
Ethereum Reth が 1 秒あたり 1GB のガスを達成する方法を説明した記事

- WBOY転載
- 2024-04-28 12:46:01966ブラウズ
イーサリアム Reth はどのようにして 1 秒あたり 1 GB のガスを達成するのですか?私たちは、L2 での実行層のスケーリング問題を解決しながら、イーサリアム L1 に弾力性を提供するために、2022 年に Reth の構築を開始しました。本日は、Reth が 2024 年に 1 GB ガス/秒の L2 スループットを達成する計画と、その目標を超えるための長期ロードマップを共有できることを嬉しく思います。私たちはエコシステム全体が暗号通貨のパフォーマンスフロンティアと厳格なベンチマークの推進に参加することを歓迎します。今日は、この Web サイトの編集者が、Reth が 1 秒あたり 1 GB のガスを達成する方法について詳しく紹介します。Ethereum Reth が好きな友人は見逃せないでしょう。
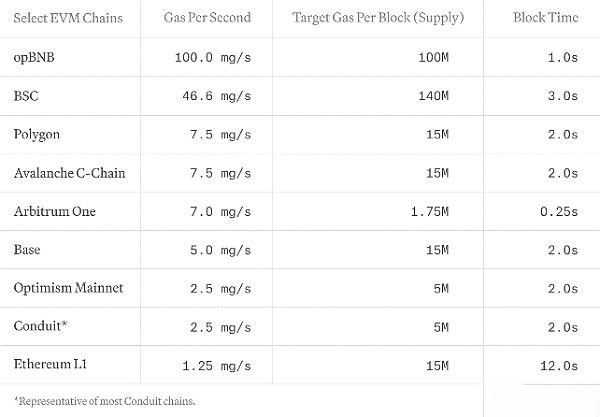
私たちは 1 秒あたりのガスを重視し、コンピューティングとストレージのコストを把握しながら EVM ネットワークのパフォーマンスを包括的に評価するために使用します。 Solana、Sui、Aptos などのネットワークは、独自のコスト モデルのため含まれていません。私たちは、包括的かつ公正な比較を可能にするために、すべてのブロックチェーン ネットワーク全体でコスト モデルを調和させる取り組みを奨励します。
私たちは、実際のワークロードを複製するための Reth 用のノンストップ ベンチマーク ツール スイートを開発中です。ノードに対する要件は、TPC ベンチマークに準拠することです。
2. Reth はどのようにして 1 秒あたり 1GB のガスを達成するのでしょうか?それともさらに高いですか?
2022 年に Reth を作成した動機の 1 つは、Web ロールアップ専用に構築されたクライアントがどうしても必要だったということでした。私たちは、私たちの前進する道は有望であると信じています。
Reth は、ライブ同期中 (送信者の回復、トランザクションの実行、ブロックごとの試行の計算を含む) ですでに 1 秒あたり 100 ~ 200 MB のガスに達しているため、1 秒あたり 1 GB のガスという短期目標を達成するには、スケールする必要があります。さらに10回。
Reth の成長に伴い、拡張計画はスケーラビリティと効率のバランスを見つける必要があります:
垂直方向の拡張: 私たちの目標は、各「ボックス」を最大限に活用して最大限に活用することです。個々のシステムがトランザクションとデータを処理する方法を最適化することで、全体のパフォーマンスを大幅に向上させると同時に、個々のノード オペレーターの効率を高めることができます。
水平スケーリング: 最適化にもかかわらず、Web スケールでの膨大なトランザクション量は単一サーバーの処理能力を超えています。この状況に対処するために、ブロックチェーン ノードの Kubernetes モデルと同様の水平スケーリング アーキテクチャの導入を検討しました。これは、ワークロードを複数のシステムに分散して、どのノードもボトルネックにならないようにすることを意味します。
ここで説明する最適化には、他の記事で別途説明する状態成長ソリューションは含まれません。これを達成するための計画の概要は次のとおりです:
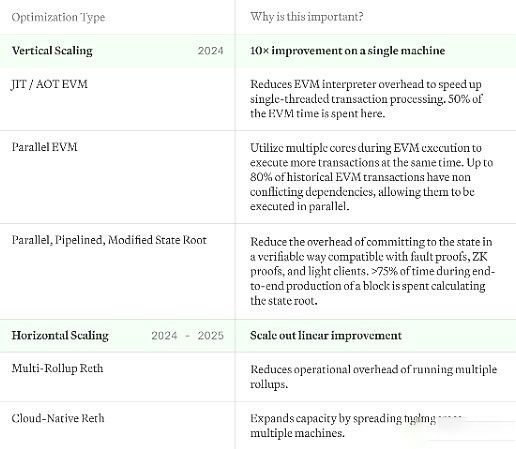
テクノロジー スタック全体を通じて、アクター モデルを使用して IO と CPU も最適化し、スタックの各部分をサービスとしてデプロイできるようにし、きめ細かいその使用を制御します。最後に、私たちは代替データベースを積極的に評価していますが、まだ最終決定には至っていません。
2.1 Reth の垂直スケーリング ロードマップ
私たちの垂直スケーリングの目標は、Reth を実行しているサーバーまたはラップトップのパフォーマンスと効率を最大化することです。
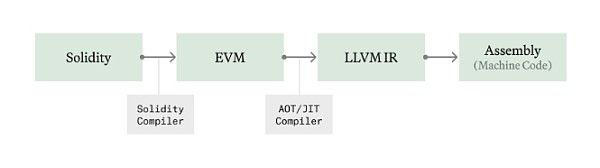
(1) Even (Just-In-Time) EVM と Ahead-of-Time (Ahead-of-Time) EVM
