
ホームページ >テクノロジー周辺機器 >AI >Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入

- PHPz転載
- 2024-04-29 16:55:121580ブラウズ
FP8 以下の浮動小数点定量化精度は、もはや H100 の「特許」ではありません。
Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考えていましたが、Microsoft DeepSpeed チーム は NVIDIA からの公式サポートなしに A100 で FP6 の実行を強制的に開始しました。
テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化速度が INT4 に近いか、場合によっては INT4 を超え、パフォーマンスが INT4 よりも優れていることを示しています。後者は高精度です。
これに基づいて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeedなどの深層学習推論フレームワークに統合されています。
この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットより 2.65 倍高くなります。
これを読んだ後、ある機械学習研究者は、マイクロソフトの研究は単にクレイジーとしか言いようがないと言いました。
絵文字もすぐに起動され、次のようになります。
NVIDIA: H100 のみが FP8 をサポートします。
マイクロソフト: わかりました、自分でやります。

#では、このフレームワークはどのような効果をもたらし、その背後にはどのようなテクノロジーが使用されているのでしょうか?
FP6 を使用して Llama を実行します。シングル カードはデュアル カードより高速です。
A100 で FP6 精度を使用すると、カーネル レベルのパフォーマンスが向上します。
研究者らは、さまざまなサイズの Llama モデルと OPT モデルの線形レイヤーを選択し、NVIDIA A100-40GB GPU プラットフォーム上の CUDA 11.8 を使用してテストしました。
結果は、NVIDIA の公式 cuBLAS(W16A16) および TensorRT-LLM(W8A16) と比較されており、TC-FPx(W6A16) はより速く 度改善の最大値はそれぞれ 2.6 倍と 1.9 倍です。
4 ビット BitsandBytes(W4A16) 方式と比較して、TC-FPx の最大速度向上は 8.9 倍です。
(W と A はそれぞれ重み量子化ビット幅とアクティベーション量子化ビット幅を表します)
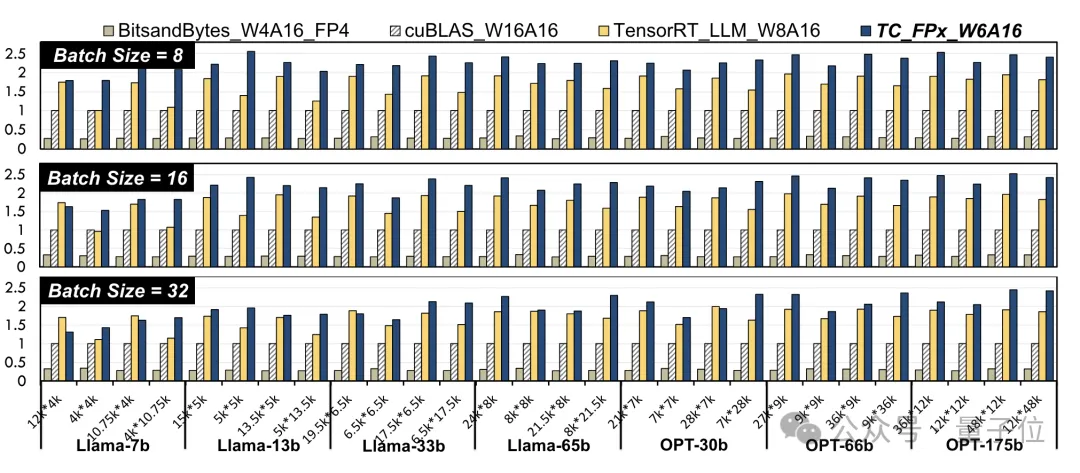
△正規化されたデータ。 cuBLAS の結果は 1
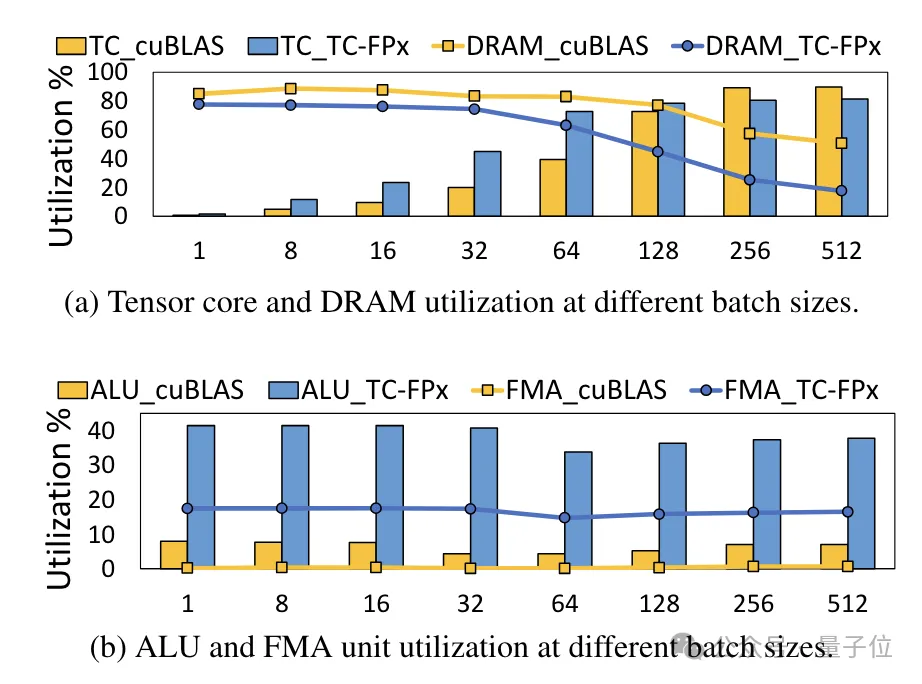
同時に、TC-FPx コアは DRAM メモリへのアクセスも削減し、DRAM 帯域幅の使用率と Tensor コアの使用率、および ALU と FMA ユニットの使用率を向上させます。
