
ホームページ >ウェブフロントエンド >jsチュートリアル >UnicodeとJavaScriptの開発の歴史を簡単に解説_基礎知識
UnicodeとJavaScriptの開発の歴史を簡単に解説_基礎知識

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 16:19:261286ブラウズ
1. Unicode とは何ですか?
Unicode は、世界中のすべての文字を 1 つのセットに含めるという非常に単純なアイデアから生まれました。コンピューターがこの文字セットをサポートしている限り、すべての文字を表示でき、文字化けはなくなります。
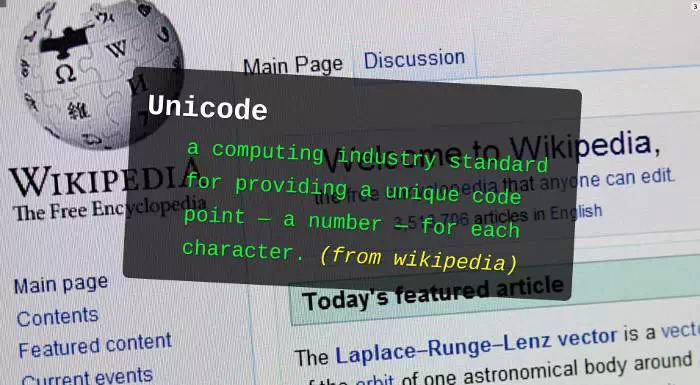
0 から始まり、各シンボルに「コードポイント」と呼ばれる番号が割り当てられます。たとえば、コード ポイント 0 のシンボルは null (すべての 2 進ビットが 0 であることを意味します) です。
上記の式で、U は直後の 16 進数が Unicode コード ポイントであることを示します。

現在、Unicode の最新バージョンはバージョン 7.0 で、74,500 個の中国語、日本語、韓国語の文字を含む合計 109,449 個の記号が含まれています。世界中に存在する記号の 3 分の 2 以上が東アジアの文字から来ていると概算できます。たとえば、中国語で「良い」を表すコード ポイントは 16 進数で 597D です。
非常に多くのシンボルがあるため、Unicode は一度に定義されるのではなく、パーティションに分けて定義されます。各領域には 65536 (216) 文字を格納でき、これをプレーンと呼びます。現在、プレーンは合計 17 (25) あります。これは、Unicode 文字セット全体のサイズが 221 であることを意味します。
最初の 65536 文字ビットは基本プレーン (略称 BMP) と呼ばれ、そのコード ポイントの範囲は 16 進数で書かれ、U 0000 から U FFFF です。最も一般的な文字はすべて、Unicode によって定義および発表された最初のプレーンであるこのプレーンに配置されます。
残りの文字は補助プレーン (SMP と略される) に配置され、コード ポイントの範囲は U 010000 から U 10FFFF です。

2. UTF-32 および UTF-8
Unicode は各文字のコード ポイントを規定するだけであり、このコード ポイントをどのようなバイト順で表現するかはエンコード方法に関係します。
最も直感的なエンコード方法は、各コード ポイントが 4 バイトで表され、バイトの内容がコード ポイントに 1 対 1 で対応するものです。このエンコード方式は UTF-32 と呼ばれます。たとえば、コード ポイント 0 は 4 バイトの 0 で表され、コード ポイント 597D の前には 2 バイトの 0 が続きます。

UTF-32 の利点は、変換ルールがシンプルで直感的であり、検索効率が高いことです。欠点は、同じ英語テキストの場合、ASCII エンコードよりも 4 倍大きくなるということです。この欠点は非常に致命的であるため、実際にこのエンコード方式を使用する人は誰もいません。HTML5 標準では、Web ページを UTF-32 にエンコードしてはならないと明確に規定しています。

人々が本当に必要としていたのは、スペースを節約するエンコード方式であり、これが UTF-8 の誕生につながりました。 UTF-8 は可変長エンコード方式であり、文字長は 1 バイトから 4 バイトまでです。一般的に使用される文字ほどバイトは短くなります。最初の 128 文字は 1 バイトのみで表され、これは ASCII コードとまったく同じです。
数値範囲バイト 0x0000 - 0x007F10x0080 - 0x07FF20x0800 - 0xFFFF30x010000 - 0x10FFFF4
UTF-8 の省スペース特性により、UTF-8 はインターネット上で最も一般的な Web ページのエンコードとなっています。ただし、今日のテーマとはあまり関係がないので、詳しくは説明しません。具体的なトランスコード方法については、私が何年も前に書いた「文字エンコードに関するメモ」を参照してください。
3. UTF-16 の概要
UTF-16 エンコードは、UTF-32 と UTF-8 の間にあり、固定長エンコード方式と可変長エンコード方式の特性を組み合わせています。
そのエンコード規則は非常に単純です。基本プレーンの文字は 2 バイトを占め、補助プレーンの文字は 4 バイトを占めます。つまり、UTF-16 のエンコード長は 2 バイト (U 0000 ~ U FFFF) または 4 バイト (U 010000 ~ U 10FFFF) です。

