



用的语言是python。目前想要爬的同花顺股票行情(http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860),又一次被javascript卡住。因为一页中只显示52条信息,想要看全部的股票数据必须点击下面的页码,是用javascript写的,无法直接用urllib2之类的库处理。试过用webkit(ghost.py)来模拟点击,代码如下:
page, resources = ghost.open('http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860')
page, resources = ghost.evaluate("document.getElementById('hd').nextSibling.getElementsByTagName('div')[13].getElementsByTagName('a')[7].click();", expect_loading = True)
提示Unable to load requested page, 或是返回的page是None。不知道无法解决。求教是代码哪里错了,应该如何解决?(在百度和google找了很久解决方法,不过有关ghost.py的资料不是太多,没能解决。)
以及,求问是否有更好的办法解决爬动态网页的问题?用webkit模拟好像会减慢爬的速度,不是上策。
回复内容:
Headless Webkit,开源的有 PhantomJS 等。能够解析并运行页面上的脚本以索引动态内容是现代爬虫的重要功能之一。
Google's Crawler Now Understands JavaScript: What Does This Mean For You?
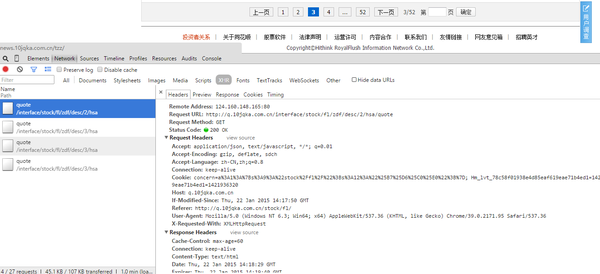

你这个爬虫跟JS关系不大,直接看Network,看发出的网络请求,分析每个URL,找出规律,然后用程序来模拟这样的请求,首先要善于用Chrome的Network功能,我们点几页,看Network如下:
第一页数据URL:
http://q.10jqka.com.cn/interface/stock/fl/zdf/desc/1/hsa/quote
我手上正好有个比较好的例子。需求:爬取爱漫画上的漫画。
问题:图片的名字命名不规则,通过复杂的js代码生成图片的文件名和url,动态加载图片。js代码的模式多样,没有统一的模式。
解决:Py8v库。读取下js代码,加一个全局变量追踪图片的文件名和url,然后Python和这个变量交互,取得某话图片的文件名和url。
全文在此
【原创】最近写的一个比较hack的小爬虫 能说 berserkJS 么……
不过这种玩意可抗不了量啊
╭(╯ε╰)╮ 嫌麻烦的话直接上selenium吧,几乎百分百地模拟用户在浏览器上的操作。也可以用来爬数据,不过速度较慢。 打开Chrome的开发人员控制台或者火狐的FireBug,转到Network那一栏,直接分析ajax访问的url到底是哪些。
对于特定网站的爬虫就不要想着模拟javascript运行了,太费力而且效果还不好。把网站的url结构弄明白了直接构造表单就好。 Selenium with Python 插一句题外话,同花顺好像可以自定义函数,写脚本计算数据,还是挺方便的,一定要自己把数据全部爬下来吗? phantomjs api比较吐血,建议基于之上封装的casperjs吧,写起来比较爽 一个好的爬虫需要解决两个问题:
1、能够解析动态网页,比如瀑布式网站
2、能够规避网站的封锁

 Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AM
Python:コンパイラまたはインタープリター?May 13, 2025 am 12:10 AMPythonは解釈された言語ですが、コンパイルプロセスも含まれています。 1)Pythonコードは最初にBytecodeにコンパイルされます。 2)ByteCodeは、Python Virtual Machineによって解釈および実行されます。 3)このハイブリッドメカニズムにより、Pythonは柔軟で効率的になりますが、完全にコンパイルされた言語ほど高速ではありません。
 ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AM
ループvs whileループ用のpython:いつ使用するか?May 13, 2025 am 12:07 AMuseaforloopwhenteratingoverasequenceor foraspificnumberoftimes; useawhileloopwhentinuninguntinuntilaConditionismet.forloopsareidealforknownownownownownownoptinuptinuptinuptinuptinutionsituations whileoopsuitsituations withinterminedationations。
 Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AM
Pythonループ:最も一般的なエラーMay 13, 2025 am 12:07 AMpythonloopscanleadtoErrorslikeinfiniteloops、ModifiningListsDuringiteration、Off-Oneerrors、Zero-dexingissues、およびNestededLoopinefficiencies.toavoidhese:1)use'i
 ループの場合、およびPythonのループ:それぞれの利点は何ですか?May 13, 2025 am 12:01 AM
ループの場合、およびPythonのループ:それぞれの利点は何ですか?May 13, 2025 am 12:01 AMforloopsareadvastountousforknowterations and sequences、offeringsimplicityandeadability;
 Python:編集と解釈に深く掘り下げますMay 12, 2025 am 12:14 AM
Python:編集と解釈に深く掘り下げますMay 12, 2025 am 12:14 AMpythonusesahybridmodelofcompilation andtertation:1)thepythoninterpretercompilessourcodeodeplatform-indopent bytecode.2)thepythonvirtualmachine(pvm)thenexecuteTesthisbytecode、balancingeaseoputhswithporformance。
 Pythonは解釈されたものですか、それとも編集された言語であり、なぜそれが重要なのですか?May 12, 2025 am 12:09 AM
Pythonは解釈されたものですか、それとも編集された言語であり、なぜそれが重要なのですか?May 12, 2025 am 12:09 AMpythonisbothintersedand compiled.1)it'scompiledtobytecode forportabalityacrossplatforms.2)bytecodeisthenは解釈され、開発を許可します。
 ループ対pythonのループの場合:説明されたキーの違いMay 12, 2025 am 12:08 AM
ループ対pythonのループの場合:説明されたキーの違いMay 12, 2025 am 12:08 AMloopsareideal whenyouwhenyouknumberofiterationsinadvance、foreleloopsarebetterforsituationsは、loopsaremoreedilaConditionismetを使用します
 ループのために:実用的なガイドMay 12, 2025 am 12:07 AM
ループのために:実用的なガイドMay 12, 2025 am 12:07 AMhenthenumber ofiterationsisknown advanceの場合、dopendonacondition.1)forloopsareideal foriterating over for -for -for -saredaverseversives likelistorarrays.2)whileopsaresupasiable forsaresutable forscenarioswheretheloopcontinupcontinuspificcond


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

WebStorm Mac版
便利なJavaScript開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

