
 テクノロジー周辺機器AI厳水成氏のリーダーシップの下、崑崙万威2050グローバル研究所はNUSおよびNTUと共同でVitronをリリースし、一般的なビジュアルマルチモーダル大型モデルの究極の形式を確立しました。
テクノロジー周辺機器AI厳水成氏のリーダーシップの下、崑崙万威2050グローバル研究所はNUSおよびNTUと共同でVitronをリリースし、一般的なビジュアルマルチモーダル大型モデルの究極の形式を確立しました。厳水成氏のリーダーシップの下、崑崙万威2050グローバル研究所はNUSおよびNTUと共同でVitronをリリースし、一般的なビジュアルマルチモーダル大型モデルの究極の形式を確立しました。

最近、Yan Shuicheng 教授率いる、Kunlun Wanwei 2050 Global Research Institute、シンガポール国立大学、シンガポール南洋工科大学のチームが共同で をリリースし、オープン ソースVitron ユニバーサル ピクセル レベル ビジュアル マルチモーダル大規模言語モデル。
これは、視覚的な理解から視覚的な生成まで、低レベルから高レベルまでの一連の視覚タスクをサポートし、問題を解決する高耐久の一般的なビジュアル マルチモーダル モデルです。 / 大規模言語モデル業界の長年の問題に対して、静止画像と動的なビデオの理解、生成、セグメンテーション、編集を包括的に統合するピクセルレベルのソリューションを提供します。コンテンツ 一般ビジョン マルチモーダル大規模モデルは、次世代一般ビジョン大規模モデルの究極の形の基礎を築き、一般 人工知能(##AGI)への一歩を示します。 )また大きな一歩。
Vitron は、統合されたピクセル レベルのビジュアル マルチモーダル大規模言語モデルとして、低レベルから高レベルまでのビジュアル タスクの包括的なサポートを実現します。#,複雑な視覚的タスクを処理でき、および画像とビデオのコンテンツを理解して生成し、強力な視覚的理解とタスク実行機能を提供します。 同時に、Vitron はユーザーとの継続的な操作をサポートし、柔軟な人間とコンピューターの対話を可能にし、より統一された視覚的なマルチモーダル ユニバーサル モデルに向けた大きな可能性を実証します。
Vitron 関連の論文、コード、デモ はすべて公開されています これらは包括的な技術革新です。 , 人間とコンピューターの相互作用と応用可能性において実証された独自の利点と可能性は、マルチモーダル大規模モデルの開発を促進するだけでなく、将来の視覚的大規模モデル研究に新たな方向性を提供します。 Kunlun Wanwei2050
Global Research Institute は常に未来の世界のために 優れた企業を構築することに尽力してきました。研究機関、科学コミュニティとともにクロス" 特異点"、探求未知の世界,より良い未来を創造します。 以前、Kunlun Wanwei2050 Global Research Institute は、デジタル エージェントの研究開発ツールキットをリリースし、オープンソース化しました #AgentStudio、今後も、当研究所は人工知能技術的ブレークスルーを推進し、中国の人工知能生態系構築#に貢献していきます。 #### #貢献する。 ビジュアルラージ言語モデル (LLM) の現在の開発は、満足のいく進歩を遂げています。コミュニティでは、より汎用的で強力なマルチモーダル大規模モデル (MLLM) を構築することが汎用人工知能 (AGI) を実現する唯一の方法であるとの考えが高まっています。ただし、マルチモーダルな一般モデル (ジェネラリスト) に移行するプロセスには、依然として重要な課題がいくつかあります。たとえば、作業の大部分は、ピクセルレベルのきめ細かい視覚的理解を達成できていないか、画像とビデオの統一されたサポートが不足しています。あるいは、さまざまな視覚的タスクのサポートが不十分であり、汎用的な大型モデルには程遠いです。 このギャップを埋めるために、最近、Kunlun Worldwide 2050 Global Research Institute、シンガポール国立大学、シンガポール南洋工科大学のチームが共同で、オープンソースの Vitron ユニバーサル ピクセル レベル ビジュアル マルチモーダル大規模言語モデル。 Vitron は、静止画像と動的なビデオ コンテンツの包括的な理解、生成、セグメンテーション、編集を含む、低レベルから高レベルまで、視覚的な理解から視覚的な生成までの一連の視覚タスクをサポートします。