それでは、2 バイトが見つかった場合、それが単独で文字であるか、それとも他の 2 バイトと一緒に解釈する必要があるのかをどのように判断すればよいのでしょうか?
これは非常に賢い設計です。基本プレーンでは、U D800 から U DFFF までは空のセグメントです。つまり、これらのコード ポイントはどの文字にも対応しません。したがって、この空のセグメントを使用して、補助プレーン文字をマッピングできます。
具体的には、補助プレーンには 220 の文字ビットがあります。これは、これらの文字に対応するには少なくとも 20 のバイナリ ビットが必要であることを意味します。 UTF-16 は、これらの 20 ビットを半分に分割します。最初の 10 ビットは上位ビット (H) と呼ばれ、U D800 から U DBFF (スペース サイズ 210) にマップされ、最後の 10 ビットは U DC00 から U DFFF (空間サイズ 210)、下位ビット (L) と呼ばれます。これは、補助プレーン文字が 2 つの基本プレーン文字表現に分割されることを意味します。

したがって、2 バイトに遭遇し、そのコード ポイントが U D800 と U DBFF の間にあることがわかった場合、次の 2 バイトのコード ポイントは U DC00 と U DBFF、つまりこれら 4 つのバイトの間にあるはずであると結論付けることができます。バイトを一緒に読み取る必要があります。
4. UTF-16 トランスコード式
Unicode コードポイントを UTF-16 に変換する場合、まずこれが基本平坦文字であるか補助平坦文字であるかを区別します。前者の場合は、コード ポイントを、対応する 2 バイト長の 16 進数形式に直接変換します。
補助フラット文字の場合、Unicode バージョン 3.0 はトランスコーディング式を提供します。

文字  を例に挙げます。これは U 1D306 のコードポイントを持つ補助平面文字です。UTF-16 に変換する計算プロセスは次のとおりです。
を例に挙げます。これは U 1D306 のコードポイントを持つ補助平面文字です。UTF-16 に変換する計算プロセスは次のとおりです。
つまり、文字 の UTF-16 エンコーディングは 0xD834 DF06 で、長さは 4 バイトです。

5. JavaScript はどのエンコーディングを使用しますか?

JavaScript 言語は Unicode 文字セットを使用しますが、サポートされるエンコード方法は 1 つだけです。
このエンコーディングは UTF-16、UTF-8、UTF-32 のいずれでもありません。上記のコーディング方法はいずれも JavaScript では使用されません。
JavaScript は UCS-2 を使用します!

6. UCS-2 エンコーディング
なぜUCS-2が突然現れたのでしょうか?これには少し歴史が必要です。
インターネットが登場する前の時代、統一されたキャラクターセットを作成したいと考えていた 2 つのチームがありました。 1 つは 1988 年に設立された Unicode チーム、もう 1 つは 1989 年に設立された UCS チームです。彼らはお互いの存在を発見すると、すぐに合意に達しました。世界には 2 つの統一された文字セットは必要ありません。
1991 年 10 月、2 つのチームはキャラクター セットを統合することを決定しました。つまり、今後は Unicode という 1 つの文字セットのみがリリースされ、以前にリリースされた文字セットは Unicode と完全に一致するようになります。

UCS の開発は Unicode よりも早く進んでいます。最初のエンコード方式 UCS-2 は 1990 年に発表され、すでにコード ポイントを持つ文字を表すために 2 バイトを使用しました。 (当時は、基本プレーンという 1 つのプレーンしかなかったので、2 バイトで十分でした。) UTF-16 エンコーディングは 1996 年 7 月まで発表されず、それが UCS-2 のスーパーセットであることが明確に発表されました。 、基本プレーン文字は UCS-2 エンコーディングを継承し、補助プレーン文字は 4 バイト表現方法を定義します。
簡単に言うと、この 2 つの関係は、UTF-16 が UCS-2 を置き換えるか、UCS-2 が UTF-16 に統合されるということです。したがって、現在は UTF-16 のみが存在し、UCS-2 は存在しません。
7. JavaScript誕生の背景
では、なぜ JavaScript はより高度な UTF-16 を選択せず、廃止された UCS-2 を使用するのでしょうか?
答えは簡単です。したくないか、できないかのどちらかです。なぜなら、JavaScript 言語が登場したとき、UTF-16 エンコーディングは存在しませんでした。
1995 年 5 月、Brendan Aich は JavaScript 言語の設計に 10 日間を費やし、10 月に最初の解釈エンジンが発表され、翌年の 11 月に Netscape が言語標準を ECMA に正式に提出しました (プロセス全体の詳細については、 「JavaScript の誕生」を参照)。 UTF-16 のリリース時期 (1996 年 7 月) と比較すると、当時 Netscape には他に選択肢がなく、エンコード方式として UCS-2 しか利用できなかったことがわかります。

