

8B テキスト マルチモーダル大規模モデル インデックスは、Byte、Huashan、Huake が共同で提案した TextSquare に近いものです。


AIxiv コラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、記事を投稿するか、報告用メールアドレスにご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
最近、マルチモーダル大規模モデル (MLLM) は、テキスト中心の VQA の分野、特に GPT4V や Gemini などの複数のクローズドソース モデルで大きな進歩を遂げています。そして、いくつかの面では人間の能力を超えたパフォーマンスを実証しました。しかし、オープンソース モデルのパフォーマンスは依然としてクローズド ソース モデルに比べてはるかに遅れています。最近、MonKey、LLaVAR、TG-Doc、ShareGPT4V などの多くの画期的な研究が、不十分な命令の問題に焦点を当て始めています。チューニングデータ。これらの取り組みは顕著な成果を上げていますが、画像記述データと VQA データが異なるドメインに属しており、画像コンテンツの表現の粒度や範囲に不一致があるなど、依然としていくつかの問題があります。さらに、合成データのサイズが比較的小さいため、MLLM の可能性を最大限に発揮することができません。

論文タイトル: TextSquare: テキスト中心の視覚的命令チューニングのスケールアップ
論文アドレス: https ://arxiv.org/abs/2404.12803
これを削減するには
VQAデータ生成
スクエア戦略アプローチそれには、自問、自己回答、推論、自己評価の 4 つのステップが含まれます。 Self-Questioning は、テキストと画像の分析と理解における MLLM の機能を活用して、画像内のテキスト コンテンツに関連する質問を生成します。自己応答では、CoT やフューショットなどのさまざまなプロンプト手法を使用して、これらの質問に対する回答が提供されます。 Self-Reasoning は、MLLM の強力な推論機能を使用して、モデルの背後にある推論プロセスを生成します。自己評価では、質問の妥当性、画像テキストの内容との関連性、回答の正確性を評価することで、データの品質を向上させ、偏見を軽減します。

研究者らは、Square 法に基づいて、自然の風景、チャート、フォーム、Square-10M などのさまざまな公開ソースから大量のテキストを含む多様な画像セットを収集しました。は領収書、書籍、PPT、PDF などを使用して構築され、テキスト理解に重点を置いた MLLM である TextSquare-8B は、このデータセットに基づいてトレーニングされました。
図 1 に示すように、TextSquare-8B は複数のベンチマークで GPT4V や Gemini と同等以上の結果を達成でき、他のオープンソース モデルを大幅に上回っています。 TextSquare の実験では、VQA タスクに対する推論データのプラスの影響が検証され、幻覚を軽減しながらモデルのパフォーマンスを向上させる能力が実証されました。
さらに、大規模なデータセットを利用することで、命令調整データサイズ、学習収束損失、モデルパフォーマンスの関係が明らかになります。少量の命令調整データでも MLLM を適切にトレーニングできますが、命令調整データが拡大し続けると、モデルのパフォーマンスをさらに向上させることができ、命令微調整データとモデルの間には対応するスケーリング則も存在します。 。


