
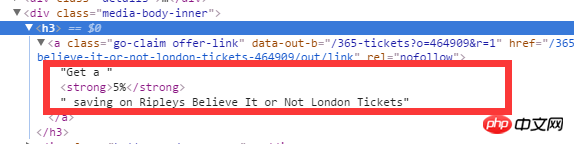
h3 の下の a タグの下にある完全なコンテンツを取得したいのですが (リプリーズ ビリーブ イット オア ノット ロンドンのチケットが 5% オフになります)、xpath を使用してこれを取得するにはどうすればよいですか?専門家からのアドバイスをお願いします


黄舟2017-05-24 11:37:18
元の投稿者が問題を明確に説明していなかったので、前の回答は元の投稿者の問題に対処していませんでした。元の投稿者が言いたかったのは、テキストを直接使用してサブタグのコンテンツを取得できないということだと思います。 ) メソッドまたはテキスト属性 (すでに見たことが前提) xpath の基本構文)。
Google 検索の xpath ですべてのテキストを取得します。最初のテキストが答えです。
投稿者は次の質問をすることができます: xpath を使用してタグに含まれるテキストコンテンツを抽出する方法 (ただし、ここでの答えは満足のいくものではありません)
漂亮男人2017-05-24 11:37:18
試してみてください
リーリーdescendant-or-self は、現在のノードと子孫ノードを示します
normal-space() は空白のみのノードの子孫ノードを削除します (これはオプションです)
参考リンク:
http://stackoverflow.com/ques...
