ホームページ > に質問 > 本文
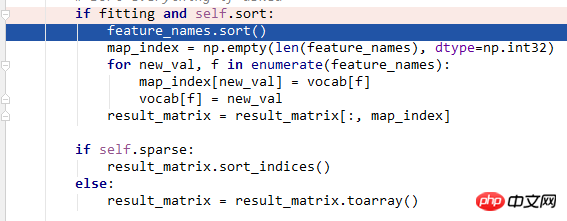
在进行文本分类时,选用了所有词以及词组成的二元词组混合之后作为特征,进行训练时定位到一句代码是feature_names.sort(),因为词是string,二元词组是tuple,所以会报错。请问有哪位大神知道该怎么处理这种情况吗?
feature_names.sort()
string
tuple