## 図 3 1,000 万平方の画像配信と QA 配信およびその他の詳細 データ収集
データ収集戦略の主な目標は、現実世界のテキストが豊富なシナリオを広範囲にカバーすることです。この目的を達成するために、研究者らは 380 万枚のテキストが豊富な画像を収集しました。これらの画像はさまざまな特性を示します。たとえば、チャートや表は、緻密な統計情報を含むテキスト要素に焦点を当てており、PPT、スクリーンショット、および Web イメージは、テキストと強調表示された視覚情報との間の相互作用のために設計されており、画像が含まれています。自然の風景から派生した詳細で密度の高いストリートビューのテキスト。収集された画像は現実世界のテキスト要素のマッピングを形成し、テキスト中心の VQA を研究するための基礎を形成します。
データ生成
研究者は、Gemini Pro のマルチモーダル理解機能を使用して、特定のデータ ソースから画像を選択し、自問、自問、自問の 3 つの段階を経ます。および自己推論 VQA と推論コンテキストのペアを生成します。
自問: この段階で、Gemini Pro はこれらのプロンプトに基づいて画像の包括的な分析を実行し、意味のあるものを生成します。問題の理解に基づいた情報。一般的な MLLM のテキスト要素を理解する能力は通常、ビジュアル モデルの能力よりも弱いことを考慮して、抽出されたテキストを特殊な OCR モデルを通じてプロンプトに前処理します。
自己回答: Gemini Pro は、思考連鎖 (CoT) や少数ショット プロンプトなどのテクノロジーを使用して、質問を生成する際のコンテキスト情報を強化します。生成された回答の信頼性。
自己推論: このステージでは、答えの詳細な理由が生成され、Gemini Pro は問題と視覚的要素の間の関係についてさらに考えることが求められます。錯覚を減らし、正確な回答を向上させます。
データ フィルタリング
自問、回答、推論は有効ですが、生成された画像とテキストのペアは、錯覚的なコンテンツに直面する可能性があります。質問と間違った答えを意味します。したがって、LLM の評価機能に基づいてフィルタリング ルールを設計し、高品質の VQA ペアを選択します。
自己評価 ヒント Gemini Pro と他の MLLM は、生成された質問が意味があるかどうか、またその回答が問題を正しく解決するのに十分であるかどうかを判断します。
マルチプロンプトの一貫性 研究者は、生成されたコンテンツを直接評価することに加えて、データ生成時にプロンプトとコンテキスト空間を手動で追加します。正しく意味のある VQA ペアは、異なるプロンプトが提供された場合でも意味的に一貫している必要があります。
マルチコンテキストの一貫性 研究者は、質問の前にさまざまなコンテキスト情報を準備することで、VQA ペアをさらに検証しました。
#TextSquare-8B
TextSquare-8B は、CLIP ViT-L-14 のビジョンを含む、InternLM-Xcomposer2 のモデル構造を利用しています。 -336 エンコーダ、画像解像度がさらに 700 に向上、InternLM2-7B-ChatSFT に基づく大規模言語モデル LLM、ビジュアル トークンとテキスト トークンを調整するブリッジ プロジェクター。 TextSquare-8B のトレーニングには、SFT の 3 つのステージが含まれています。 最初のステージでは、解像度 490 のフル パラメーター (ビジョン エンコーダー、プロジェクター、LLM) を使用してモデルを微調整します。 第 2 段階では、入力解像度が 700 に増加され、ビジョン エンコーダーのみが解像度の変更に適応するようにトレーニングされます。 第 3 段階では、すべてのパラメータが解像度 700 でさらに微調整されます。 TextSquare は、Square-10M データセットに基づいて、8B パラメーターと通常サイズの画像解像度を持つモデルが、テキスト中心の VQA の効果 ( GPT4V、Gemini Pro)。実験結果
図 4(a) は、TextSquare が単純な算術関数を備えていることを示しています。図 4(b) は、テキストの内容を理解し、密なテキスト内のおおよその位置を提供する機能を示しています。図 4(c) は、テーブル構造を理解する TextSquare の機能を示しています。

- ##ドキュメント指向のベンチマーク
- は、ドキュメント シーンの VQA ベンチマーク (DocVQA、ChartQA、InfographicVQA) で平均 3.5% の向上を達成しました。これは、すべてのオープン ソース モデルよりも優れており、ChartQA データ セットでは GPT4V および Gemini Pro よりわずかに高くなります。このモデルの解像度はわずか 700 で、ほとんどのドキュメント指向の MLLM よりも小さいですが、解像度がさらに向上すれば、モデルのパフォーマンスもさらに向上すると思います。Monkey はこれを証明しました。
- 自然シーンの VQA ベンチマーク (TextVQA、AI2D) では SOTA 効果が得られていますが、以前と比較して大きな改善はありません。ベースライン Xcomposer2 。これはおそらく、Xcomposer2 が高品質のドメイン内データを使用して完全に最適化されているためです。
- テーブル シナリオの VQA ベンチマーク (WTQ、TabFact) では、結果は GPT4V と Gemini Pro をそれぞれ大きく上回り、他の SOTA を上回りましたモデルは 3% 増加します。
テキスト中心の KIE ベンチマーク KIE タスクのベンチマーク (SROIE、POIE) からテキスト中心の重要な情報を抽出し、KIE タスクを VQA タスクに変換しますどちらのデータセットでも、平均 14.8% の改善で最高のパフォーマンスが達成されました。
OCRBench テキスト認識、数式認識、テキスト中心の VQA、KIE などの 29 個の OCR 関連評価タスクが含まれており、最高のパフォーマンスを実現します。オープンソースモデル、および約10Bのパラメータボリュームが600ポイントに達する最初のモデルになります。

