
D ドライブにダウンロードする場合は問題ありませんが、私が作成したディレクトリにダウンロードする場合に問題があります (主に、D ドライブに疑問符の前に数字が付いた名前のディレクトリを作成したいため) (http://v .yupoo.com/photos/196...') のように URL に含めることは、リンクが多く、それぞれのリンクの番号が異なるため不可能です。この番号をこのリンクからダウンロードした画像を保存するフォルダーの名前。)
ソース コードは次のとおりです: 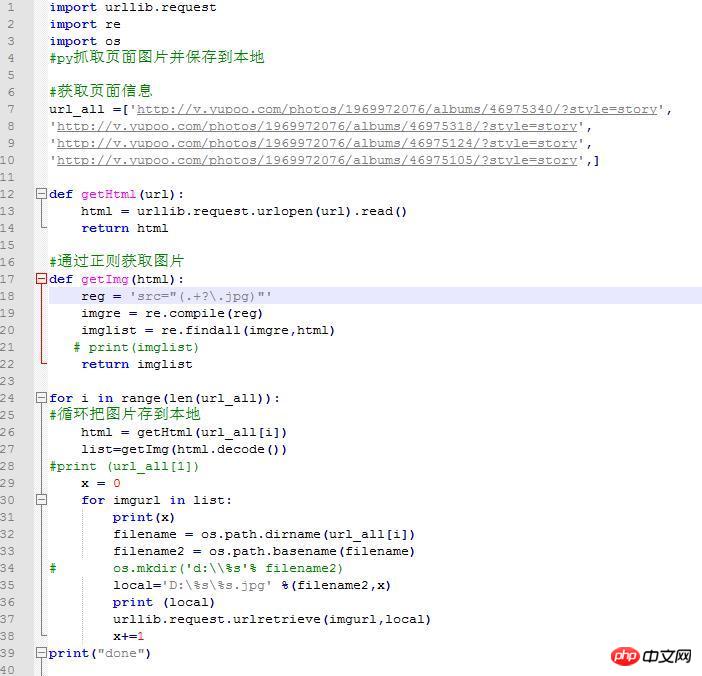
import urllib.request
import re
import os
url_all =['http://v.yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',]
def getHtml(url):
リーリーdef getImg(html):
リーリー# 印刷(imglist)
リーリーfor i in range(len(url_all)):
実行エラー:(win10 64ビットシステム、python3.6)
ファイル「C:Python36liburllibrequest.py」、urlretrieve の 258 行目
tfp = open(ファイル名, 'wb')
テスト後
次のように書かれた最後の文が出力されます: urllib.request.urlretrieve(imgurl,'d:\%s.jpg'% str(i*10 x))
テスト後、最初の 2 つの文は問題ありません。次の 3 番目の文を追加します。
local='d:\%s\%s.jpg' %(filename2,x)
印刷 (ローカル)
urllib.request.urlretrieve(imgurl,local)
エラーメッセージは次のとおりです: (上記と同じ)
ファイル「C:Python36liburllibrequest.py」、urlretrieve の 258 行目
tfp = open(ファイル名, 'wb')
FileNotFoundError: [Errno 2] そのようなファイルまたはディレクトリはありません: 'd:\46975340\0.jpg'
教えていただけますか、このパスに問題はありますか?どのように書けばよいのでしょうか。