
以下の小さな赤いボックスに示すように、urllib を使用して上海証券取引所の株式リストの xls ダウンロード リンクを取得したいと考えています。
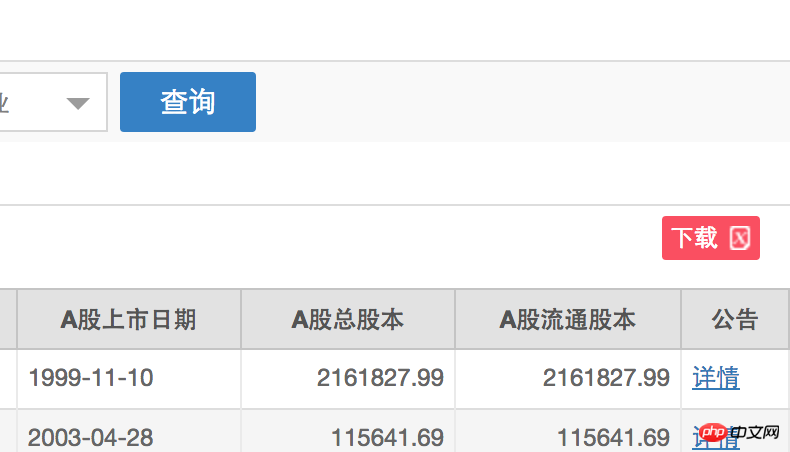
コードは以下のように表示されます
リーリー

黄舟2017-05-18 10:48:56
赤い線でマークされた URL で返された企業情報を確認できます。残りは、この URL をリクエストするブラウザをシミュレートすることです。省略しないと 403 が報告されます。
Refer の値をシミュレーションすることを忘れないでください。http://blog.csdn.net/ssshen14...
これは既存のソリューションです
