
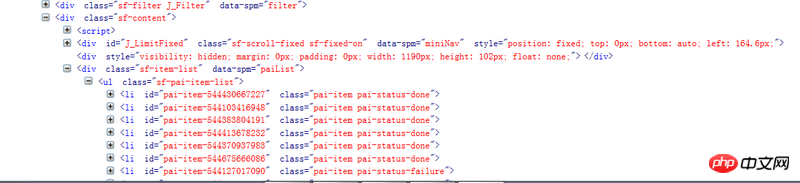
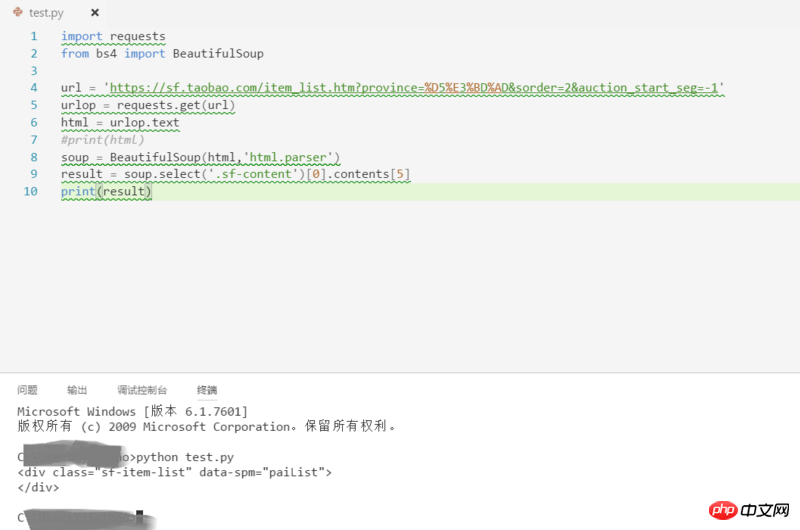
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~


伊谢尔伦2017-04-18 10:20:51
ヒント: Chrome F12 を使用して表示すると、動的に読み込まれるコンテンツがあり、ページの URL を直接リクエストしてもこのコンテンツを取得できません。右クリックして Web ページのソース コードを表示し、F12 のコンテンツと比較することをお勧めします。ソース コードにコンテンツがない場合は、ネットワーク内の他のリクエストをチェックして、必要なデータがあるかどうかを確認してください。必要。
