
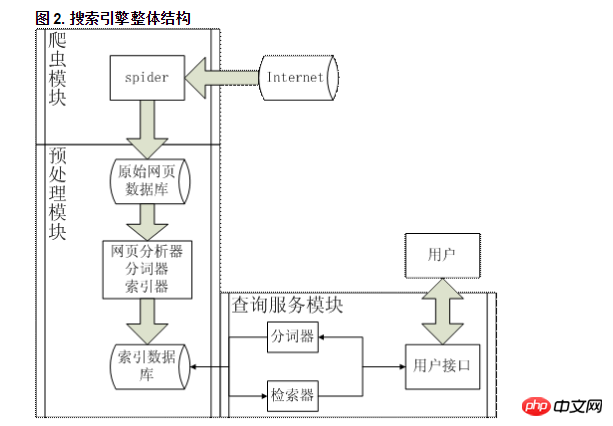
爬虫从 Internet 中爬取众多的网页作为原始网页库存储于本地,然后网页分析器抽取网页中的主题内容交给分词器进行分词,得到的结果用索引器建立正排和倒排索引,这样就得到了索引数据库,用户查询时,在通过分词器切割输入的查询词组并通过检索器在索引数据库中进行查询,得到的结果返回给用户。
请问这里原始网页库是该怎么实现,是直接存到数据库里吗?还是什么形式?
如果是存到数据库里,应该有哪些字段?




PHP中文网2017-04-17 17:49:58
Shenjianshou クラウド クローラー (http://www.shenjianshou.cn) を使用することをお勧めします。 クローラーは完全にクラウド上で記述され、実行されるため、開発環境を設定する必要はありません。実装は可能です。
わずか数行の JavaScript で、複雑なクローラーを実装し、アンチクローラー、JS レンダリング、データ公開、チャート分析、アンチリーチングなどの多くの機能を提供できます。これらはよく遭遇する問題です。クローラーの開発過程では、Archer がすべてを解決するのに役立ちます。
収集されたデータ:
(1) wecenterwordpressdiscuzdedeempire やその他の CMS システムなどの Web サイトに公開することを選択できます
(2) データベースに公開することもできます
(3) またはファイルをローカルにエクスポートします
特定の設定は「データ公開とエクスポート」にあります