##一般的な VQA および幻覚評価ベンチマーク 一般的な VQA ベンチマーク (VizWiz VQAv2、GQA、TextSquare POPE) は、Xconposer2 と比べて大きな低下はなく、VisWiz および POPE で最高のパフォーマンスを維持しており、最高の方法よりも 3.6% 高く、この方法の有効性がモデルの幻覚を軽減できることがわかります。
アブレーション実験



データ スケールと収束損失とモデルのパフォーマンスの関係

概要
この論文では、研究者らは、これを使用して高品質のテキスト中心の命令チューニング データ セット (Square-10M) を構築する Square 戦略を提案しました。データセットである TextSquare-8B は、複数のベンチマークで GPT4V に匹敵するパフォーマンスを達成し、さまざまなベンチマークで最近リリースされたオープンソース モデルを大幅に上回ります。 さらに、研究者らは、命令調整データセットのサイズ、収束損失、モデルのパフォーマンスの関係を導き出し、より大きなデータセットを構築する道を切り開き、データの量と質がモデルに重要な影響を与えることを確認しました。重要なパフォーマンス。 最後に、研究者らは、データの量と質をさらに改善してオープンソース モデルと主要なモデルの間の差を縮める方法は、非常に有望な研究方向であると考えられると指摘しました。以上が8B テキスト マルチモーダル大規模モデル インデックスは、Byte、Huashan、Huake が共同で提案した TextSquare に近いものです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、
 Openaiを使用した3つの実験的な実験' s O1を確認する必要があります-AnalyticsVidhyaApr 13, 2025 am 11:06 AM
Openaiを使用した3つの実験的な実験' s O1を確認する必要があります-AnalyticsVidhyaApr 13, 2025 am 11:06 AM導入 あなたが話す前に、あなたはどれくらいの頻度で本当に考え、推論しますか?現在の最先端のLLMであるGPT-4Oは、多くの時間をかけて応答することなく、すでに印象的な反応を提供していました。しかし、それが取られ始めたら想像してみてください
 Openai O1にアクセスする方法は? - 分析VidhyaApr 13, 2025 am 11:05 AM
Openai O1にアクセスする方法は? - 分析VidhyaApr 13, 2025 am 11:05 AM導入 ストロベリーは市場に出ています!!!他のOpenaiの最新モデルによってもたらされた人工知能の最近の進歩と同じくらい実り多いものになることを願っています。 私たちは長い間GPT-5を待っていました
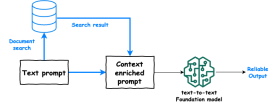 LlamainDexを使用したマルチドキュメントエージェントRAGの構築Apr 13, 2025 am 11:03 AM
LlamainDexを使用したマルチドキュメントエージェントRAGの構築Apr 13, 2025 am 11:03 AM導入 人工知能の急速に進化する分野では、膨大な量の情報を処理および理解する能力がますます重要になっています。マルチドキュメントエージェントラグ - 強力なアプリを入力します
 SQLを無料で学習するYouTubeチャネル - 分析VidhyaApr 13, 2025 am 10:46 AM
SQLを無料で学習するYouTubeチャネル - 分析VidhyaApr 13, 2025 am 10:46 AM導入 SQL(構造化されたクエリ言語)のマスタリングは、データ管理、データ分析、およびデータベース管理を追求する個人にとって重要です。あなたが初心者として始めている場合、または改善を求めているベテランのプロである場合、
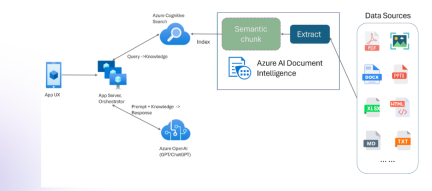 マルチモダリティとAzure Document Intelligenceを備えたRAGApr 13, 2025 am 10:38 AM
マルチモダリティとAzure Document Intelligenceを備えたRAGApr 13, 2025 am 10:38 AM導入 データに基づいて動作する現在の世界では、リレーショナルAIグラフ(RAG)は、データを相関させ、関係をマッピングすることにより、業界に多くの影響を及ぼします。しかし、もう少しもっと行くことができたらどうでしょう


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ドリームウィーバー CS6
ビジュアル Web 開発ツール