Vitron では、4 つの主要なビジョン関連タスクの機能サポートについて包括的に説明します。そしてその主な利点。 Vitron はまた、ユーザーとの継続的な操作をサポートし、柔軟な人間とコンピューターの対話を実現します。このプロジェクトは、より統合されたビジョン マルチモーダル一般モデルの大きな可能性を実証し、次世代の一般ビジョン大型モデルの究極の形の基礎を築きます。Vitron 関連の論文、コード、デモはすべて公開されました。
論文タイトル: Vitron: 理解、生成、セグメント化、編集のための統合ピクセルレベル ビジョン LLM
プロジェクトのホームページとデモ: https://vitron-llm.github.io / 
- #0
- 1
- 究極の統合マルチモーダル言語モデル
近年、大規模言語モデル (LLM) は前例のない強力な機能を実証しており、AGI への技術的ルートとして徐々に検証されています。マルチモーダル大規模言語モデル (MLLM) は多くのコミュニティで急速に開発されており、視覚認識を実行できるモジュールを導入することにより、強力で画像理解に優れた多くの MLLM が MLLM に拡張されています。 .BLIP-2、LLaVA、MiniGPT-4など。同時に、VideoChat、Video-LLaMA、Video-LLaVA など、ビデオの理解に焦点を当てた MLLM も立ち上げられています。
その後、研究者は主に MLLM の機能を 2 次元からさらに拡張しようとしました。一方で、研究者たちは、GLaMM などの視覚領域位置決め (地域接地) 機能を実現するために、画像についての大まかなインスタンス レベルの理解からピクセル レベルの詳細な理解に移行して、MLLM の視覚についての理解を深めようとしています。 、PixelLM、NExT-Chat、MiniGPT-v2など。一方、研究者たちは、MLLM がサポートできる視覚機能を拡張しようとしています。 MLLM が入力視覚信号を理解するだけでなく、出力視覚コンテンツの生成をどのようにサポートするかを研究する研究も行われ始めています。例えば、GILL や Emu などの MLLM は画像コンテンツを柔軟に生成でき、GPT4Video や NExT-GPT はビデオ生成を実現します。
現在、人工知能コミュニティは、ビジュアル MLLM の将来の傾向が高度に統合され、より強力な機能の方向に必然的に発展するだろうというコンセンサスに徐々に達しています。ただし、コミュニティによって多数の MLLM が開発されているにもかかわらず、明らかなギャップが依然として存在します。
- まず第一に、ほとんどすべての既存のビジュアル LLM は画像とビデオを別のエンティティとして扱い、画像のみまたはビデオのみをサポートします。研究者らは、視覚には静止画像と動的なビデオの両方を含めるべきだと主張しています。これらは両方とも視覚世界の中核的なコンポーネントであり、ほとんどのシナリオで互換性さえあります。したがって、画像とビデオの両方のモダリティをサポートできる統合 MLLM フレームワークを構築する必要があります。
- 第二に、現在、MLLM による視覚機能のサポートはまだ不十分です。ほとんどのモデルは、画像やビデオを理解するか、せいぜい生成することしかできません。研究者らは、将来の MLLM は、より広範囲の視覚タスクと操作をカバーし、すべての視覚関連タスクの統一サポートを実現し、「one for all」機能を実現できる、一般的な大規模言語モデルになるべきだと考えています。これは、実際のアプリケーション、特に一連の反復的でインタラクティブな操作を伴うことが多いビジュアル作成において非常に重要です。たとえば、ユーザーは通常、テキストから始めて、Vincent 図を使用してアイデアをビジュアル コンテンツに変換します。次に、最初のアイデアをさらに詳細に調整し、画像からビデオを生成して動的コンテンツを作成します。ビデオ編集などの反復的な操作を繰り返して、作品を完成させます。

上の表は、既存のビジュアル MLLM の機能を簡単に要約したものです (一部のモデルが代表的に含まれているだけであり、範囲は不完全です)。これらのギャップを埋めるために、チームは一般的なピクセルレベルのビジュアルMLLMであるVitronを提案しています。
02. Vitron システム アーキテクチャ : 3 つの主要モジュール
Vitron 全体のフレームワーク下に示された。 Vitron は、既存の関連する MLLM と同様のアーキテクチャを採用しています。これには、1) フロントエンドのビジュアルおよび言語エンコーディング モジュール、2) 中央の LLM 理解およびテキスト生成モジュール、3) バックエンドのユーザー応答およびビジュアル コントロールのモジュール呼び出しの 3 つの主要な部分が含まれます。モジュール。
