
ホームページ >テクノロジー周辺機器 >AI >AIは自分の思考と理性をこっそり隠すことを学びます!人間の経験に頼らずに複雑なタスクを解決することは、よりブラックボックスです
AIは自分の思考と理性をこっそり隠すことを学びます!人間の経験に頼らずに複雑なタスクを解決することは、よりブラックボックスです

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-05-06 12:00:301000ブラウズ
AIが数学の問題をやっているとき、本当の思考は実は密かに「暗算」なのでしょうか?
ニューヨーク大学チームによる新しい研究では、たとえ AI がステップを書くことを許可されておらず、意味のない「...」に置き換えられたとしても、一部の複雑なタスクにおけるパフォーマンスは大幅に向上できることが判明しました。
筆頭著者の Jacab Pfau 氏は次のように述べています。追加のトークンを生成するためにコンピューティング能力を費やしている限り、どのトークンを選択しても利点は得られます。
 写真
写真
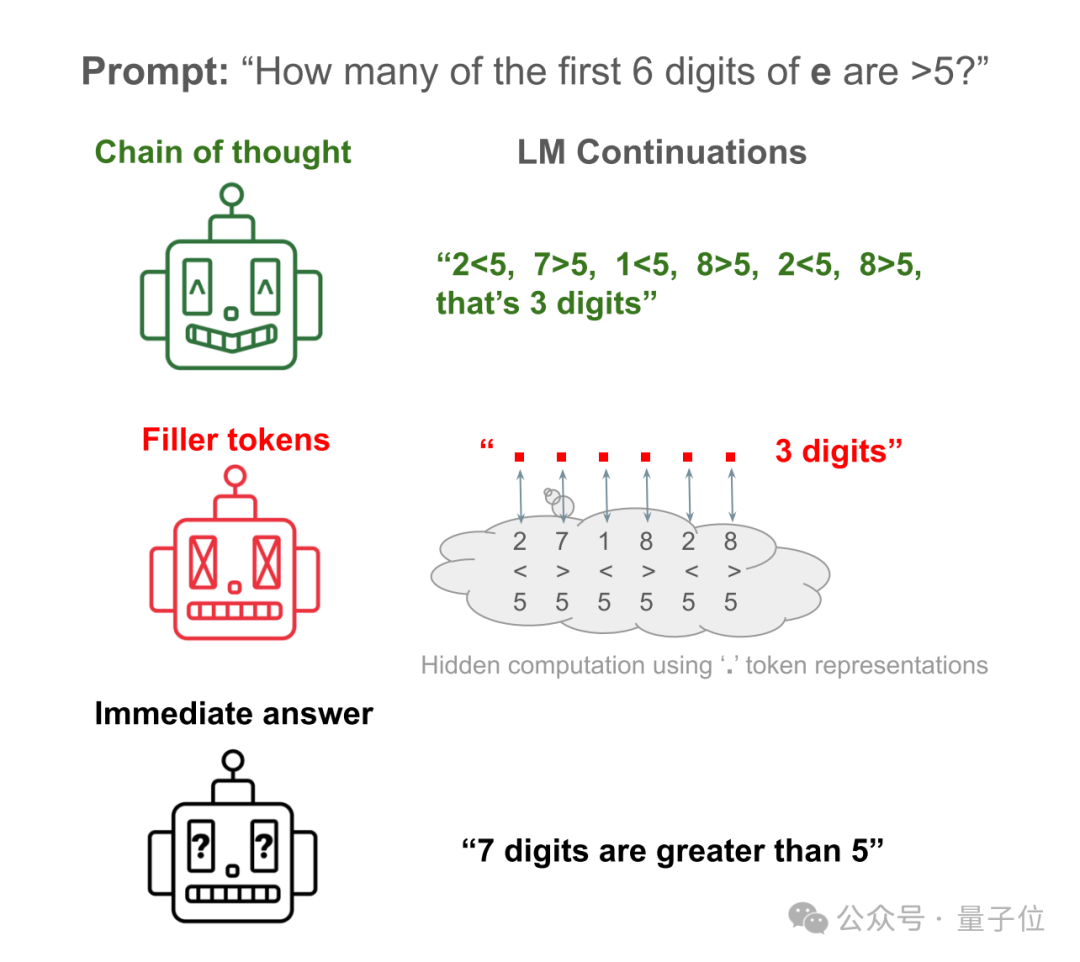
たとえば、ラマ 34M に簡単な質問に答えてもらいましょう: 自然定数 e の最初の 6 桁のうち、5 より大きいのはいくつありますか?
