
 < /p>
< /p>
sql语句是:
explain SELECT bp.amount / (select count(*) from yd_order_product ここで、order = bp.order および product = bp.product ) as amount,s.costprice asprice,s.store,b.type from yd_batch_product as bp left yd_order_product を op on op.order = bp.order として結合し、op.product = bp.product left は yd_batch as b on bp に結合します。バッチ = b.id left join yd_order as o on bp.order = o .id left join yd_stock as s on bp.product = s.id ここで、o.deleted = '0' および s.forbidden = '0'、および b. createdDate が「2015-10-13 00:00:00」から「2017-04-30 23:59:59」の間で、s.store が (1,2,3,4,5,6) で、s.chainID = 1
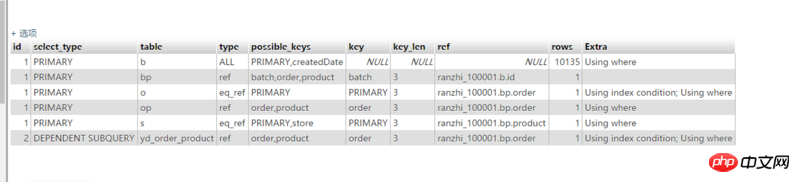
请问下、この最初の行のタイプはすべてです
巴扎黑2017-05-16 13:15:12
@TroyLiu、あなたの提案は、作成されたインデックスが多すぎるため、注文/製品/バッチ/金額の組み合わせインデックスを確立するという考えが間違っていると感じます。
SQL 最適化の中心的な考え方は、ビッグ データ テーブルが既存の where ステートメントの条件に従ってデータをフィルターできることです。この例では、
yd_batch_product テーブルが最大である必要がありますが、where ステートメントには次のようなテーブルがあります。フィルタリング条件がないため、実行効率が低下します。
「一時使用; ファイルソートを使用」が表示されるのは、group by のフィールドが最初のテーブル yd_batch_product テーブルのフィールド範囲内に完全に収まっていないためです。
提案:
1. yd_batch/yd_order/yd_stock は LEFT JOIN を使用しますが、where ステートメントにこれらのテーブル フィールドのフィルター条件があるため、INNER JOIN と同等になり、接続方法を INNER JOIN に変更できます。実行計画を判断するときは、最初に yd_batch_product テーブルをクエリするだけでは済みません。
2. yd_batch テーブルの createdDate フィールドにインデックスを作成して、実行プランの最初のドライバー テーブルに変更があるかどうかを確認します。createdDate の条件が高度にフィルタリングされている場合は、実行プランの最初のテーブルが yd_batch である必要があります。 。
3. yd_stock テーブルでは、ストアとchainIDを組み合わせて強力なフィルタリングを実現し、結合インデックスを作成し、前のステップと同じ方法で実行計画が変更されたかどうかを判断できます。
もちろん、最も理想的な状況は、ビジネスとデータから開始して、大量のデータをフィルターできる yd_batch_product テーブルの条件を見つけて、その条件に基づいてインデックスを作成することです。たとえば、yd_batch テーブルの createdDate フィールドには、yd_batch_product テーブルにも同様の冗長フィールドがあり、このフィールドはインデックスの作成に使用されます。
質問更新後の提案:
1. TYPE=ALL は、完全なテーブル スキャンが使用されていることを示します。createdDate はすでにインデックスを作成していますが、データベースの評価では、完全なテーブル スキャンを使用する方がコストが低く、通常は正常であると考えられます。より大きく、1 年以上のデータ、合計 10,000 アイテム以上を含む)。インデックスを使用する場合は、数日以内に範囲を絞り込んで、実行計画に変更があるかどうかを確認できます。もちろん、プロンプトを使用してインデックスの使用を強制することもできますが、効率は必ずしも高いとは限りません。
2. yd_order_product テーブルは 2 回クエリされますが、特に実行プラン内の select サブクエリはできるだけ避ける必要があります。

阿神2017-05-16 13:15:12
まず、yd_batch_product テーブルのデータ量が非常に多く、インデックスが正しく作成されないため、クエリ全体がインデックスを利用できなくなります。
テーブルの対応するキー列から bp が NULL であることがわかります。
最適化リファレンス:
yd_batch_product テーブルの order/product/batch/amount 列にジョイント インデックスを作成します (カバー インデックスを使用するために、amount もインデックスに追加されます)。