ホームページ > に質問 > 本文
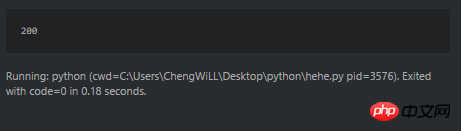
import urllib2 opener = urllib2.build_opener() html = None response = None response = opener.open('http://www.sxxrcs.com/was5/web/') html = response.code print html
比如这个爬虫,输出状态码是200。
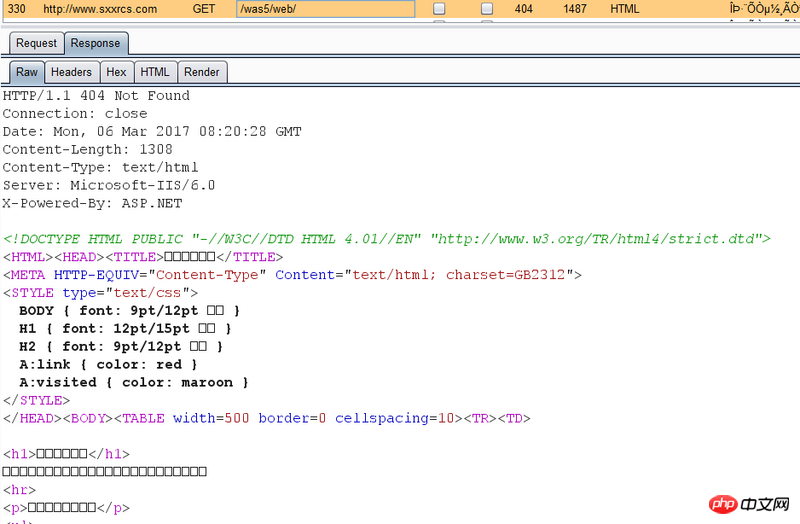
可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?
伊谢尔伦2017-04-18 10:26:31
リクエストを使用する
高洛峰2017-04-18 10:26:31
200は正常です、リクエストは便利で速いです。