Web ページ上の商品の現在の販売価格を抽出したいです: http://www.igxe.cn/h1z1/43385... と、対応する製品の ITEM_ID
リクエストを操作するために PYTHON2.7 を使用しています。コードは次のとおりです:
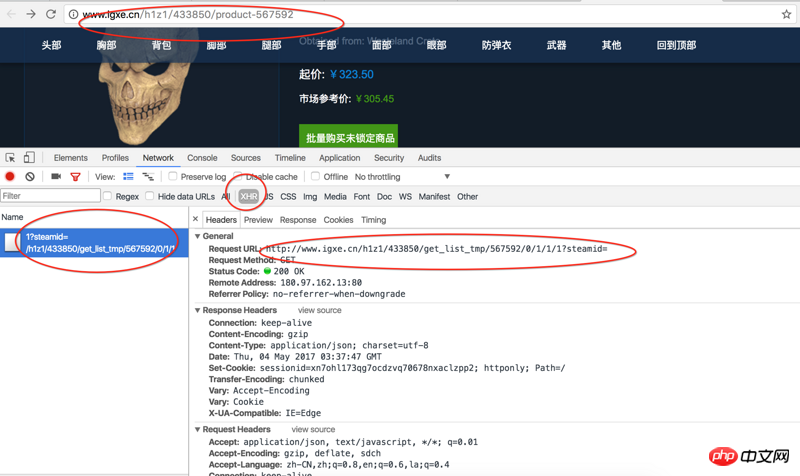
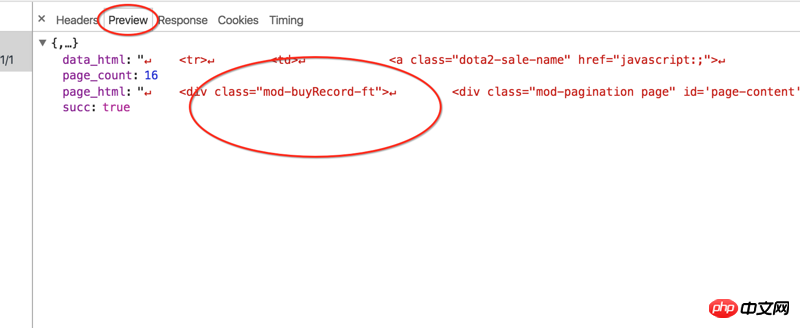
リーリー取得したコード ファイルには、必要な販売価格情報と商品 ID が含まれていないことを除いて、Web ページ上のほとんどの情報が含まれています。ただし、この情報はブラウザのレビュー要素を通じて取得できます。以下のとおりであります: # ##############
このコード スニペットは要素を検査することで簡単に取得できますが、ソース コードでは利用できないため、取得方法が非常にわかりません。 ソースコードに次のような部分を見つけましたが、これは AJAX 関連の情報を取得する方法なのでしょうか: 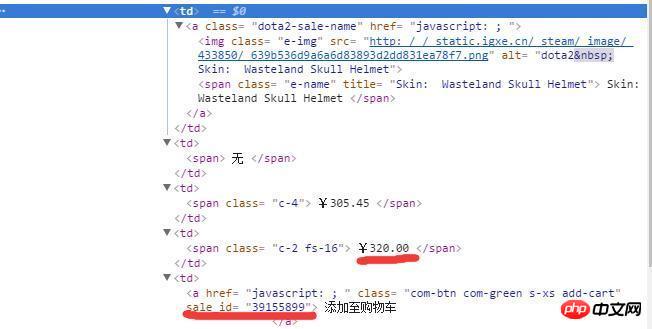 <スクリプト src="/static/csgo/js/page.js"></script>
<スクリプト src="/static/csgo/js/page.js"></script>
<スクリプト>
リーリー
リーリー
リーリー
ソースコードを見るとAJAXかJSのレンダリング処理があるような気がします。
初心者なので、この問題の解決方法が全く分かりませんので、神様にアドバイスをお願いしたいです。