
比如这个酒店:http://hotels.ctrip.com/hotel/dianping/1943326.html
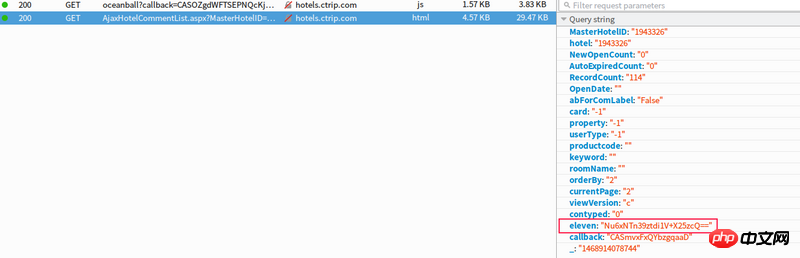
酒店的点评数据是通过ajax方式异步加载的,不想用模拟浏览器的方式来爬,太慢了,想直接请求点评数据的地址,但是这个eleven参数不知道是怎么生成的,在网页源码中没找到,分析js代码也没看出个所以然来,请大神来分析下,多谢了

迷茫2017-04-18 09:26:53
これは確かに少し変態的ですが、携帯電話のアクセスをシミュレートできます (ユーザー エージェントの変更)。
http://m.ctrip.com/html5/hotel のコメント データを取得できます。 /HotelDetail/dianping /1943326.html
リクエストをよく見てください。パラメータを計算している圧縮された JS があります。


