<span>下面我们看看train函数的实现:</span></p>
<p>
<span>两篇参考的翻译:http://blog.csdn.net/raby_gyl/article/details/13148193</span></p>
<p>
<span>http://blog.csdn.net/raby_gyl/article/details/13024867</span></p>
<p>
</p>
<p>
<span> 该函数的输入为n个样本图像的采样特征点,该点集会被首先转化为行152,列为样本数量的矩阵表示,另外还有连通性点集索引,以及方差的置信区间以及保留模型的最大数量。</span></p>
<p>
<span>void train(const vector<vector> > &p, <span>//N-example shapes</span> <br>
const vector<vec2i> &con = vector<vec2i>(), <span>//point-connectivity <br>
</span> const float frac = 0.95, <span>//fraction of variation to retain <br>
</span> const int kmax = 10) <span>//maximum number of modes to retain <br>
</span> { <br>
<span>//vectorize points</span> <br>
Mat X = this->pts2mat(points);</vec2i></vec2i></vector></span></p>
<p>
<span><span>N是样本的数目,n是76,表示76个特征点。 <br>
</span> int N = X.cols,n = X.rows/2;</span></p>
<p>
<span> <span>//align shapes <br>
</span> Mat Y = this->procrustes(X);</span></p>
<p>
<span> <span>//compute rigid transformation</span> <span>计算得到刚体变化矩阵R <br>
</span> Mat R = this->calc_rigid_basis(Y);</span></p>
<p>
<span> 脸部局部变形我们用一个线性模型表示,主要的思想如下图所示:一个有N个面部特征组成面部形状,被建模成一个2N维空间的点。我们要尽量找到一个低维的超平面,在这个平面内,所有的面部形状都在里面,由于这个超平面只是2N维空间的子集,占用刚少的空间,处理起来更快。可以想得到,如果这个子空间来自于一个人,则子空间的点,表现这个人的各种表情变化。前面的教程中,我们知道PCA算法能够找到低维子空间,但PCA算法需要指定子空间的维数,在启发式算法中有时候这个值很难选择。在本程序中,我们通过SVD算法来模拟PCA算法。</span></p>
<p>
</p>
<p>
<img src="/static/imghwm/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fimages.cnitblog.com%2Fblog%2F361409%2F201312%2F15192025-1229008c4629424d8379873e5a6e517b.png&refer=http%3A%2F%2Fblog.csdn.net%2Fzhazhiqiang%2Farticle%2Fdetails%2F20158453" class="lazy" alt="OpenCV 脸部跟踪(2)" ></p>
<p>
</p>
<p>
<span> <span>//compute non-rigid transformation</span> </span></p>
<p>
<span><span>Y是152*1294的矩阵,它是procrustes分析的结果,R是刚体变化矩阵152*4,它的转置就是4*152 <br>
</span> Mat P = R.t()*Y; <span>//原始的位置 <br>
</span> <span>Mat dY = Y - R*P; </span><span>//</span><span>dy变量的每一列表示减去均值的Procrustes对齐形状,<span>投影刚体运动</span></span></span></p>
<p>
