
爬取了一个用户的论坛数据,但是这个数据库中有重复的数据,于是我想把重复的数据项给去掉。数据库的结构如下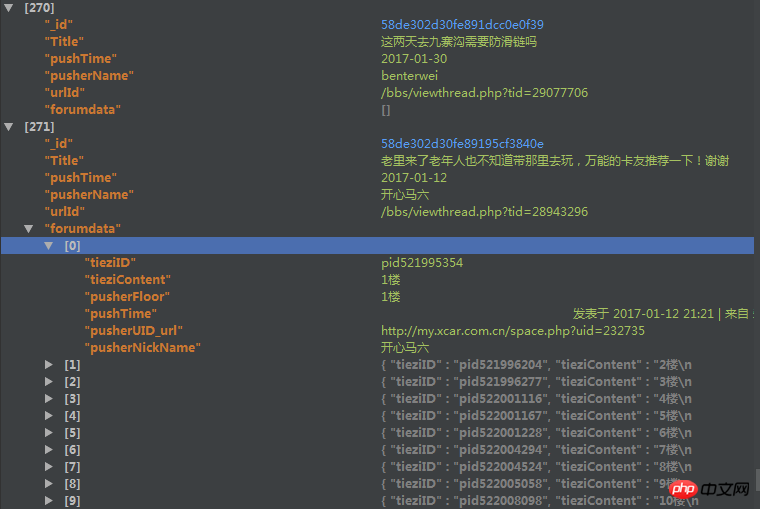
里边的forundata是这个帖子的每个楼层的发言情况。
但是因为帖子爬取的时候有可能重复爬取了,我现在想根据里边的urlId来去掉重复的帖子,但是在去除的时候我想保留帖子的forumdata(是list类型)字段中列表长度最长的那个。
用mongodb的distinct方法只能返回重复了的帖子urlId,都不返回重复帖子的其他信息,我没法定位。。。假如重复50000个,那么我还要根据这些返回的urlId去数据库中find之后再在mongodb外边代码修改吗?可是即使这样,我发现运行的时候速度特别慢。
之后我用了group函数,但是在reduce函数中,因为我要比较forumdata函数的大小,然后决定保留哪一个forumdata,所以我要传入forumdata,但是有些forumdata大小超过了16M,导致报错,然后这样有什么解决办法吗?
或者用第三种方法,用Map_reduce,但是我在map-reduce中的reduce传入的forumdata大小限制竟然是8M,还是报错。。。
代码如下
group的代码:
reducefunc=Code(
'function(doc,prev){'
'if (prev==null){'
'prev=doc'
'}'
'if(prev!=null){'
'if (doc.forumdata.lenth>prev.forumdata.lenth){'
'prev=doc'
'}'
'}'
'}'
)
map_reduce的代码:
reducefunc=Code(
'function(urlId,forumdata){'
'if(forumdata.lenth=1){'
'return forumdata[0];'
'}'
'else if(forumdata[0].lenth>forumdata[1].lenth){'
'return forumdata[0];'
'}'
'else{'
'return forumdata[1]}'
'}'
)
mapfunc=Code(
'function(){'
'emit(this.urlId,this.forumdata)'
'}'
)望各位高手帮我看看这个问题该怎么解决,三个方案中随便各一个就好,或者重新帮我分析一个思路,感激不尽。
鄙人新人,问题有描述不到位的地方请提出来,我会立即补充完善。

黄舟2017-04-18 10:34:12
この問題がまだ解決されていない場合は、次のアイデアを参照するとよいでしょう:
1. MongoDB では集約が推奨されますが、map-reduce は推奨されません。
2. 要件の中で非常に重要な点は、配列の長さである Forumdata の長さを取得して、配列の長さが最も長いドキュメントを見つけることです。元の記事では、Forumdata はリストであると述べています (MongoDB では配列である必要があります)。MongoDB は配列のサイズを取得するための $size 演算子を提供します。以下の栗を参照してください:
リーリー
3. 上記のデータを取得した後、集計で $sort や $group などを使用して、ニーズを満たすドキュメントの objectId を見つけることができます。具体的な方法については、次の投稿を参照してください。https://segmentfault.com/q/10...
4.最後に関連するObjectIdを一括削除します
類似:
var dupls = [] 削除する objectId を保存しますdb.collectionName.remove({_id:{$in:dupls}})
ご参考までに。
MongoDB が大好きです!楽しんでください!
つついてください<-左側をつついてください、4 月です! MongoDB 中国語コミュニティ深セン ユーザー カンファレンスの登録が開始されました。偉大な神々が集結!

迷茫2017-04-18 10:34:12
データの量がそれほど大きくない場合は、データを保存するたびに再度クロールして、最も多くのデータを含むデータ セットのみが保存されることを検討できます。
優れたクローラ戦略>>優れたデータクリーニング戦略

PHPz2017-04-18 10:34:12
ネットユーザーに感謝します。qq グループで誰かがアイデアを出しました。マップでは、forumdata が最初に urlId で処理され、次に urlId と forumdatad.length が返され、最大の forumdata を持つものが返されます。 .length と対応する urlId が保持され、最後にそれをデータベースに保存し、このデータベースの urlId を介して元のデータベースからすべてのデータを読み取ります。試してみたところ、効率は期待していたほどではありませんでしたが、それでも以前に Python を使用するよりもはるかに高速でした。
map とreduce のコードを添付します:
'''javaScript
mapfunc=Code(
reducefunc=コード(
リーリー リーリーmapfunc=コード(
リーリー)
reducefunc=コード(
リーリー)
リーリー