イーサリアム仮想マシン (EVM) のようなブロックチェーン環境では、バイトコードの実行は解釈を通じて行われます。インタプリタ (interpreter)、インタプリタは命令を順番に処理します。この方法では、ネイティブ アセンブリ命令が直接実行されず、操作が VM 層を通じて実行されるため、ある程度のオーバーヘッドが発生します。
ジャストインタイム (JIT) コンパイルは、実行前にバイトコードをネイティブ マシン コードに変換することでこの問題を解決し、それによって VM の解釈プロセスをバイパスすることでパフォーマンスを向上させます。このテクノロジーはコントラクトを事前に最適化されたマシン コードにコンパイルすることができ、Java や WebAssembly などの他の仮想マシンでよく使用されています。
ただし、JIT は、JIT プロセスの脆弱性を悪用するように設計された悪意のあるコードに対して脆弱であるか、実行中にリアルタイムで実行するには遅すぎる可能性があります。 Reth は、最も要求の厳しいコントラクトを事前に (AOT) コンパイルしてディスクに保存し、信頼できないバイトコードがライブ実行中にネイティブ コードのコンパイル プロセスを悪用しようとするのを防ぎます。
私たちは Revm 用の JIT/AOT コンパイラーを開発しており、現在それを Reth と統合しています。今後数週間以内にベンチマークが完了次第、オープンソース化する予定です。平均して、実行時間の約 50% が EVM インタープリタに費やされるため、EVM 実行を約 2 倍改善する必要がありますが、計算要求が大きい場合には、その影響がさらに大きくなる可能性があります。今後数週間にわたって、ベンチマークを共有し、独自の JIT EVM を Reth に統合します。
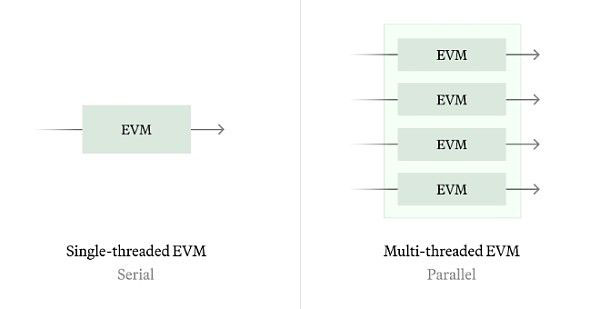
(2) Parallel EVM
Parallel Ethereum Virtual Machine (Parallel EVM) の概念は、従来の EVM シリアル実行モデルとは異なり、複数のトランザクションの同時処理をサポートします。次の 2 つのパスがあります:
履歴同期: 履歴同期を使用すると、履歴トランザクションを分析し、すべての履歴状態の競合を特定することで、可能な限り最適な並列スケジュールを計算できます。
リアルタイム同期: リアルタイム同期の場合、Block STM などのテクノロジーを使用して、追加情報 (アクセス リストなど) なしで投機的実行を実行できます。このアルゴリズムは、状態の競合が激しい間はパフォーマンスが低下するため、ワークロードの状況に基づいてシリアル実行とパラレル実行の切り替えを検討するとともに、どのストレージ スロットがアクセスされるかを静的に予測して並列処理の品質を向上させたいと考えています。
私たちの過去の分析によると、イーサリアムストレージスロットの約80%は独立してアクセス可能であり、これは並列処理によりEVMの実行効率が5倍向上する可能性があることを意味します。
(3) ステートコミットメントの最適化
Reth モデルでは、ステートルートの計算はトランザクションの実行とは独立したプロセスであり、トライ情報を取得せずに標準の KV ストレージを使用できます。現在、ブロックをシールするのにエンドツーエンド時間の 75% を超える時間がかかっており、これは最適化の非常に興味深い領域です。
プロトコルを変更せずにステート ルートのパフォーマンスを 2 ~ 3 倍向上させるための次の 2 つの「簡単な勝利」を特定しました:
ステート ルートを完全に並列化します: ここでは再並列化するだけです 変更されたアカウントのストレージ ツリーを計算しますが、さらに一歩進んで、ストレージ ルート ジョブがバックグラウンドで完了している間に、アカウント ツリーを並行して計算することができます。
パイプライン化されたステート ルート: 実行中に、関連するストレージ スロットとアカウントをステート ルート サービスに通知することによって、中間トライ ノードがディスクからプリフェッチされます。
これに加えて、イーサリアム L1 ステート ルート アクティビティから逸脱して、いくつかのパスを探索することもできます:
より頻繁なステート ルート計算: すべてのブロックでステート ルートを計算するのではなく、すべての T ブロックが一度計算されます。これにより、システム全体のステート ルートへの投資に費やされる合計時間が削減されます。これはおそらく最も単純で効果的なソリューションです。