<span> 奇异值分解SVD有效的应用到形状数据的<span>协方差矩阵</span>(即,dY.t()*dY),OpenCV的SVD类的w成员存储着数据变化性的主要方向的变量,从最大到最小排序。一个选择子空间维数的普通方法是选择保存数据总能量分数frac的方向最小集(即占总能量的比例为frac),这是通过svd.w记录表示的,因为这些记录是从最大的到最小的排序的,它充分地用来评估子空间,通过用变化性方向的最大值k来评估能量。他们自己的方向存储在SVD类的u成员内。svd.w和svd.u成分一般分别被成为特征值和特征矢量。</span><span><span> <br>
</span><span> SVD svd(dY*dY.t()); <br>
int m = min(min(kmax,N-1),n-1); <br>
float vsum = 0; <br>
for(int i = 0; i
vsum += svd.w.fl(i); <br>
float v = 0; <br>
int k = 0;</span></span></p>
<p>
<span><span><span>达到了95%的主成分量,退出,frac=0.95</span> <br>
for(k = 0; k
{ <br>
v += svd.w.fl(k); <br>
if(v/vsum >= frac){k++; break;} <br>
} <br>
if(k > m) k = m;</span></span></p>
<p>
<span><span><span>取前k个特征向量 <br>
</span> <span>Mat D = svd.u(Rect(0,0,k,2*n));</span></span></span></p>
<p>
<span><span>把全局刚体运动和局部变形运动结合起来,注意V的第一列是缩放,第三、四列分别是x,y偏移。</span></span></p>
<p>
<span>//combine bases <br>
V.create(2*n,4+k,CV_32F); <br>
Mat Vr = V(Rect(0,0,4,2*n)); <span>//刚体子空间 <br>
</span> R.copyTo(Vr); <span>//非刚体子空间</span> <br>
Mat Vd = V(Rect(4,0,k,2*n)); <br>
D.copyTo(Vd);</span></p>
<p>
<span> 最后我们要注意的一点是如何约束子空间坐标,以使得子空间内的面部形状都是有效的。在下面的图中,我们可以看到,对于子空间内的图像,如果在某个方向改变坐标值,当坐标值小时候,它仍是一个脸的形状,但是变化值大时候,就不知道是什么玩意了。防止出现这种情况的最简单方法,就是把变化的值clamp在一个范围内,通常是现在± 3 的范围,这样可以cover到99.7%的脸部变化。clamping的值通过下面的代码计算:</span></p>
<p>
</p>
<p>
<img src="/static/imghwm/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fimages.cnitblog.com%2Fblog%2F361409%2F201312%2F15192029-199dc6314d9e4c14bbf7fe4b35f098c0.png&refer=http%3A%2F%2Fblog.csdn.net%2Fzhazhiqiang%2Farticle%2Fdetails%2F20158453" class="lazy" alt="OpenCV 脸部跟踪(2)" ></p>
<p>
<span> <span> //compute variance (normalized wrt scale)</span> </span></p>
<p>
<span><br>
<span>Mat Q = V.t()*X; </span><span>//把数据投影到子空间 <br>
</span> for(int i = 0; i //normalize coordinates w.r.t scale <br>
</span> { <span>//用第一个坐标缩放,防止太大的缩放值影响脸部识别 <br>
</span> float v = Q.fl(0,i); <br>
Mat q = Q.col(i); <br>
q /= v; <br>
} <br>
e.create(4+k,1,CV_32F); <br>
pow(Q,2,Q); <br>
for(int i = 0; i
{ <br>
if(i
e.fl(i) = -1; <span>//no clamping for rigid coefficients <br>
</span> else <br>
e.fl(i) = Q.row(i).dot(Mat::ones(1,N,CV_32F))/(N-1); <br>
} <br>
<span>//store connectivity <br>