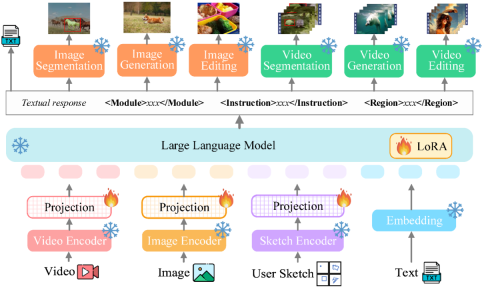
- フロントエンド モジュール: 視覚言語コーディング。画像およびビデオのモーダル信号を認識し、きめ細かいユーザー視覚入力をサポートするために、Vitron は画像エンコーダー、ビデオ エンコーダー、領域ボックス/スケッチ エンコーダーを統合しています。
- 中央モジュール: Core LLM。 Vitron は、理解、推論、意思決定、および複数ラウンドのユーザー インタラクションに Vicuna (7B、1.5) を使用しています。
- バックエンド モジュール: ユーザー応答とモジュール呼び出し。 Vitron は、テキスト中心の呼び出し戦略を採用し、低レベルから高レベルまでの一連のビジュアル端末タスクをデコードして実行するために、いくつかの既製の強力で高度な (SoTA) 画像およびビデオ処理モジュールを統合します。 Vitron は、テキスト中心のモジュール統合呼び出し方式を採用することで、システムの統合を実現するだけでなく、調整効率とシステムの拡張性も確保します。

#03.Vitronモデル トレーニングの 3 段階
上記のアーキテクチャに基づいて、Vitron は強力な視覚的理解とタスク実行機能を提供するためにトレーニングおよび微調整されています。モデルのトレーニングには主に 3 つの異なる段階があります。- ステップ 1: 視覚言語による全体的な調整学習。入力された視覚言語の特徴は統一された特徴空間にマッピングされるため、入力されたマルチモーダル信号を効果的に理解できるようになります。これは、システムが入ってくる視覚信号を全体として効果的に処理できるようにする、粗粒度の視覚と言語の調整学習です。研究者らは、既存の画像とキャプションのペア (CC3M)、ビデオとキャプションのペア (Webvid)、および領域とキャプションのペア (RefCOCO) のデータセットをトレーニングに使用しました。
- ステップ 2: きめ細かい時空間視覚位置指示の微調整。このシステムは外部モジュールを使用してさまざまなピクセル レベルの視覚タスクを実行しますが、LLM 自体は詳細な視覚トレーニングを受けていないため、システムが真のピクセル レベルの視覚的理解を達成することが妨げられます。この目的を達成するために、研究者らは、LLM が画像の詳細な空間性とビデオの特定の時間特性を特定できるようにする、詳細な時空間位置指示の微調整トレーニングを提案しました。 ステップ 3: 出力端はコマンド呼び出しに合わせて微調整されます。上で説明したトレーニングの第 2 段階により、LLM とフロントエンド エンコーダーにピクセル レベルで視覚を理解する能力が与えられます。この最後のステップであるコマンド呼び出しの命令微調整は、コマンドを正確に実行できる機能をシステムに装備し、LLM が適切で正しい呼び出しテキストを生成できるようにすることを目的としています。異なる端末ビジョンタスクには異なる呼び出しコマンドが必要になる可能性があるため、これを統一するために、研究者らは LLM の応答出力を次のような構造化テキスト形式に標準化することを提案しました。
1) ユーザー応答出力、ユーザーの入力に直接応答します。
2) 実行する機能またはタスクを示すモジュール名。
3) コマンドを呼び出して、タスク モジュールのメタ命令をトリガーします。
4) バックエンド モジュールがこの情報を必要とする、ビデオ トラッキングやビジュアル編集などの特定のタスクに必要な詳細なビジュアル機能を指定する領域 (オプションの出力)。領域の場合、LLM のピクセルレベルの理解に基づいて、座標によって記述された境界ボックスが出力されます。

04評価実験研究者は、Vitron に基づいた 22 の一般的なベンチマーク データ セットと 12 の画像/ビデオ ビジョン タスクについて広範な実験評価を実施しました。 Vitron は、4 つの主要なビジュアル タスク グループ (セグメンテーション、理解、コンテンツ生成および編集) で強力な機能を発揮すると同時に、柔軟な人間とコンピューターの対話機能を備えています。以下に代表的な定性的な比較結果を示します。
- 視覚セグメンテーション
 画像参照画像セグメンテーションの結果
画像参照画像セグメンテーションの結果
- 詳細な視覚理解
 画像参照表現理解の結果。
画像参照表現理解の結果。
 ビデオ QA の結果。