TC-FPx に基づいて設計されたエンドツーエンドの推論フレームワーク FP6-LLM は、大規模なモデルにも大きなメリットをもたらします。改善。 Llama-70B を例にとると、シングル カードで FP6-LLM を使用した場合のスループットは、デュアル カードでの FP16 のスループットよりも 2.65 倍高く、バッチ サイズが 16 未満の場合のレイテンシも低くなります。 FP16。
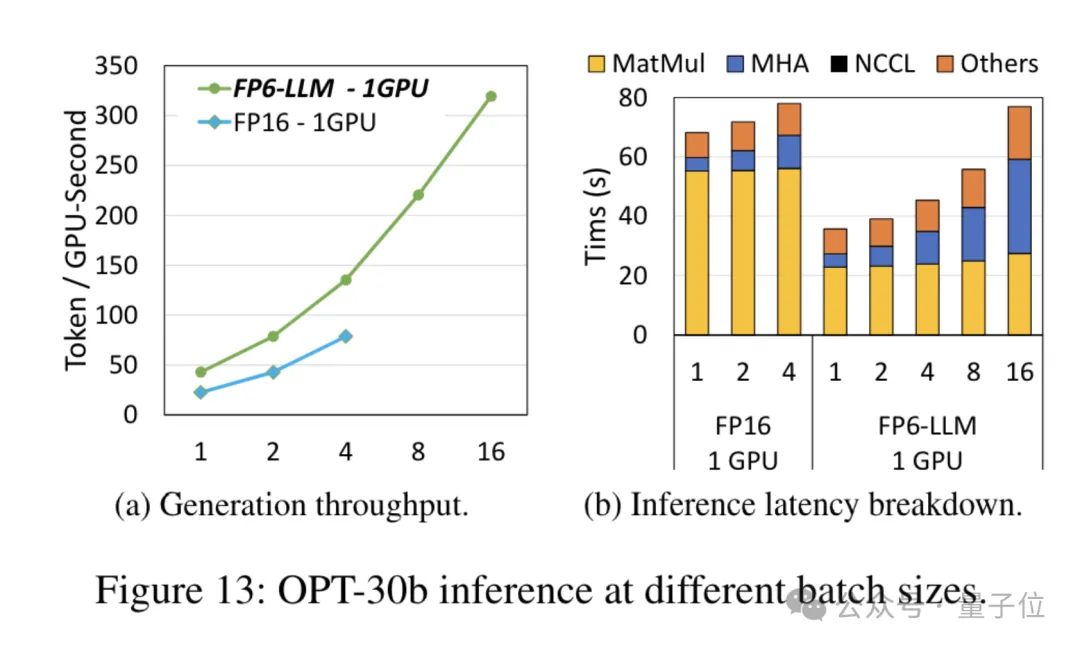
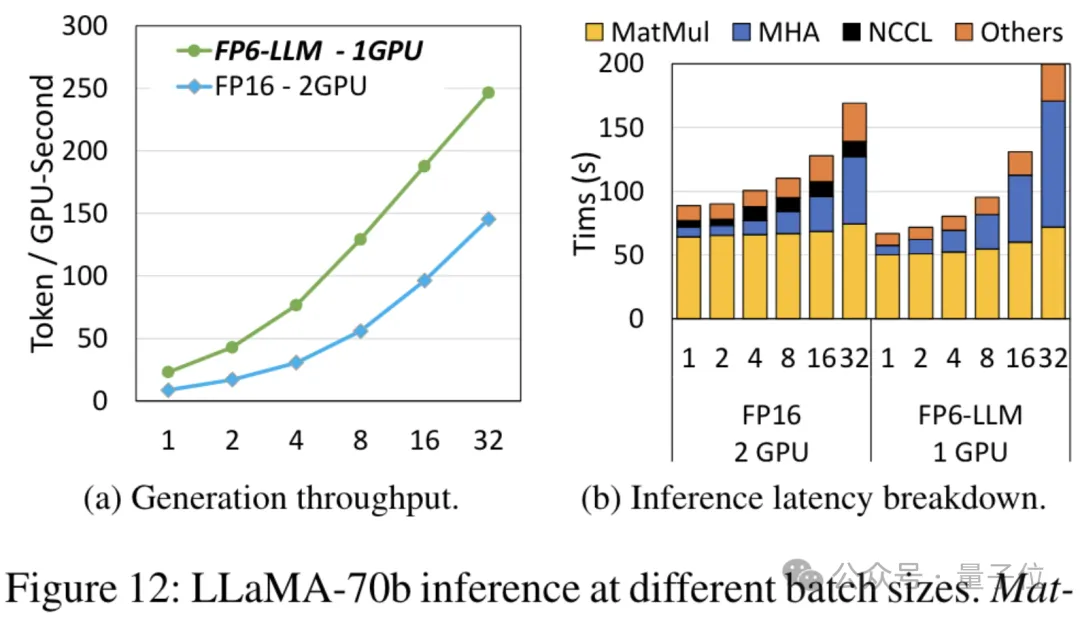 パラメータ数が少ないモデル OPT-30B (FP16 も 1 枚のカードを使用) については、FP6-LLM によってスループットが大幅に向上し、レイテンシが短縮されます。
パラメータ数が少ないモデル OPT-30B (FP16 も 1 枚のカードを使用) については、FP6-LLM によってスループットが大幅に向上し、レイテンシが短縮されます。
また、この条件下で 1 枚のカード FP16 でサポートされる最大バッチ サイズは 4 のみですが、FP6-LLM はバッチ サイズ 16 で正常に動作します。
 #それでは、Microsoft チームはどのようにして A100 上での FP16 定量化を実現したのでしょうか?
#それでは、Microsoft チームはどのようにして A100 上での FP16 定量化を実現したのでしょうか?
