
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
- 論文リンク: https://arxiv.org/abs/2403.12494
- コードリンク: https://github.com/YangSun22/TC-MoA
- 論文タイトル:一般的な画像融合用のタスクにカスタマイズされたアダプターの混合
融合 図 1 融合結果の支配的な強度変化に関するさまざまな融合タスクのソース画像
研究の背景と動機
画像融合の目的は、同じシーン内の異なるセンサーをキャプチャすることです複数のソース画像の補完情報を 1 つの画像に統合します。この方法は通常、画像から重要な情報を抽出し、視覚的な品質を向上させるために使用されます。 現在、一般的な画像融合には主にマルチモーダル、多重露出、多焦点画像融合などが含まれます。融合タスクはさまざまな融合メカニズムを示します。多重露出イメージ フュージョン (MEF) は、複数の露出レベルを持つイメージ シーケンスを高品質の完全露出イメージに変換することに重点を置いています。各ソース画像は、独自の照明と構造情報を融合画像に提供します。可視赤外画像融合 (VIF) は、赤外モダリティと可視モダリティからの相補的な情報を融合して、堅牢で情報量の多い融合画像を生成することを目的としたマルチモーダル画像融合 (MMF) の一種です。赤外線画像はより多くの強度情報を提供し、可視画像はより多くのテクスチャおよび勾配情報を提供します。マルチフォーカス イメージ フュージョン (MFF) の目的は、部分的に焦点が合った一連の画像から完全に焦点が合った画像を生成することです。多焦点融合画像の各クリア領域は通常、1 つのソース画像から学習するだけで済みます。したがって、MEF タスクと VIF タスクは複数のソースを比較的均等に融合したものであるのに対し、MFF はより極端なマルチソース ステータスを持つタスクであり、多くの場合、画像の特定の領域で偏った選択を示していることがわかります。 ディープラーニング技術の急速な発展により、近年画像融合の分野で大きな進歩が見られましたが、既存の手法のほとんどは、通常は特定の戦略を使用した単一の画像融合シナリオにのみ焦点を当てています。特定のタスクなど、単一のタスク用。タスク用に設計された複雑なネットワークまたはタスク固有の損失関数により、他のタスクに直接適用することができません。異なるフュージョンタスクの本質は同じである、つまり、複数のソース画像からの重要な情報を統合することを考慮して、最近提案されたいくつかの方法は、統一されたモデルを使用して複数のフュージョンタスクを処理し、普遍的な画像フュージョンを構築しようとしています。ただし、これらの方法では、タスクが支配的なバイアスが発生するか、マルチタスクの共通性のために個性が犠牲になるため、最適なパフォーマンスが得られません。これは、さまざまな核融合シナリオと適応的かつ動的に互換性のある、より互換性のある核融合パラダイムを探求する動機になります。 この課題に対処するために、事前トレーニングされたベース モデルの強力な特徴表現機能に触発されて、マルチソース画像の相補的な特徴を抽出するためのフリーズ エンコーダーとしてベース モデルを導入します。既存のほとんどの方法とは異なり、私たちは混合エキスパート (MoE) のアイデアを活用し、各エキスパートを効率的に微調整されたアダプターとして扱い、基本モデルに基づいて適応的な視覚特徴キュー フュージョンを実行します。タスク固有のルーティング ネットワークは、これらのアダプターの組み合わせを調整して、さまざまなソースに対するタスク固有のフュージョン キューを生成し、新しいタスク カスタマイズ ハイブリッド アダプター (TC-MoA) アーキテクチャを形成します。さらに、相互情報量の正則化を設計して融合キューを制約し、さまざまなソースへの相補性を確保します。注目すべきことに、融合キューには重要なタスクバイアスとモダリティ優勢強度の差があった。図 1 に示すように、MFF キューの色差は VIF および MEF よりも大きく、ドミナント モードの強度バイアスにおいて特徴選択がより双極性であることを示しています。私たちのモデルは、単一モデル内の異なる融合タスク間の融合強度の偏りを効果的に認識するため、より広範囲の融合タスクと互換性があります。 広範な実験により、マルチモーダル、多重露出、多焦点融合を含む一般的な画像融合における当社の優位性が実証されました。さらに重要なことに、当社の TC-MoA は、未知の融合タスクに対しても創造的な制御性と一般化を示し、より幅広い融合シナリオで当社の可能性を十分に発揮します。 主な貢献
