ホームページ > に質問 > 本文
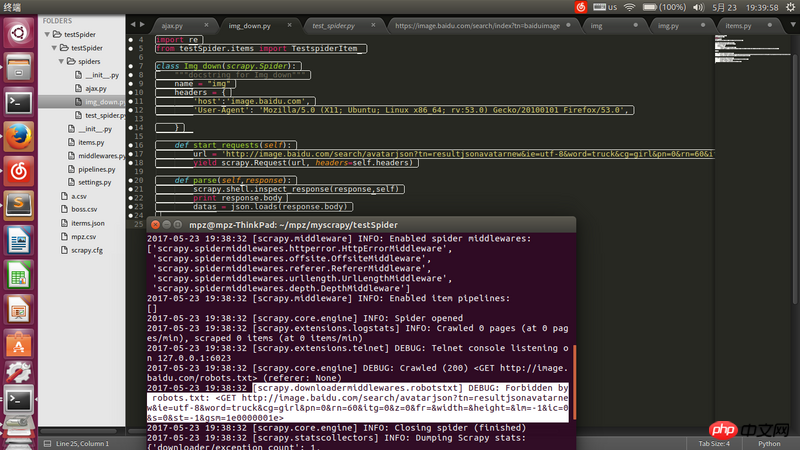
リクエストアドレスのurlはfirefoxで取得したjsonのアドレスですブラウザでは開けますがscrapyでクローリングするとBANされましたので解決してください。
https://image.baidu.com/search...
黄舟2017-05-24 11:36:48
settings.py 将 ROBOTSTXT_OBEY = Falseでお試しください。
settings.py
ROBOTSTXT_OBEY = False
某草草2017-05-24 11:36:48
聴覚者を追加せずに試してください
为情所困2017-05-24 11:36:48
まだ壁があるなら、私は二階に同意します。 Scrapy+Selenium+phantomjsという方法が使えます。