カーネル ソリューションの再設計
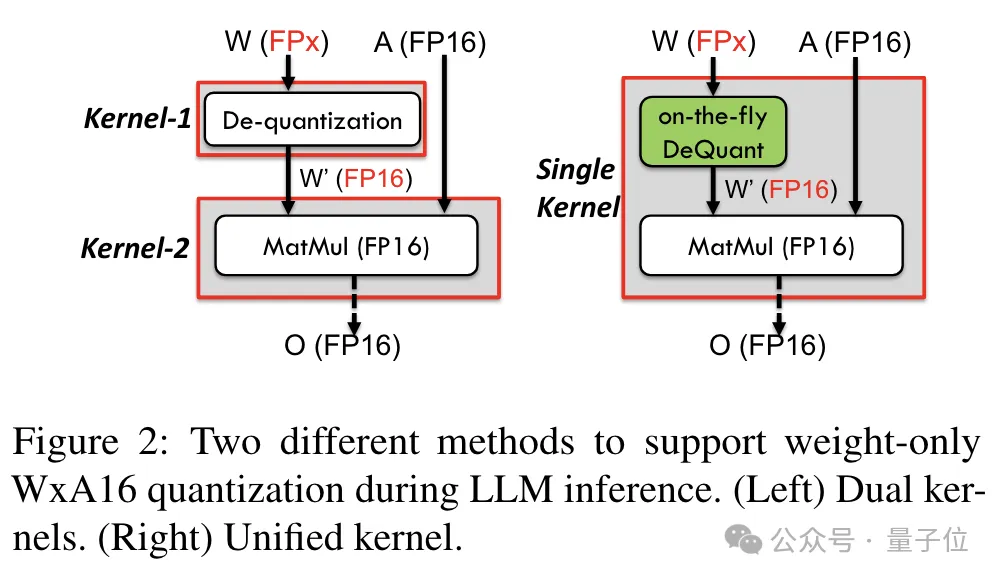
6 ビットを含む精度をサポートするために、TC-FPx チームは、さまざまなビット幅の量子化重みをサポートできる統合カーネル ソリューションを設計しました。
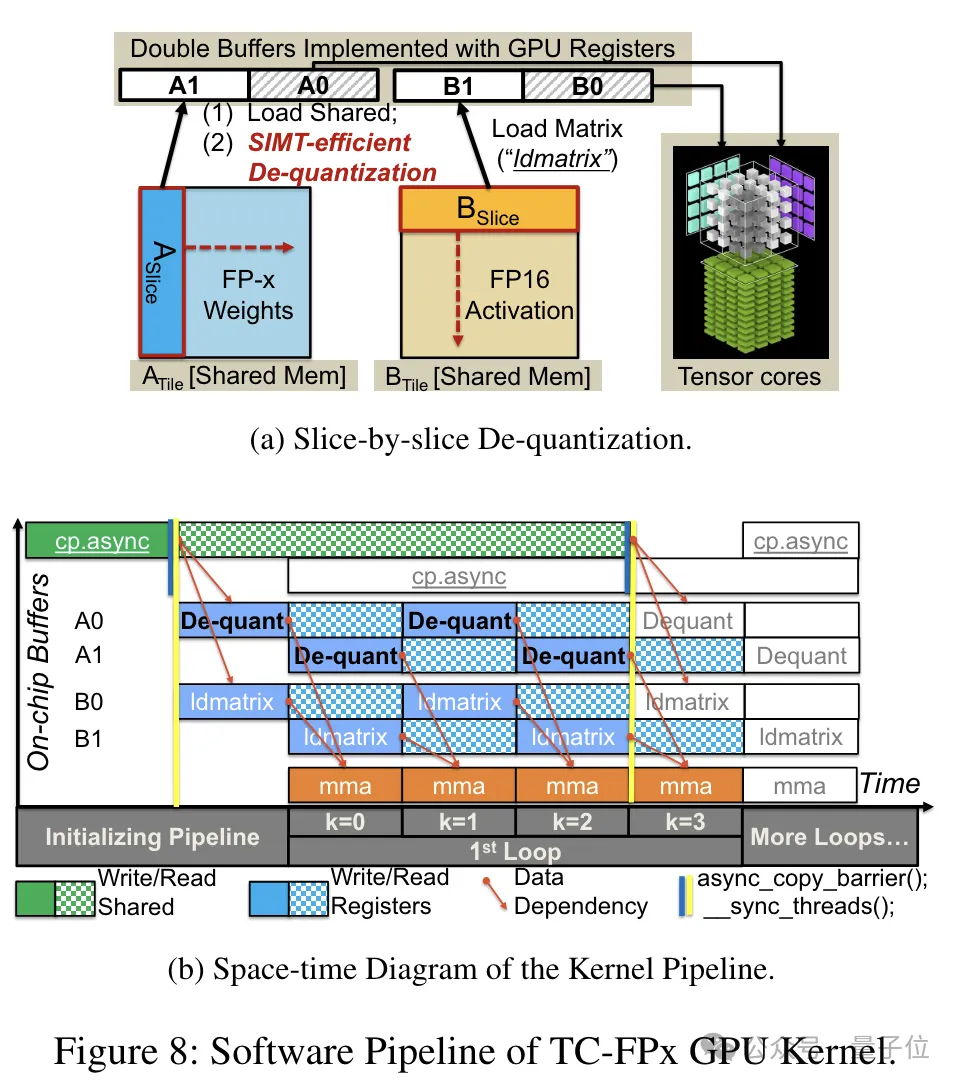
従来のデュアルコア方式と比較して、TC-FPx は逆量子化と行列乗算を単一コアに統合することでメモリ アクセスの数を削減し、パフォーマンスを向上させます。
低精度の量子化を実現する核心的な秘密は、逆量子化によって FP6 精度のデータを FP16 として「偽装」し、それを FP16 形式で計算するために GPU に渡すことです。
同時に、チームは ビットレベルのプリパッケージング テクノロジも使用して、非プロセッサ向けの GPU メモリ システムの問題を解決しました。 -2 ビット幅の累乗 (6 ビットなど) 不親切な質問。
具体的には、ビットレベルのプリパッキングとは、GPU メモリ システムに適した方法でアクセスできるように 6 ビットの量子化された重みを再配置するなど、モデル推論前の重みデータの再編成です。
