
用charles对一览(https://www.yilan.io/home/?ca...)进行抓包,该页面是懒加载形式,每一次加载会生成一个recommended(登录情况下文件名变化但是原理相同),这个文件里面有json可以取得想要的数据。
但是post的地址(见图片顶部)如果直接复制访问会报404,不知道该如何获得可以获取数据的真实地址,并进行若干个recommended的批量抓取呢?
谢谢!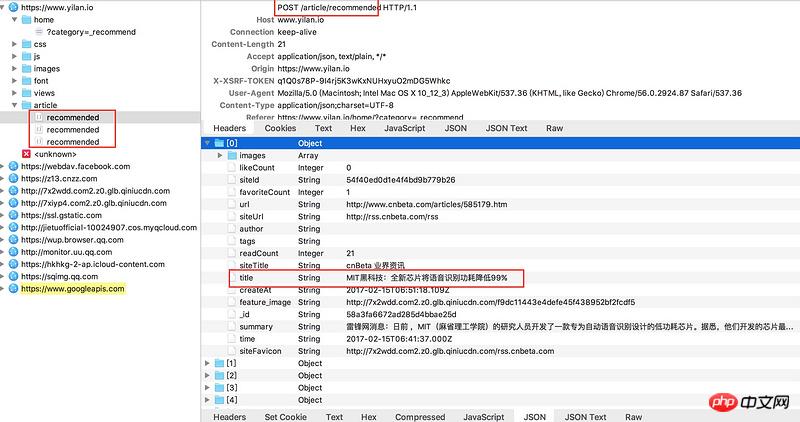
巴扎黑2017-04-18 10:24:53
私の方法について話しましょう。データをクロールしました。 firebug を使用しています。開いた後、次のパスを見つけました。 https://www.yilan.io/article/recommended
投稿するコンテンツを確認した後、このデータセット {"skip":0,"limit":20} が必要です。以下のコードを書き始めてください:
実行結果は以下の通りです:
リーリーその後、必要なコンテンツを抽出するだけです。制限の値を変更して、一度に取得するコンテンツの量を変更できます。
ウェブサイトは投稿されたデータをバックグラウンドでチェックする場合があり、エラーがある場合は 404 が発生するため、パスを直接開いてアクセスすることはできません。

大家讲道理2017-04-18 10:24:53
おそらく HTTP HEADERS の設定が不適切であると思われます。具体的には、通常のブラウザをシミュレートする一連の HEADERS を用意するか、ブラウザ内でリクエストを追跡することができます。
