
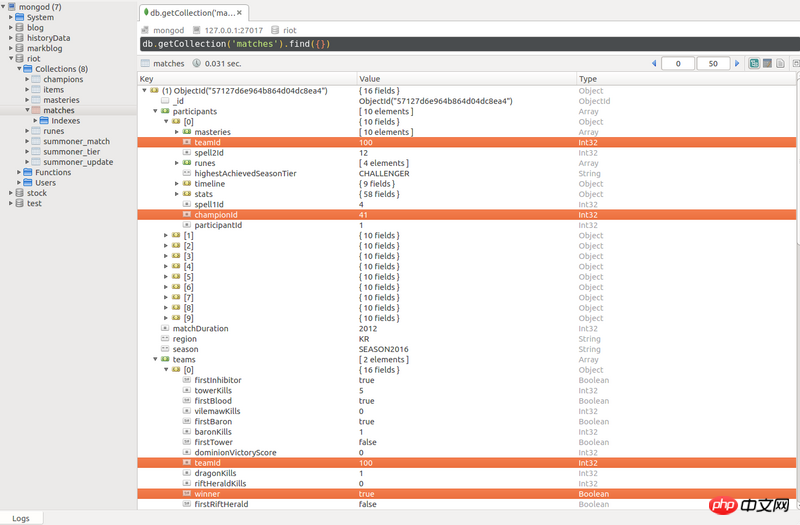
图为mongodb中一条document结构,记录的是LOL的一场比赛对局详情
participants中有10个玩家,前5个teamID为100,后5个teamId为200.比赛的结果哪个队伍取胜是记录在teams那个子文档中的。
我现在的想要查询championId为64(盲僧), 157(亚索)这两个英雄在同一个队伍时的胜利场次,(规定游戏版本号>6.7),查询语句我是这样写的:
db.getCollection('matches').count({
$and: [
{ "matchVersion": {$gte:"6.7"} }
, {
$or:
[
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 100, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 100, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 100, "winner":true} } }
]
},
{
$and:
[
{ "participants": {$elemMatch: {"teamId": 200, "championId": 64 } } }
, { "participants": {$elemMatch: {"teamId": 200, "championId": 157 } } }
, { "teams":{ $elemMatch: {"teamId": 200, "winner":true} } }
]
}
]
}
]
}
)数据规模为14万,可是执行这样一个查询要花费3秒。已经对对应的查询建立了索引。对查询explain的结果如下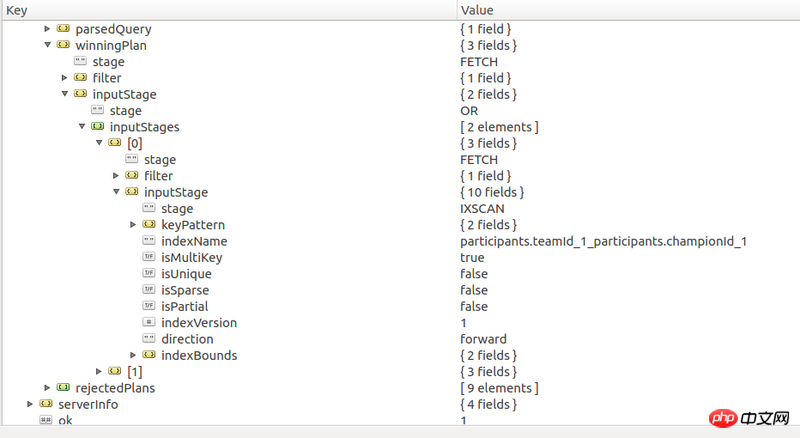
不过好像有些索引也没有用到,比如teams.teamId, teams.winner的复合索引,matchVersion的索引
请问这个查询该如何优化呢?我觉得这个数据规模花费这么久时间应该是我的使用姿势不对吧?
淡淡烟草味2017-05-02 09:20:33
実行計画インデックスが使用されていますが、効率的ではないことがわかりますが、多くの重要な情報が折り畳まれており、詳細が見えません。次回からは元の JSON を直接送信した方がわかりやすいでしょう。同様に、データ サンプルがある場合は、それを JSON で送信することをお勧めします。これにより、問題を解決するときに他の人がテスト データのコピーを入手できるため、はるかに便利になります。 $and これは、オブジェクト内の 2 つの並列要素は、and 間の関係であるため、ほとんどの場合出現する必要はありません。これによりクエリ構造が簡素化され、他の人が見やすくなります。したがって、クエリは次のように単純化されました: $and这个东西大部分时候是不用出现的,一个对象中的两个并列的元素就是与的关系。这样可以简化你的查询结构,别人看起来也轻松些。所以对你的查询做了简化,如下:
db.getCollection('matches').count({
"matchVersion": {$gte: "6.7"},
$or: [{
"participants": {$elemMatch: {"teamId": 100, "championId": 64}},
"participants": {$elemMatch: {"teamId": 100, "championId": 157}},
"teams": {$elemMatch: {"teamId": 100, "winner": true}}
}, {
"participants": {$elemMatch: {"teamId": 200, "championId": 64}},
"participants": {$elemMatch: {"teamId": 200, "championId": 157}},
"teams": {$elemMatch: {"teamId": 200,"winner": true}}
}]
})最后最关键的索引问题,推测对你更有用的索引应该是participants.teamId+participants.championId+teams.teamId+teams.winner+matchVersion
リーリー
最後で最も重要なインデックスの問題は、より役立つインデックスは participants.teamId+participants.championId+teams であるべきだと推測されることです。 .teamId+ teams.winner+matchVersion の結合インデックスでは、条件のフィルター可能性に従って、フィルター可能性の高い条件を最初に配置する必要があります。書き込み効率を向上させるために、いくつかの条件を削除することもできます。ただし、それはデータの分布によって異なります。