
需要爬取三峡水库的实时水情数据,可以在网页中选择日期显示水情信息,如果一天天选择再复制数据发现很是耗时,我现在需要将下图中三峡水利枢纽2014年-2016年每天的数据爬下来。

网址如下:
http://www.ctgpc.com.cn/sxjt/...
通过浏览器自带的检查工具,右键检查元素,查看 network,查看调用的 ajax API 地址:初步分析后发现是通过ajax调用了以下网址,并用POST传递了一个日期数据,例如今天2017-02-15给该网址:
http://www.ctgpc.com.cn/eport...
Header如下:
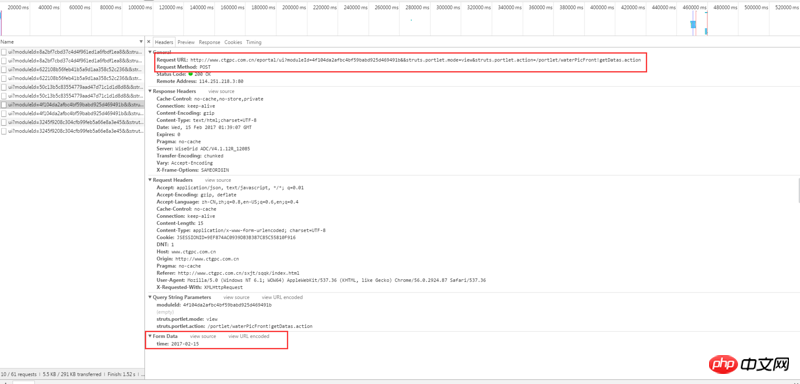
Response如下:

之前有搜索到类似的问题:https://segmentfault.com/q/10...
但是按照回答并没能解决我的疑惑,因此在这里求助各位前辈,麻烦大家了

伊谢尔伦2017-04-18 10:21:32
リクエスト ライブラリを使用して投稿の送信をシミュレートできます。 ブラウザー検査ツールから、渡されたパラメーターが time:2017-02-07 であることがわかります。 data={"time": 2017-02-07 などの日付} を定義します。 次に、日付をループして日付に 1 日を追加するループを作成できます。それではr = requests.post("url", data=data, header=****)。 データを取り出してデータベースに保存します。各サイクルが遅すぎる場合は、コルーチン ライブラリ gevent を追加して速度を上げることができます。2 年分のデータをキャプチャしたい場合は、365*2 回サイクルすれば問題ありません

迷茫2017-04-18 10:21:32
パケットをキャプチャして、投稿または取得をシミュレートします
以下の内容をご覧ください
Python クローラー関連付けワードのビデオとコード
https://zhuanlan.zhihu.com/p/...
Brother Huang からプロキシ IP と検証をキャプチャするための Python クローラーを学びます。
https://zhuanlan.zhihu.com/p/...
Huang Ge からプロキシ IP をキャプチャするための Python クローラーを学習します
https://zhuanlan.zhihu.com/p/...