さらに、GPU メモリ システムは通常 32 ビットまたは 64 ビット ブロックのデータにアクセスするため、ビットレベルのプリパッキング テクノロジーによって 6 ビットの重みもパックされ、次の形式で保存できます。これらの整列されたブロックとアクセス。

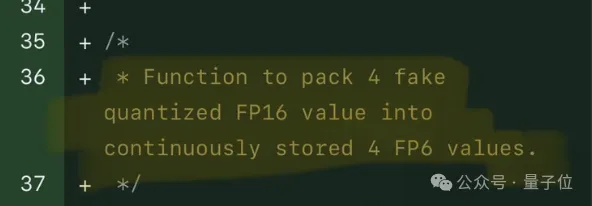
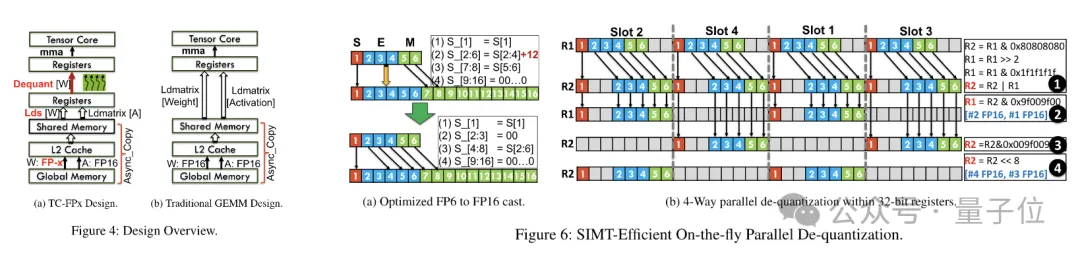
プレパッケージングが完了した後、研究チームは SIMT コアの並列処理機能を使用して、レジスタ内の FP6 重みに対して並列逆量子化を実行し、重みを生成します。 FP16形式。
逆量子化された FP16 重みはレジスタ内で再構築され、Tensor コアに送信されます。再構築された FP16 重みは行列乗算演算を実行して線形層の計算を完了します。
このプロセスでは、チームは SMIT コアの ビットレベル並列処理 を利用して、逆量子化プロセス全体の効率を向上させました。
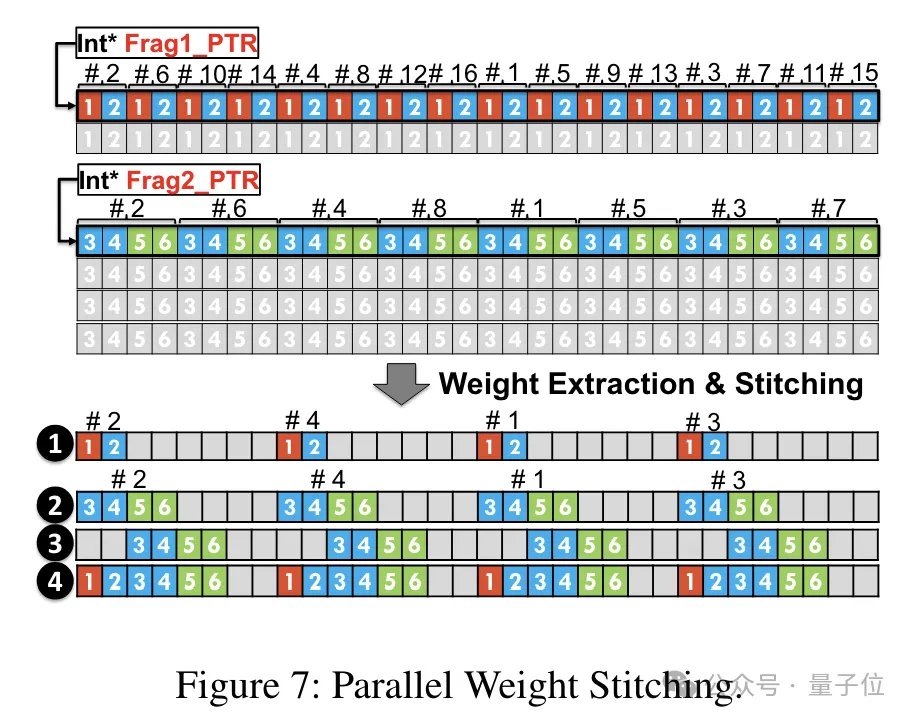
重み再構成タスクを並行して実行できるようにするために、チームは 並列重みスプライシング テクノロジも使用しました。
具体的には、各重みはいくつかの部分に分割され、各部分のビット幅は 2 のべき乗 (6 を 2 4 または 4 2 に分割するなど) になります。
逆量子化する前に、まず重みが共有メモリからレジスタにロードされます。各重みは複数の部分に分割されるため、実行時に完全な重みをレジスタ レベルで再構築する必要があります。
実行時のオーバーヘッドを削減するために、TC-FPx は重みの並列抽出と結合の方法を提案しています。このアプローチでは、2 セットのレジスタを使用して 32 の FP6 重みのセグメントを保存し、これらの重みを並列に再構築します。
同時に、重みの抽出と結合を並行して行うには、初期データ レイアウトが特定の順序要件を満たしていることを確認する必要があるため、TC-FPx は実行前に重みフラグメントを再配置します。
さらに、TC-FPx は、逆量子化ステップと行列乗算演算を組み合わせる ソフトウェア パイプライン も設計しました。 Tensor Core を組み合わせると、命令レベルの並列処理によって全体的な実行効率が向上します。
論文アドレス: https://arxiv.org/abs/2401.14112
以上がLlama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。