


今日は、 alsotang の クローラー チュートリアル を学び、CNode の簡単なクロールを見てみましょう。
プロジェクト craelr-demo を作成する
まず Express プロジェクトを作成し、当面はコンテンツを Web 上に表示する必要がないので、app.js ファイルのコンテンツをすべて削除します。もちろん、空のフォルダーで直接 npm install express を実行して、必要な Express 機能を使用することもできます。
ターゲット Web サイト分析
図に示すように、これは CNode ホームページの div タグの一部であり、必要な情報を見つけるためにこの一連の ID とクラスを使用します。
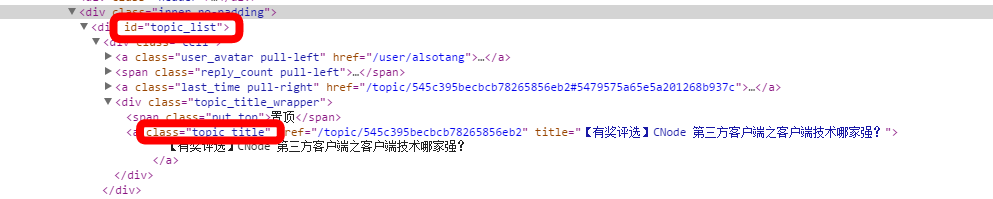
スーパーエージェントを使用してソース データを取得します
superagent は、ajax API で使用される HTTP ライブラリです。その使用法は、それを通じて get リクエストを開始し、結果をコールバック関数に出力します。
var url = require('url') // 操作 url
を解析します。 var superagent = require('superagent'); //これら 3 つの外部依存関係に対して npm install
を忘れないでください。 var チェリオ = require('チェリオ');
vareventproxy = require('eventproxy');
var targetUrl = 'https://cnodejs.org/';
superagent.get(targetUrl)
.end(function (err, res) {
console.log(res);
});
cherio を使用して解析します
// CSS セレクターを介してデータをフィルター処理します
$('#topic_list .topic_title').each(function (idx, element) {
console.log(要素);
});
関数を呼び出して各オブジェクトを走査し、HTML DOM 要素を返します。 .each(function(index, element))

の出力結果はconsole.log($element.attr('title'));广州 2014年12月06日 NodeParty 之 UC 场です
のようなタイトルは console.log($element.attr('href')); のような URL として出力されます。次に、NodeJS1 の url.resolve() 関数を使用して、完全な URL を完成させます。 /topic/545c395becbcb78265856eb2
.end(function (err, res) {
(エラー) {
の場合 return console.error(err);
}
var topicUrls = [];
var $ = Cheerio.load(res.text);
//ホームページ上のすべてのリンクを取得します
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
var href = url.resolve(tUrl, $element.attr('href'));
console.log(href);
//topicUrls.push(href);
});
});
eventproxy を使用して各トピックのコンテンツを同時にクロールします
このチュートリアルでは、深くネストされた (シリアル) メソッドとカウンター メソッドの例を示します。Eventproxy は、この問題を解決するためにイベント (並列) メソッドを使用します。すべてのクロールが完了すると、eventproxy はイベント メッセージを受信し、自動的に処理関数を呼び出します。
//ステップ 1:eventproxy のインスタンスを取得します
var ep = 新しいイベントプロキシ();
//ステップ 2: イベントをリッスンするためのコールバック関数を定義します。
//afterメソッドは繰り返し監視
//params:eventname(String) イベント名、times(Number) リスニング回数、callback コールバック関数
ep.after('topic_html', topicUrls.length, function(topics){
// トピックは配列であり、ep.emit('topic_html', ペア) に 40 個のペア
が 40 回含まれています //.map
トピック = トピック.マップ(関数(トピックペア){
// Cherio
を使用します var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = Cherio.load(topicHtml);
return ({
title: $('.topic_full_title').text().trim(),
href: topicUrl,
コメント1: $('.reply_content').eq(0).text().trim()
});
});
//結果
console.log('結果:');
console.log(トピック);
});
//ステップ 3: イベントメッセージを解放する
を決定する topicUrls.forEach(function (topicUrl) {
Superagent.get(topicUrl)
.end(function (err, res) {
console.log('フェッチ ' topicUrl ' 成功しました');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
結果は以下の通りです

延長演習 (チャレンジ)
メッセージのユーザー名とポイントを取得します

記事ページのソースコードでコメントしたユーザーのクラス名を見つけます。クラス名は Reply_author です。 console.log $('.reply_author').get(0) の最初の要素からわかるように、取得する必要があるものはすべてここにあります。

