
网址:http://quote.eastmoney.com/ce...
要做的是提取网页中的表格数据(如:板块名称,及相应链接下的所有个股,依然是个表格)
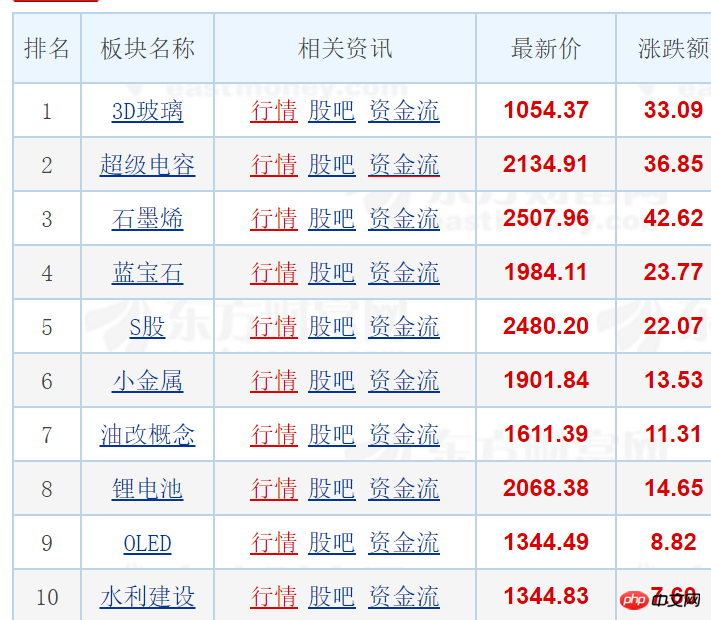
暂时只写了这些代码:
import urllib2
from bs4 import BeautifulSoup
url='http://quote.eastmoney.com/ce...'
req=urllib2.Request.(url)
page=urllib2.urlopen(req)
soup=BeautifulSoup(page)
table = soup.find("table")
但是table里面没有内容,也就是完全没找到,这是怎么回事啊。po是小白,希望大神们可以多多指教,谢谢!

