ホームページ > に質問 > 本文
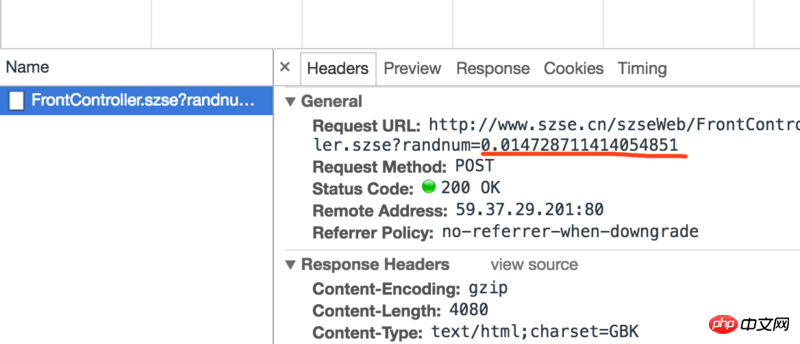
json コンテンツの取得方法を学んだところですが、今日クロールした Web サイトでは json コンテンツが返されず、各リクエスト リンクの後に乱数が生成されます
クロールしたいコンテンツに影響するかどうかわかりません
取得する必要があるコンテンツは、以下の図の中央のコンテンツです
Web サイトのリンク http://www.szse.cn/main/discl...
私が自分で試したコード:
出力内容が希望どおりではありません。登り方
黄舟2017-06-28 09:28:28
彼のヘッダー情報をコピーして使用してください。 。
漂亮男人2017-06-28 09:28:28
あなたの投稿の URL アドレスは間違っています。間違っているはずです