ビデオ QA の結果。
- ビジョン生成

- ビジョン編集
 画像編集結果
画像編集結果
さらに詳しい実験内容や詳細については、こちらのステップをご覧ください。論文。
05 今後の方向性 全体として、この研究は、の大きな可能性を示しています。統合された視覚マルチモーダル一般大型モデルの開発は、次世代視覚大型モデルの研究に新しい形を築き、この方向への第一歩を踏み出しました。チームが提案した Vitron システムは強力な一般的な機能を示していますが、それでも独自の制限があります。以下の研究者は、将来さらに研究される可能性のあるいくつかの方向性を列挙しています。
- システム アーキテクチャ
Vitron システムでは、引き続きセミジョイント、セミエージェントのアプローチを使用して外部ツールを呼び出します。この呼び出しベースの方法は、潜在的なモジュールの拡張と置き換えを容易にしますが、このパイプライン構造のバックエンド モジュールがフロントエンド モジュールと LLM コア モジュールの共同学習に参加しないことも意味します。この制限はシステム全体の学習には役立たないため、さまざまな視覚タスクのパフォーマンスの上限がバックエンド モジュールによって制限されることになります。将来の作業では、さまざまなビジョン タスク モジュールを 1 つのユニットに統合する必要があります。単一の生成パラダイムを通じて生成および編集機能をサポートしながら、画像とビデオの統一された理解と出力を実現することは、依然として課題です。現在、有望なアプローチは、モジュール性永続的なトークン化を組み合わせて、さまざまな入出力およびさまざまなタスクにおけるシステムの統合を向上させることです。
- ユーザー対話機能
単一の視覚タスク (安定拡散や SEEM など) に焦点を当てた以前のモデルとは異なり、Vitron は、 LLM とユーザー間の詳細なインタラクションは、業界における OpenAI の DALL-E シリーズ、Midjourney などに似ています。最適なユーザー対話性を実現することが、この作業の中心的な目標の 1 つです。 Vitron は、既存の言語ベースの LLM を適切な命令調整と組み合わせて活用し、一定レベルの対話性を実現します。たとえば、システムは、ユーザー入力がバックエンド モジュールの条件と正確に一致する必要がなく、ユーザーが入力する予期されるメッセージに柔軟に応答し、対応する視覚的な操作結果を生成できます。ただし、この作業にはインタラクティブ性の向上という点でまだ改善の余地が多く残されています。たとえば、クローズドソースの Midjourney システムからインスピレーションを得て、LLM が各ステップでどのような決定を下しても、システムはユーザーに積極的にフィードバックを提供して、そのアクションと決定がユーザーの意図と一致していることを確認する必要があります。
モーダル機能
現在、Vitron は 7B Vicuna モデルを統合しており、言語、画像、ビデオを理解する機能がある可能性があります。適用する。将来の探求の方向性としては、ビジョンをより徹底的かつ包括的に理解するためにモデルの規模を拡大するなど、包括的なエンドツーエンドのシステムを開発することが考えられます。さらに、LLM が画像とビデオのモダリティの理解を完全に統一できるようにするための努力が必要です。
以上が厳水成氏のリーダーシップの下、崑崙万威2050グローバル研究所はNUSおよびNTUと共同でVitronをリリースし、一般的なビジュアルマルチモーダル大型モデルの究極の形式を確立しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AM
AI内部展開の隠された危険:ガバナンスのギャップと壊滅的なリスクApr 28, 2025 am 11:12 AMApollo Researchの新しいレポートによると、高度なAIシステムの未確認の内部展開は、重大なリスクをもたらします。 主要なAI企業の間で一般的なこの監視の欠如は、Uncontに及ぶ潜在的な壊滅的な結果を可能にします
 AIポリグラフの構築Apr 28, 2025 am 11:11 AM
