
最近想用Python写个爬虫去抓取一些东西,但是碰到个问题,就是验证码不知道该如何处理。
现在验证码一般有两种,一种是简单的,比如下面这种纯字符型的:
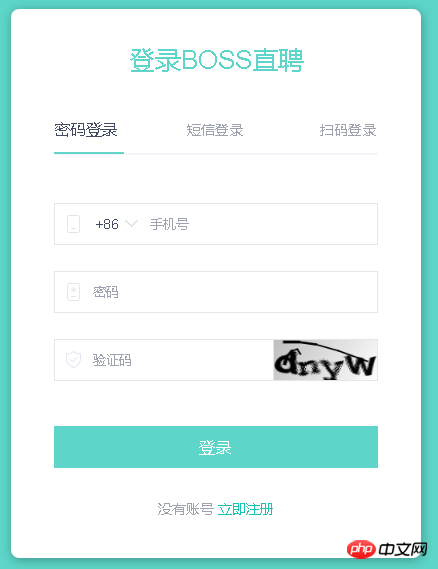
另外一种就是出来一些特定字符,需要按顺序点击的: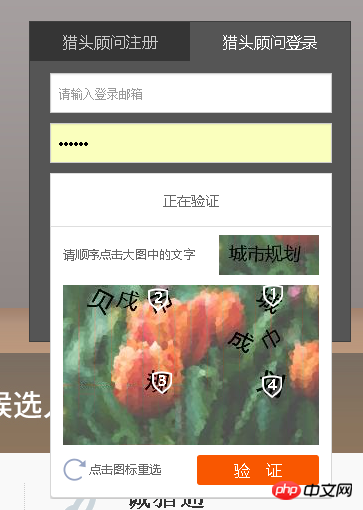
我看有的人说可以获取浏览器cookies写到程序里就直接通过验证了,有的说这个涉及到机器学习方面的东西。由于我个人以前没接触过这方面东西,所以不知道从何处入手,想问下要处理这种验证码的话,一般该如何处理? 有没有这方面合适的书推荐下啊……

迷茫2017-04-18 10:35:47
これ自体は、クローラーなどのネットワークプログラムを防ぐために認証コード技術を使用しています。私が知っているのは、人工知能の画像認識を使用することです。しかし、精度はあまり高くありません。

黄舟2017-04-18 10:35:47
検証コードの問題については、まず、Youyoutu などの専門サービス プロバイダー (機械学習または人工知能を使用) が提供する API を利用できます。次に、独自の検証コード認識プログラムを作成し、参照用のプロジェクトを提供します。 : https://github.com/luyishisi/...

PHPz2017-04-18 10:35:47
画像 1 は処理が簡単で、認証コードは単なる画像であり、画像処理 (ocr 技術) によって認証コードを取得できます。
画像 2 は、最初の方法を使用すると、その番号が重ねて表示されます。 2番目の方法は難しいので、この分野の経験のある学生が答えてくれると嬉しいです。

天蓬老师2017-04-18 10:35:47
検証コードはマシンやクローラに対抗するために使用されます。検証コードが自動クローラによって簡単に回避できる場合でも、作成者はまず検証コードのメカニズムを調べてから行う必要があります。つまり、他の Web サイトの検証コードの実装に抜け穴がない限り、検証コードのテキストを認識することしかできません。この問題を解決するために使用されるのが OCR (光学式文字認識) 技術です。 OCR とは、電子デバイス (スキャナーなど) が紙に印刷された文字を検査し、暗さを検出してその形状を判断するプロセスを指します。 /light パターンを作成し、文字認識方法を使用して形状をコンピューター テキストに変換します
検証コード認識の基本手順:
1. 前処理
2. 2 値化
4. ノイズ除去
6.
要するに認証コードの識別閾値が高くてコストが高いので仕方ないのですが
例えば下の写真では認証コードが千鳥状に重なっていて識別が困難です