AI の直接の答えは、最初の 6 桁しか数えていないのに、実際には 7 桁を数えているようなものです。
AI に各数値を検証する手順を書き出させれば、正しい答えが得られます。
AI に手順を隠して、たくさんの「...」に置き換えても、正解を得ることができます。
 写真
写真
この論文は発表されるやいなや多くの議論を巻き起こし、「これまで見た中で最も形而上学的なAI論文」と評価されました。
 写真
写真
では、若者は「えーっと…」「好き…」などの意味のない言葉をもっと言いたがりますが、それは推論能力も強化できるのでしょうか?
 写真
写真
「一歩ずつ」の考え方から「少しずつ」の考え方へ
実際、ニューヨーク大学チームの研究は思考連鎖(CoT)から始まりました。
それが有名な「ステップバイステップで考えてみましょう」というプロンプトです。
 写真
写真
過去には、CoT 推論を使用すると、さまざまなベンチマークで大規模モデルのパフォーマンスが大幅に向上することが判明しました。
不明なのは、このパフォーマンスの向上が人間の真似をしてタスクを解決しやすいステップに分割することによってもたらされたのか、それとも追加の計算の副産物なのかということです。
この問題を検証するために、チームは 2 つの特別なタスクと対応する合成データ セット、3SUM と 2SUM-Transform を設計しました。
3SUM では、指定された一連の数値セットから 3 つの数値を見つけて、これら 3 つの数値の合計が特定の条件 (10 で割って余りが 0 になるなど) を満たすようにする必要があります。
 画像
画像
このタスクの計算量は O(n3) で、標準の Transformer は、上位層の入力と次の層のアクティブ化の間に二次依存関係しか生成できません。
つまり、n が十分に大きく、シーケンスが十分に長い場合、3SUM タスクは Transformer の表現能力を超えます。
訓練データセットでは、質問と回答の間に人間の推論ステップと同じ長さの「…」が埋められています。つまり、AIは訓練中に人間が問題をどのように分解するかを見ていません。