AIポリグラフの構築Apr 28, 2025 am 11:11 AM従来の嘘検出器は時代遅れです。リストバンドで接続されたポインターに依存すると、被験者のバイタルサインと身体的反応を印刷する嘘発見器は、嘘を識別するのに正確ではありません。これが、嘘の検出結果が通常裁判所で採用されない理由ですが、多くの罪のない人々が投獄されています。 対照的に、人工知能は強力なデータエンジンであり、その実用的な原則はすべての側面を観察することです。これは、科学者がさまざまな方法で真実を求めるアプリケーションに人工知能を適用できることを意味します。 1つのアプローチは、嘘発見器のように尋問されている人の重要な符号応答を分析することですが、より詳細かつ正確な比較分析を行います。 別のアプローチは、言語マークアップを使用して、人々が実際に言うことを分析し、論理と推論を使用することです。 ことわざにあるように、ある嘘は別の嘘を繁殖させ、最終的に
 AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AM
AIは航空宇宙産業の離陸のためにクリアされていますか?Apr 28, 2025 am 11:10 AMイノベーションの先駆者である航空宇宙産業は、AIを活用して、最も複雑な課題に取り組んでいます。 近代的な航空の複雑さの増加は、AIの自動化とリアルタイムのインテリジェンス機能を必要とします。
 北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AM
北京の春のロボットレースを見ていますApr 28, 2025 am 11:09 AMロボット工学の急速な発展により、私たちは魅力的なケーススタディをもたらしました。 NoetixのN2ロボットの重量は40ポンドを超えており、高さは3フィートで、逆流できると言われています。 UnitreeのG1ロボットの重量は、N2のサイズの約2倍で、高さは約4フィートです。また、競争に参加している多くの小さなヒューマノイドロボットがあり、ファンによって前進するロボットさえあります。 データ解釈 ハーフマラソンは12,000人以上の観客を惹きつけましたが、21人のヒューマノイドロボットのみが参加しました。政府は、参加しているロボットが競争前に「集中トレーニング」を実施したと指摘したが、すべてのロボットが競争全体を完了したわけではない。 チャンピオン - 北京ヒューマノイドロボットイノベーションセンターによって開発されたティアンゴニ
 ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM
ミラートラップ:AI倫理と人間の想像力の崩壊Apr 28, 2025 am 11:08 AM人工知能は、現在の形式では、真にインテリジェントではありません。既存のデータを模倣して洗練するのに熟達しています。 私たちは人工知能を作成するのではなく、人工的な推論を作成しています。情報を処理するマシン、人間は
 新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AM
新しいGoogleリークは、便利なGoogle写真機能の更新を明らかにしますApr 28, 2025 am 11:07 AMレポートでは、更新されたインターフェイスがGoogle Photos Androidバージョン7.26のコードに隠されていることがわかり、写真を見るたびに、新しく検出された顔のサムネイルの行が画面の下部に表示されます。 新しいフェイシャルサムネイルには名前タグが欠落しているため、検出された各人に関する詳細情報を見るには、個別にクリックする必要があると思います。今のところ、この機能は、Googleフォトが画像で見つけた人々以外の情報を提供しません。 この機能はまだ利用できないため、Googleが正確にどのように使用するかはわかりません。 Googleはサムネイルを使用して、選択した人のより多くの写真を見つけるためにスピードアップしたり、編集して個人を選択するなど、他の目的に使用することもできます。待って見てみましょう。 今のところ
 補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM
補強能力のガイド - 分析VidhyaApr 28, 2025 am 09:30 AM補強能力は、人間のフィードバックに基づいて調整するためにモデルを教えることにより、AI開発を揺さぶりました。それは、監督された学習基盤と報酬ベースの更新をブレンドして、より安全で、より正確に、そして本当に助けます
 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 中国語版
中国語版、とても使いやすい

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。
ホットトピック
 7814
7814 15164614140252130025123629
15164614140252130025123629