状態ルートを追跡する: 同じブロック上で状態ルートを計算するのではなく、数ブロック後ろにある状態ルートを計算します。これにより、ステート ルートの計算をブロックすることなく実行を進めることができます。
RLP エンコーダと Keccak256 を置き換える: RLP エンコードを使用するよりも、バイトを直接マージし、Blake3 のような高速なハッシュ関数を使用する方がコストがかからない可能性があります。
より広いトライ: ツリーの子ノードの N-arity を増やして、トライの logN の深さによる IO の増加を削減します。
ここでいくつかの質問があります:
上記の変更による、頻繁なアカウントとストレージの証明に依存するライトクライアント、L2、ブリッジ、コプロセッサ、およびその他のプロトコルに対する二次的な影響は何ですか?
SNARK 証明とネイティブ実行速度のステートコミットメントを同時に最適化できますか?
既存のツールで得られる最も広範な州のコミットメントは何ですか?証人の規模に対する二次的な影響は何ですか?
Reth 2.2 のスケールアウト ロードマップ
私たちは、1 秒あたり 1 GB のガスの目標を達成するために、2024 年を通じて上記の多くを実行する予定です。
ただし、垂直スケーリングは最終的に物理的および実用的な制限に遭遇します。単一のマシンでは世界のコンピューティング ニーズに対応できません。ここには、負荷が増加した後にさらにボックスを導入することで拡張できる 2 つのパスがあると考えています:
(1) 複数のロールアップ Reth
現在の L2 スタックは、チェーンを追跡するために複数のサービスを実行する必要があります: L1 CL、L1 EL、L1 -> L2 派生関数 (おそらく L2 EL にバンドルされる)、および L2 EL。これはモジュール性には優れていますが、複数のノード スタックを実行する場合、状況はさらに複雑になります。 100 個のロールアップを実行する必要があることを想像してみてください。
私たちは、Reth の進化と同時にロールアップをリリースできるようにし、何千ものロールアップを実行する運用コストをほぼゼロに削減したいと考えています。
私たちはすでに実行スケーリングプロジェクトでこれに取り組んでおり、今後数週間でさらに多くのことが行われる予定です。
(2) クラウドネイティブ Reth
高性能ソーターは単一チェーンに多くの要求を抱えている可能性があり、拡張する必要があり、1 台のマシンではニーズを満たすことができません。これは、今日の単一ノードの展開では不可能です。
私たちは、クラウドネイティブな Reth ノードの実行をサポートし、コンピューティングのニーズに基づいて自動的にスケーリングできるサービス スタックとしてデプロイし、一見無制限に見えるクラウド オブジェクト ストレージを永続ストレージとして使用したいと考えています。これは、NeonDB、CockroachDB、Amazon Aurora などのサーバーレス データベース プロジェクトで一般的なアーキテクチャです。

3. 将来の展望
私たちは、このロードマップをすべての Reth ユーザーに徐々に展開していきたいと考えています。私たちの使命は、誰でも 1 秒あたり 1 GB 以上のガスを利用できるようにすることです。私たちは Reth AlphaNet で最適化をテストする予定であり、人々が最適化された高性能ノードを構築するための SDK として Reth を使用することを期待しています。
まだ答えが見つかっていない質問がいくつかあります。
Reth は L2 エコシステム全体のパフォーマンスの向上にどのように役立ちますか?
一般的な最適化で発生する可能性のある最悪のシナリオを適切に測定するにはどうすればよいでしょうか?
L1 と L2 間の潜在的な不一致にどのように対処すればよいでしょうか?
これらの質問の多くにはまだ答えがありませんが、しばらくは忙しくなりそうな有望な初期アイデアがたくさんあり、これらの取り組みが今後数か月間で実を結ぶことを期待しています。
以上がEthereum Reth が 1 秒あたり 1GB のガスを達成する方法を説明した記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。