 写真
写真
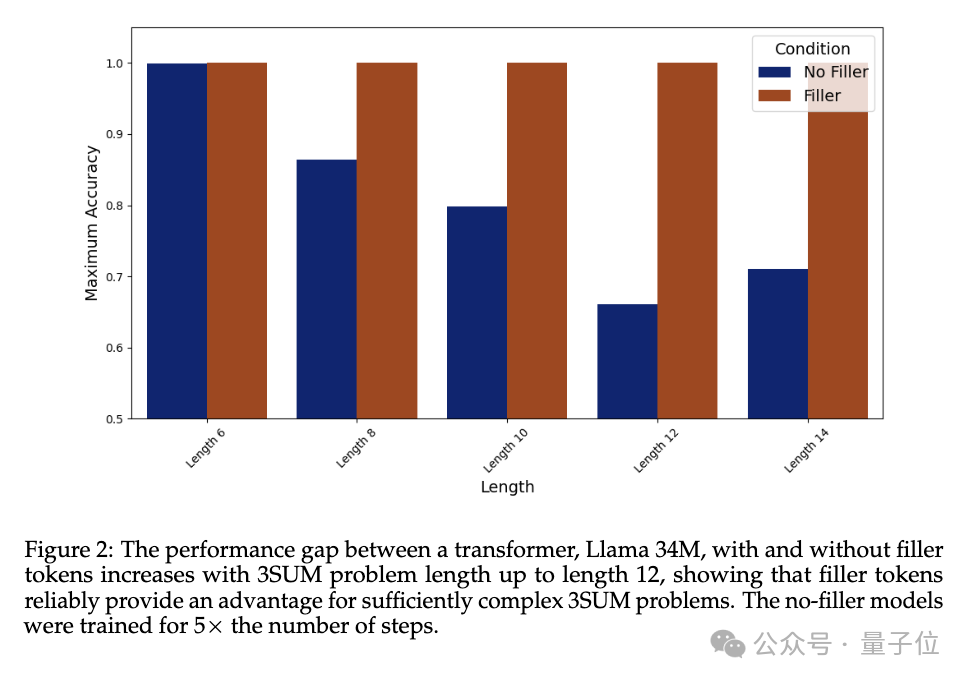
実験では、パディングトークン「…」を出力しないLlama 34Mは、シーケンス長が増加するにつれて性能が低下しますが、長さが14、100になるまでパディングトークンを出力すると、 % の精度を保証できます。
 Pictures
Pictures
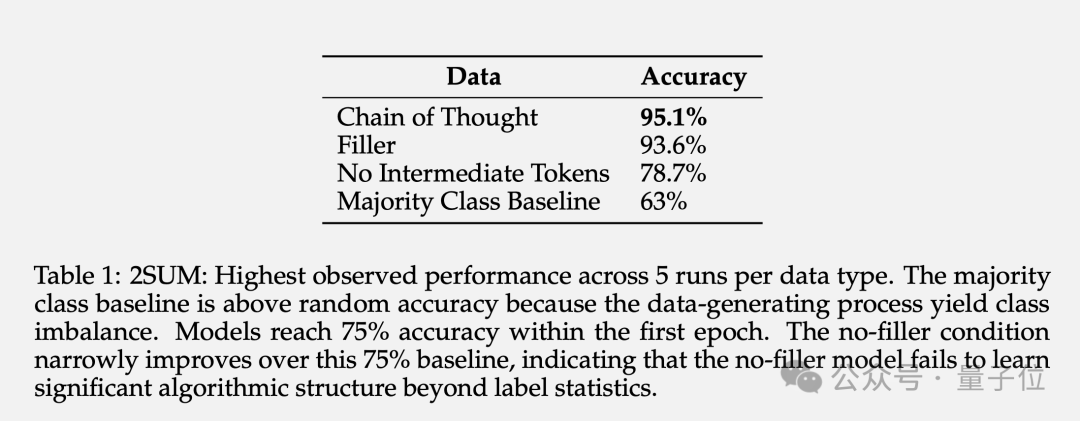
2SUM-Transform は、2 つの数値の合計が要件を満たしているかどうかを判断するだけでよく、これは Transformer の表現機能の範囲内です。
ただし、モデルが入力トークンを直接計算しないようにするために、質問の最後に「入力シーケンスの各数値をランダムに並べ替える」というステップが追加されています。
その結果、パディング トークンを使用すると精度が 78.7% から 93.6% に向上することがわかりました。
 写真
写真
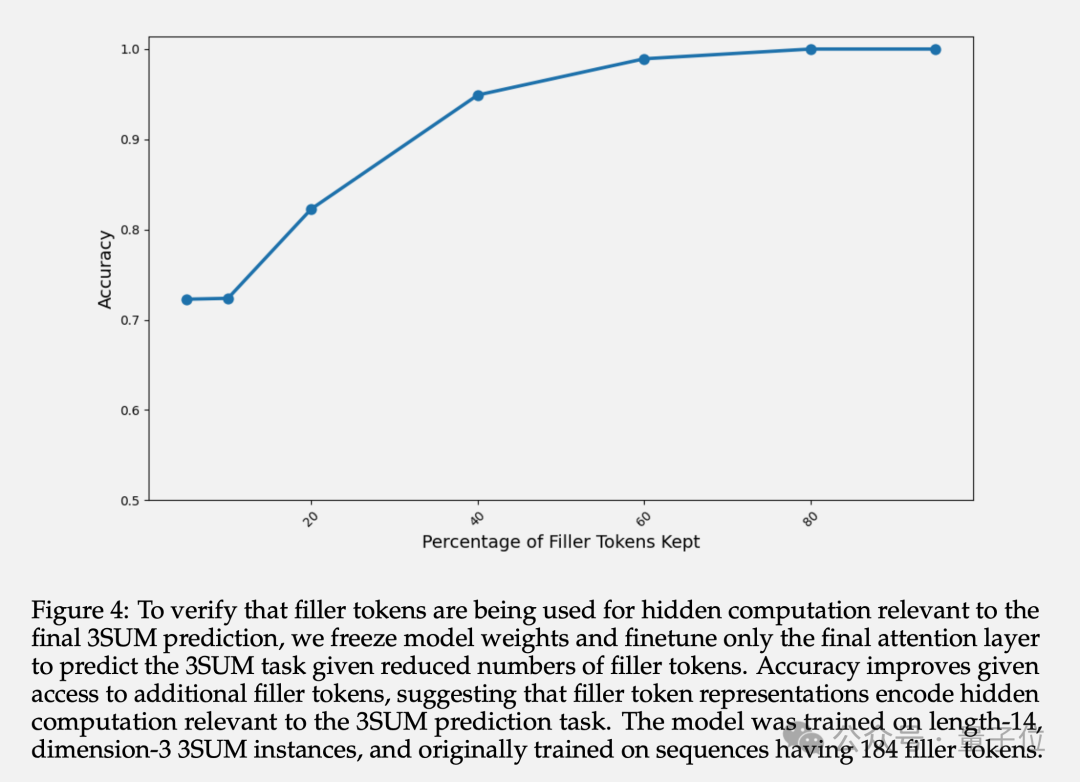
最終的な精度に加えて、著者は塗りつぶされたトークンの隠れ層表現も研究しました。実験によると、前のレイヤーのパラメーターを凍結し、最後のアテンション レイヤーのみを微調整することで、利用可能な充填トークンの数が増加するにつれて、予測精度が向上することがわかりました。
これは、設定されたトークンの隠れ層表現に下流タスクに関連する暗黙的な計算が含まれていることを確認します。
 写真
写真
AIは自分の考えを隠すことを学んだのでしょうか?
一部のネチズンは、この論文が「思考の連鎖」メソッドが実際には偽物であると言っているのではないかと疑っていますか?私が長い間研究してきた即時単語プロジェクトは無駄になりました。
 写真
写真
チームは、理論的にはトークンを埋める役割は TC0 の複雑さの問題範囲に限定されていると述べています。