まず、記事をクロールして、必要なものをすべて一度に取得しましょう。
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
console.log($('.reply_author').get(0).children[0].data);
https://cnodejs.org/user/username
$('.reply_author').each(function (idx, element) {
var $element = $(element);
console.log($element.attr('href'));
});
ユーザー情報ページの$('.big').text().trim()にはポイント情報が表示されます。
cheerio の関数 .get(0) を使用して最初の要素を取得します。
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
これは 1 つの記事の単なるキャプチャであり、まだ 40 件の修正が必要です。

 ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM
ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM現実世界におけるJavaScriptのアプリケーションには、サーバー側のプログラミング、モバイルアプリケーション開発、モノのインターネット制御が含まれます。 2。モバイルアプリケーションの開発は、ReactNativeを通じて実行され、クロスプラットフォームの展開をサポートします。 3.ハードウェアの相互作用に適したJohnny-Fiveライブラリを介したIoTデバイス制御に使用されます。
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM私はあなたの日常的な技術ツールを使用して機能的なマルチテナントSaaSアプリケーション(EDTECHアプリ)を作成しましたが、あなたは同じことをすることができます。 まず、マルチテナントSaaSアプリケーションとは何ですか? マルチテナントSaaSアプリケーションを使用すると、Singの複数の顧客にサービスを提供できます
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AMこの記事では、許可によって保護されたバックエンドとのフロントエンド統合を示し、next.jsを使用して機能的なedtech SaaSアプリケーションを構築します。 FrontEndはユーザーのアクセス許可を取得してUIの可視性を制御し、APIリクエストがロールベースに付着することを保証します
 JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AM
JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AMJavaScriptは、現代のWeb開発のコア言語であり、その多様性と柔軟性に広く使用されています。 1)フロントエンド開発:DOM操作と最新のフレームワーク(React、Vue.JS、Angularなど)を通じて、動的なWebページとシングルページアプリケーションを構築します。 2)サーバー側の開発:node.jsは、非ブロッキングI/Oモデルを使用して、高い並行性とリアルタイムアプリケーションを処理します。 3)モバイルおよびデスクトップアプリケーション開発:クロスプラットフォーム開発は、反応および電子を通じて実現され、開発効率を向上させます。
 JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AM
JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AMJavaScriptの最新トレンドには、TypeScriptの台頭、最新のフレームワークとライブラリの人気、WebAssemblyの適用が含まれます。将来の見通しは、より強力なタイプシステム、サーバー側のJavaScriptの開発、人工知能と機械学習の拡大、およびIoTおよびEDGEコンピューティングの可能性をカバーしています。
 javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AM
javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AMJavaScriptは現代のWeb開発の基礎であり、その主な機能には、イベント駆動型のプログラミング、動的コンテンツ生成、非同期プログラミングが含まれます。 1)イベント駆動型プログラミングにより、Webページはユーザー操作に応じて動的に変更できます。 2)動的コンテンツ生成により、条件に応じてページコンテンツを調整できます。 3)非同期プログラミングにより、ユーザーインターフェイスがブロックされないようにします。 JavaScriptは、Webインタラクション、シングルページアプリケーション、サーバー側の開発で広く使用されており、ユーザーエクスペリエンスとクロスプラットフォーム開発の柔軟性を大幅に改善しています。
 pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AM
pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AMPythonはデータサイエンスや機械学習により適していますが、JavaScriptはフロントエンドとフルスタックの開発により適しています。 1. Pythonは、簡潔な構文とリッチライブラリエコシステムで知られており、データ分析とWeb開発に適しています。 2。JavaScriptは、フロントエンド開発の中核です。 node.jsはサーバー側のプログラミングをサポートしており、フルスタック開発に適しています。
 JavaScriptをインストールするにはどうすればよいですか?Apr 05, 2025 am 12:16 AM
JavaScriptをインストールするにはどうすればよいですか?Apr 05, 2025 am 12:16 AMJavaScriptは、最新のブラウザにすでに組み込まれているため、インストールを必要としません。開始するには、テキストエディターとブラウザのみが必要です。 1)ブラウザ環境では、タグを介してHTMLファイルを埋め込んで実行します。 2)node.js環境では、node.jsをダウンロードしてインストールした後、コマンドラインを介してJavaScriptファイルを実行します。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

