
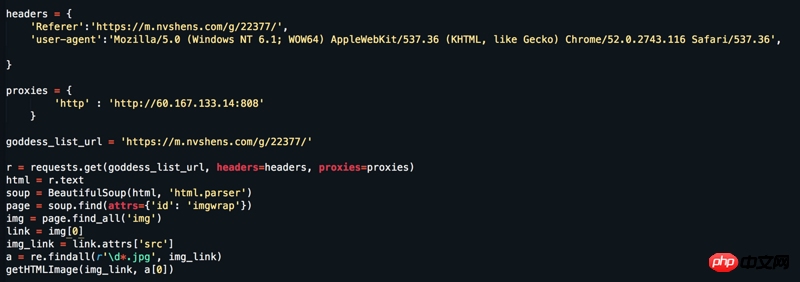
Web サイト: https://www.nvshens.com/g/22377/。ブラウザで Web サイトを直接開き、画像を右クリックしてダウンロードします。すると、クローラーによって直接要求された画像がブロックされました。次に、ヘッダーを変更して IP プロキシを設定しましたが、それでも機能しませんでした。しかし、パケット キャプチャを見ると、それは動的に読み込まれたデータではありません。 ! !答えてください = =
过去多啦不再A梦2017-06-12 09:29:51
その女の子はとてもかわいいです。
確かに右クリックで開くことができますが、更新するとホットリンクされた画像になります。一般に、ホットリンクを防ぐために、サーバーはリクエスト ヘッダーの Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Referer が変更されたかどうかを確認します)。 

我想大声告诉你2017-06-12 09:29:51
ウェブサイトの内容を眺めているだけで、それが公式であることを忘れるところでした。
リクエストしたすべての情報をフォローできます

それでは試してみてください
女神的闺蜜爱上我2017-06-12 09:29:51
リファラー この Web サイトのデザインによれば、各ページは単一のリファラーを使用するのではなく、人間のふりをする動作とより一致する必要があります
以下は、すべての写真をキャプチャするために実行できる完全なコードです。 18ページに