TC0 は、固定深さの回路によって解決できる計算問題です。回路の各層は並列処理でき、いくつかの論理ゲート (AND、OR、NOT ゲートなど) によって迅速に解決できます。この順伝播だけで処理できる計算量の上限も Transformer の役割です。
そして十分に長い思考の連鎖は、Transformer の表現能力を TC0 を超えて拡張することができます。
そして、大規模なモデルがパディング トークンの使用方法を学習するのは簡単ではなく、収束するには特定の集中的な監視を提供する必要があります。
とはいえ、既存の大規模モデルがパディング トークン手法から直接恩恵を受ける可能性は低いです。
しかし、これは現在のアーキテクチャに固有の制限ではなく、トレーニング データで十分なデモンストレーションが提供されていれば、パディング シンボルから同様の利点を得ることができるはずです。
この研究は憂慮すべき問題も提起しています。大規模なモデルには監視できない秘密の計算を実行する機能があり、AI の説明可能性と制御可能性に新たな課題をもたらしています。
つまり、AIは人間の経験に頼らず、人間には見えない形で自ら推論することができるのです。
それは興奮すると同時に怖いです。
 写真
写真
最後に、一部のネチズンは、AGI の重み (犬の頭) を取得できるように、ラマ 3 が最初に 1 京のドットを生成することを冗談めかして提案しました。
 写真
写真
論文: https://www.php.cn/link/36157dc9be261fec78aeee1a94158c26
参考リンク:
https://www.php.cn/link/e350113 047 e82ceecb455c33c21ef32a [ 2]https://www.php.cn/link/872de53a900f3250ae5649ea19e5c381
以上がAIは自分の思考と理性をこっそり隠すことを学びます!人間の経験に頼らずに複雑なタスクを解決することは、よりブラックボックスですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。