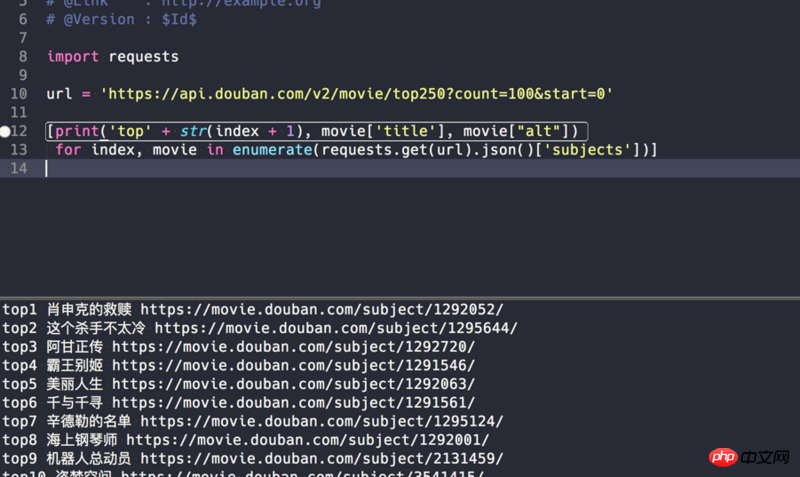
是一个豆瓣电影Top250代码,肿么能够实现在电影名前加上Top1 Top2
啊?
"""
爬取豆瓣电影TOP250 - 完整示例代码
"""
import codecs
import requests
from bs4 import BeautifulSoup
DOWNLOAD_URL = 'http://movie.douban.com/top250/'
def download_page(url):
return requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
movie_name_list = []
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('p', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).getText()
movie_name_list.append(movie_name)
next_page = soup.find('span', attrs={'class': 'next'}).find('a')
if next_page:
return movie_name_list, DOWNLOAD_URL + next_page['href']
return movie_name_list, None
def main():
url = DOWNLOAD_URL
with codecs.open('movies', 'wb', encoding='utf-8') as fp:
while url:
html = download_page(url)
movies, url = parse_html(html)
fp.write(u'{movies}\n'.format(movies='\n'.join(movies)))
if __name__ == '__main__':
main()谢谢大神!