8. JavaScript 文字関数の制限事項
JavaScript は UCS-2 エンコードのみを処理できるため、この言語のすべての文字は 2 バイト文字であり、4 バイト文字の場合は 2 バイトの文字として扱われます。 JavaScript の文字関数はすべてこの影響を受けるため、正しい結果を返すことができません。

文字 を例に挙げます。その UTF-16 エンコードは 0xD834DF06 の 4 バイトです。問題が発生します。4 バイトのエンコーディングは UCS-2 に属しておらず、JavaScript はそれを 2 つの別個の文字 (U D834 と U DF06) としてのみ認識します。前に述べたように、これら 2 つのコード ポイントは空であるため、JavaScript は が 2 つの空の文字で構成される文字列であると認識します。

上記のコードは、JavaScript が文字 の長さを 2 とみなし、取得される最初の文字は null 文字であり、取得される最初の文字のコード ポイントが 0xDB34 であることを示しています。これらの結果はどれも正しくありません。

この問題を解決するには、コードポイントを判断して手動で調整する必要があります。以下は文字列をトラバースする正しい方法です。
上記のコードは、文字列をトラバースするときに、コード ポイントで判断する必要があることを示しています。それが 0xD800 から 0xDBFF の範囲にある限り、次の 2 バイトと一緒に読み取る必要があります。
同様の問題は、すべての JavaScript 文字操作関数に存在します。
String.prototype.replace()
String.prototype.substring()
String.prototype.slice()
...
上記の関数は、2 バイトのコード ポイントに対してのみ有効です。 4 バイトのコード ポイントを正しく処理するには、独自のバージョンを 1 つずつデプロイして、現在の文字のコード ポイント範囲を決定する必要があります。
9. ECMAScript 6

JavaScript の次のバージョンである ECMAScript 6 (略して ES6) は、Unicode サポートを大幅に強化し、この問題を基本的に解決します。
(1) 文字を正しく識別する
ES6 は 4 バイトのコード ポイントを自動的に認識できます。したがって、文字列の反復処理がはるかに簡単になります。
ただし、互換性を維持するために、length 属性は依然として元の方法で動作します。文字列の正しい長さを取得するには、次のメソッドを使用できます。
(2) コードポイント表現
JavaScript では、コード ポイントを直接使用して Unicode 文字を表現できます。その書き方は「バックスラッシュ u コード ポイント」です。
ただし、この表現は 4 バイトのコード ポイントには無効です。 ES6 ではこの問題が修正され、コード ポイントが中括弧内に配置されている限り、コード ポイントが正しく認識されるようになりました。

(3) 文字列処理関数
ES6 には、特に 4 バイトのコード ポイントを処理するいくつかの新しい関数が追加されています。
String.fromCodePoint(): Unicode コードポイントから対応する文字を返します
String.prototype.codePointAt(): 文字
から対応するコード ポイントを返します。String.prototype.at(): 文字列
内の指定された位置にある文字を返します。 (4) 正規表現
ES6 は、正規表現への 4 バイト コード ポイントの追加をサポートする u 修飾子を提供します。

(5) Unicode の正規化
一部の文字には、文字に加えて追加の記号が含まれています。たとえば、中国語のピンイン「Ƒ」では、文字の上にある声調が追加の記号です。多くのヨーロッパ言語では、声調記号が非常に重要です。

Unicode には 2 つの表現方法があります。 1 つは追加の記号を持つ 1 つの文字です。つまり、1 つのコード ポイントが 1 つの文字を表します。たとえば、í のコード ポイントは U 01D1 で、もう 1 つはメインの文字と結合された別個のコード ポイントとしての追加の記号です。つまり、2 つのコードです。 ドットは文字を表します。たとえば、í は O (U 004F) ˇ (U 030C) と書くことができます。
両方の表現は視覚的にも意味的にも同一であり、同等のものとして扱う必要があります。ただし、JavaScript ではそれがわかりません。
ES6 は正規化メソッドを提供し、「Unicode 正規化」、つまり 2 つのメソッドを同じシーケンスに変換できるようにします。
ES6 の詳細については、「ECMAScript 6 の概要」を参照してください。