
ハウス プロファイルを個別にキャプチャし、独立した列としてディクショナリに保存したいと考えていますが、for ループを使用してインライン要素を直接抽出する方法はありません。
これは私のコードです:
これは Web ページの HTML コードです:
リーリー曾经蜡笔没有小新2017-05-18 10:54:42
実際には、これにはパターンがあることがわかります。私がデモを書きました。 リーリー
get_text() を通じてすべての内部コンテンツを取得し、スペースを削除します。後で分割する場合は、split を使用できます。残りは書きません。ご質問がございましたら、お気軽にお問い合わせください。
给我你的怀抱2017-05-18 10:54:42
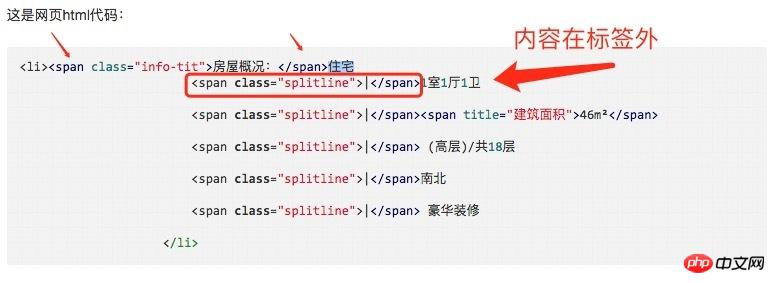
ハウス概要:
46m²