</span> if(con.size() > 0) <br>
{ //default connectivity <br>
int m = con.size(); <br>
C.create(m,2,CV_32F); <br>
for(int i = 0; i
{ <br>
C.at<int>(i,0) = con[i][0]; <br>
C.at<int>(i,1) = con[i][1]; <br>
} <br>
} <br>
else <br>
{ //user-specified connectivity <br>
C.create(n,2,CV_32S); <br>
for(int i = 0; i
{ <br>
C.at<int>(i,0) = i; C.at<int>(i,1) = i+1; <br>
} <br>
C.at<int>(n-1,0) = n-1; C.at<int>(n-1,1) = 0; <br>
} <br>
}</int></int></int></int></int></int></p>
<p>
</p>
<p>
<span>工程文件:FirstOpenCV40,</span></p>
<p>
<span>程序的运行参数为:annotations.yaml shapemodle.yaml</span></p>
<p>
<span>程序执行后,可以看到我们只保留了14个模型。</span></p>
<p>
<img src="/static/imghwm/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fimages.cnitblog.com%2Fblog%2F361409%2F201312%2F14113419-908c110a67d3464abcd452edcc027668.png&refer=http%3A%2F%2Fblog.csdn.net%2Fzhazhiqiang%2Farticle%2Fdetails%2F20158453" class="lazy" alt="OpenCV 脸部跟踪(2)" ></p>
<p>
<span>我们也可以使用下面的运行参数:annotations.yaml shapemodle.yaml –mirror</span></p>
<p>
<span>这时候,每副图像的特征点,会生成一个y轴对称的镜像特征点集,这时训练的采样数目翻倍,为5828。</span></p>
<p>
<span>在工程文件FirstOpenCV41中,我们可视化了生成的模型,会连续显示14个模型的不同姿态:</span></p>
<p>
<img src="/static/imghwm/default1.png" data-src="/inc/test.jsp?url=http%3A%2F%2Fimages.cnitblog.com%2Fblog%2F361409%2F201312%2F14113424-ac033ab541ca4a349466840ce5b41628.png&refer=http%3A%2F%2Fblog.csdn.net%2Fzhazhiqiang%2Farticle%2Fdetails%2F20158453" class="lazy" alt="OpenCV 脸部跟踪(2)" ></p>

 python OpenCV图像金字塔实例分析May 11, 2023 pm 08:40 PM
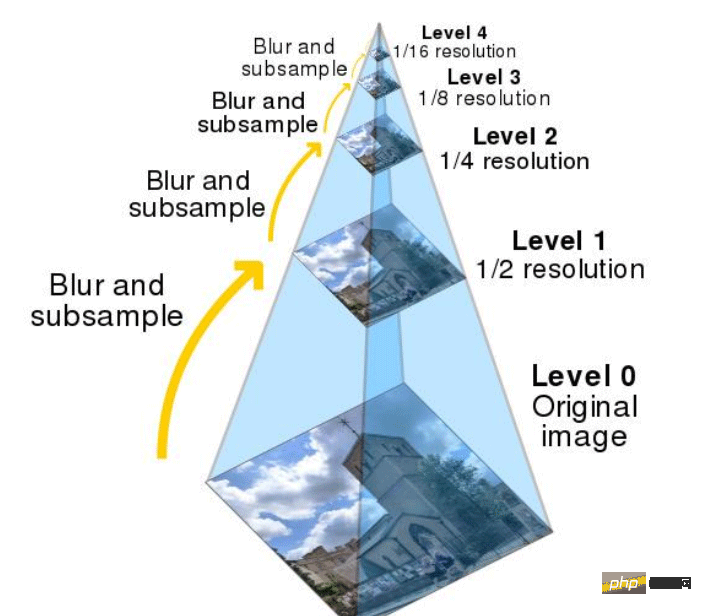
python OpenCV图像金字塔实例分析May 11, 2023 pm 08:40 PM1.图像金字塔理论基础图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。那我们为什么要做图像金字塔呢?这就是因为改变像素大小有时候并不会改变它的特征,比方说给你看1000万像素的图片,你能知道里面有个人,给你看十万像素的,你也能知道里面有个人,但是对计
 Python+OpenCV怎么实现拖拽虚拟方块效果May 15, 2023 pm 07:22 PM
Python+OpenCV怎么实现拖拽虚拟方块效果May 15, 2023 pm 07:22 PM一、项目效果二、核心流程1、openCV读取视频流、在每一帧图片上画一个矩形。2、使用mediapipe获取手指关键点坐标。3、根据手指坐标位置和矩形的坐标位置,判断手指点是否在矩形上,如果在则矩形跟随手指移动。三、代码流程环境准备:python:3.8.8opencv:4.2.0.32mediapipe:0.8.10.1注:1、opencv版本过高或过低可能出现一些如摄像头打不开、闪退等问题,python版本影响opencv可选择的版本。2、pipinstallmediapipe后可能导致op
 如何使用PHP和OpenCV库实现视频处理?Jul 17, 2023 pm 09:13 PM
如何使用PHP和OpenCV库实现视频处理?Jul 17, 2023 pm 09:13 PM如何使用PHP和OpenCV库实现视频处理?摘要:在现代科技应用中,视频处理已经成为一项重要的技术。本文将介绍如何使用PHP编程语言结合OpenCV库来实现一些基本的视频处理功能,并附上相应的代码示例。关键词:PHP、OpenCV、视频处理、代码示例引言:随着互联网的发展和智能手机的普及,视频内容已经成为人们生活中不可或缺的一部分。然而,要想实现视频的编辑和
 在PHP中使用OpenCV实现计算机视觉应用Jun 19, 2023 pm 03:09 PM
在PHP中使用OpenCV实现计算机视觉应用Jun 19, 2023 pm 03:09 PM计算机视觉(ComputerVision)是人工智能领域的重要分支之一,它可以使计算机能够自动地感知和理解图像、视频等视觉信号,实现人机交互以及自动化控制等应用场景。OpenCV(OpenSourceComputerVisionLibrary)是一个流行的开源计算机视觉库,在计算机视觉、机器学习、深度学习等领域都有广泛的应用。本文将介绍在PHP中使
 在Python中,可以使用OpenCV库中的方法对图像进行分割和提取。May 08, 2023 pm 10:55 PM
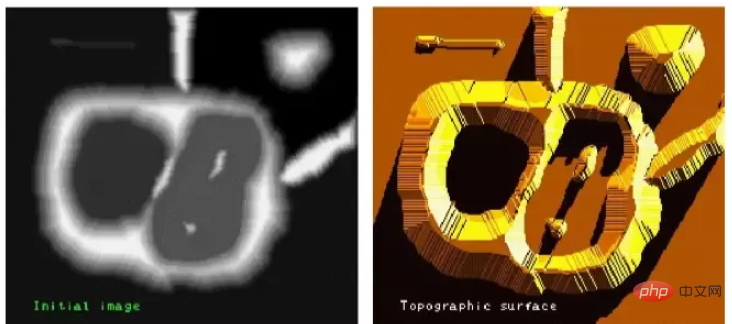
在Python中,可以使用OpenCV库中的方法对图像进行分割和提取。May 08, 2023 pm 10:55 PM图像分割与提取图像中将前景对象作为目标图像分割或者提取出来。对背景本身并无兴趣分水岭算法及GrabCut算法对图像进行分割及提取。用分水岭算法实现图像分割与提取分水岭算法将图像形象地比喻为地理学上的地形表面,实现图像分割,该算法非常有效。算法原理任何一幅灰度图像,都可以被看作是地理学上的地形表面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。左图是原始图像,右图是其对应的“地形表面”。该过程将图像分成两个不同的集合:集水盆地和分水岭线。我们构建的堤坝就是分水岭线,也即对原始图像
 如何使用PHP和OpenCV库实现图像锐化?Jul 17, 2023 am 08:31 AM
如何使用PHP和OpenCV库实现图像锐化?Jul 17, 2023 am 08:31 AM如何使用PHP和OpenCV库实现图像锐化?概述:图像锐化是一种常见的图像处理技术,用于提高图像的清晰度和边缘的强度。在本文中,我们将介绍如何使用PHP和OpenCV库来实现图像锐化。OpenCV是一款功能强大的开源计算机视觉库,它提供了丰富的图像处理功能。我们将使用OpenCV的PHP扩展来实现图像锐化算法。步骤1:安装OpenCV和PHP扩展首先,我们需
 利用Java、Selenium和OpenCV结合的方法,解决自动化测试中滑块验证问题。May 08, 2023 pm 08:16 PM
利用Java、Selenium和OpenCV结合的方法,解决自动化测试中滑块验证问题。May 08, 2023 pm 08:16 PM1、滑块验证思路被测对象的滑块对象长这个样子。相对而言是比较简单的一种形式,需要将左侧的拼图通过下方的滑块进行拖动,嵌入到右侧空槽中,即完成验证。要自动化完成这个验证过程,关键点就在于确定滑块滑动的距离。根据上面的分析,验证的关键点在于确定滑块滑动的距离。但是看似简单的一个需求,完成起来却并不简单。如果使用自然逻辑来分析这个过程,可以拆解如下:1.定位到左侧拼图所在的位置,由于拼图的形状和大小固定,那么其实只需要定位其左边边界离背景图片的左侧距离。(实际在本例中,拼图的起始位置也是固定的,节省了
 利用PHP和OpenCV库进行图像霍夫变换的方法Jul 17, 2023 pm 08:53 PM
利用PHP和OpenCV库进行图像霍夫变换的方法Jul 17, 2023 pm 08:53 PM利用PHP和OpenCV库进行图像霍夫变换的方法引言:图像处理在计算机视觉和图像分析领域中发挥着重要的作用。其中,霍夫变换是一种广泛应用于边缘检测、直线检测和圆检测等场景的技术。本文将介绍如何使用PHP和OpenCV库进行图像霍夫变换,并附上代码示例。一、准备工作下载安装OpenCV库首先,我们需要在本地环境中安装OpenCV库。你可以从OpenCV官方网站


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

WebStorm Mac 버전
유용한 JavaScript 개발 도구

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