私たちは、適応型マルチソース画像融合のための新しいタスクに合わせたハイブリッドアダプター(TC-MoA)を提供する、統合された一般的な画像融合モデルを提案します(動的集約の利点を活用)それぞれのスキーマからの有効な情報)。
- アダプターの相互情報量正則化方法を提案します。これにより、モデルがさまざまなソース画像の支配的な強度をより正確に識別できるようになります。
- 私たちの知る限り、私たちは初めて MoE ベースの柔軟なアダプターを提案します。学習可能なパラメーターの 2.8% を追加するだけで、私たちのモデルは多くの融合タスクを処理できます。広範な実験により、競合する手法の利点が実証され、同時に大幅な制御性と一般化が示されました。
図 2 に示すように、ソース画像のペア が与えられると、ネットワークは異なるソースからの相補的な情報を統合して、融合画像 を取得します。ソース画像を ViT ネットワークに入力し、パッチ エンコーディング層を通じてソース画像のトークンを取得します。 ViT は、特徴抽出を行うエンコーダと画像再構成を行うデコーダから構成され、どちらも Transformer ブロックで構成されます。 エンコーダーとデコーダーの Transformer ブロックごとに 1 つの TC-MoA を挿入します。ネットワークは、これらの TC-MoA を通じて融合の結果を段階的に調整します。各 TC-MoA は、タスク固有のルーター バンク 、タスク共有アダプター バンク 、およびヒント融合層 F で構成されます。 TC-MoA は、キューの生成とキュー駆動の融合という 2 つの主要な段階で構成されます。表現を容易にするために、VIF を例として取り上げ、入力が VIF データセットからのものであると仮定し、G を使用して を表します。 O 図 2 TC-MOA の全体的なアーキテクチャ
を生成するためのリマインダー。まず、後続の処理のためにマルチソースの特徴が取得されます。 j番目のTC-MoA以前のネットワーク構造を、抽出されたキュー生成特徴量を
とする。 をマルチソース トークン ペアの特徴表現として連結します。これにより、さまざまなソースからのトークンが後続のネットワーク内で情報を交換できるようになります。ただし、高次元の連結特徴を直接計算すると、不要なパラメータが大量に発生します。したがって、次のように を使用して特徴の次元削減を実行し、処理されたマルチソース特徴
を取得します。 次に、Φ が属するタスクに従って、ルーター バンクからタスク固有のルーターを選択します。ルーティング スキームをカスタマイズします。つまり、ソース トークンの各ペアに対してアダプター バンク内のどのアダプターを入力する必要があります。 最後に、アダプターの出力の加重合計を実行して、融合のヒントを取得します。各ルーターには、適切なアダプターの組み合わせをカスタマイズするためのタスク設定があり、アダプターの組み合わせから次のように計算されたヒントが生成されます:
ヒント主導型フュージョン。タスクに合わせたキューは相互情報正則化 (MIR) の対象となり、さまざまなソースとの相補性が保証されます。したがって、手がかりは、各ソース内の重要な情報の割合の推定として機能します。マルチソースの特徴とキューの内積を通じて、冗長な情報を削除しながら補完的な情報を保持します。次に、特徴表現にはソースに依存するバイアス (可視画像や赤外線画像など) が含まれるべきであることを考慮して、各ソースに対して入力に依存しない学習可能なパラメーター、つまりソース エンコーディングを導入します。ヒントとソース バイアスによって特徴が変更された後、洗練されたソース特徴を取得し、次に融合層 F を通じて融合特徴を取得します。プロセスは次のとおりです。
最後に、融合特徴を取得します。タスクに合わせてカスタマイズされたヒント。モデルが重要な情報を段階的に抽出できるようにするために、次の Transformer ブロックに出力する特徴量を次のように定義します (
はハイパーパラメーター):
Mutual Information Regular。マルチソース特徴からの冗長な情報を破棄しながら、モデルが相補的な情報を動的に保持することを保証するために、プロンプトに正則化制約を課します。特徴表現が線形に変化すると仮定して、MIR を次のように定義します:
定性的および定量的実験。 図 3-5 および表 1-3 に示すように、3 つのフュージョン タスクの定性的および定量的比較は、私たちの手法のパフォーマンスが以前の一般的なフュージョン手法を上回っていることを示しています。タスク固有の手法と比較して、私たちの手法はすべてのタスクで最先端のパフォーマンスを実現し、一部のタスク (VIF) ではさらに優れています。提案手法の優位性が証明された。図 3 VIF タスク LLVIP データセット 定性的比較実験
図 4 MEF タスク MEFB データセット 定性的比較実験
表 1 VIF タスク LLVIP データセットの定量的比較実験
表 2 MEF タスク LLVIP データセットの定量的比較実験
表 3 MFF タスク LLVIP データセット LLVIP データセットの定量的比較実験
図 6未知のタスクに対する制御性と一般化
。
図 6 に示すように、融合プロンプトのハイパーパラメータ α と β を制御することで、ソース画像の補完情報 (領域レベル) に対するモデルの特徴選択強度と、融合画像と融合画像間の類似性をそれぞれ制御できます。特定のソース画像 (画像レベル)。線形変換を通じてキューを融合し、最終的にカスタマイズされた融合画像を生成できます。多重露出フュージョンなどの既知のタスクでは、人間の知覚に最も適合するカスタマイズされたフュージョン結果を取得できます。未知のタスクの場合、最も適切な融合パラメーターを調整し、モデルを未知のタスクに一般化できます。 以上がCVPR 2024 | MoE に基づく一般的な画像融合モデル。複数のタスクを完了するために 2.8% のパラメータを追加の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





 が与えられると、ネットワークは異なるソースからの相補的な情報を統合して、融合画像
が与えられると、ネットワークは異なるソースからの相補的な情報を統合して、融合画像 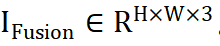 を取得します。ソース画像を ViT ネットワークに入力し、パッチ エンコーディング層を通じてソース画像のトークンを取得します。 ViT は、特徴抽出を行うエンコーダと画像再構成を行うデコーダから構成され、どちらも Transformer ブロックで構成されます。
を取得します。ソース画像を ViT ネットワークに入力し、パッチ エンコーディング層を通じてソース画像のトークンを取得します。 ViT は、特徴抽出を行うエンコーダと画像再構成を行うデコーダから構成され、どちらも Transformer ブロックで構成されます。  Transformer ブロックごとに 1 つの TC-MoA を挿入します。ネットワークは、これらの TC-MoA を通じて融合の結果を段階的に調整します。各 TC-MoA は、タスク固有のルーター バンク
Transformer ブロックごとに 1 つの TC-MoA を挿入します。ネットワークは、これらの TC-MoA を通じて融合の結果を段階的に調整します。各 TC-MoA は、タスク固有のルーター バンク  、タスク共有アダプター バンク
、タスク共有アダプター バンク  、およびヒント融合層 F で構成されます。 TC-MoA は、キューの生成とキュー駆動の融合という 2 つの主要な段階で構成されます。表現を容易にするために、VIF を例として取り上げ、入力が VIF データセットからのものであると仮定し、G を使用して
、およびヒント融合層 F で構成されます。 TC-MoA は、キューの生成とキュー駆動の融合という 2 つの主要な段階で構成されます。表現を容易にするために、VIF を例として取り上げ、入力が VIF データセットからのものであると仮定し、G を使用して  を表します。 O 図 2 TC-MOA の全体的なアーキテクチャ
を表します。 O 図 2 TC-MOA の全体的なアーキテクチャ 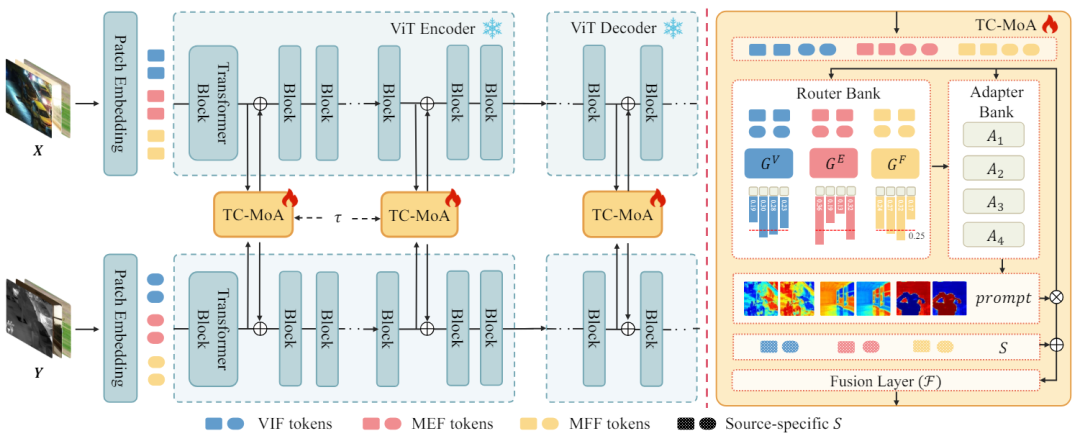


 次に、Φ が属するタスクに従って、ルーター バンクからタスク固有のルーターを選択します。ルーティング スキームをカスタマイズします。つまり、ソース トークンの各ペアに対してアダプター バンク内のどのアダプターを入力する必要があります。
次に、Φ が属するタスクに従って、ルーター バンクからタスク固有のルーターを選択します。ルーティング スキームをカスタマイズします。つまり、ソース トークンの各ペアに対してアダプター バンク内のどのアダプターを入力する必要があります。 

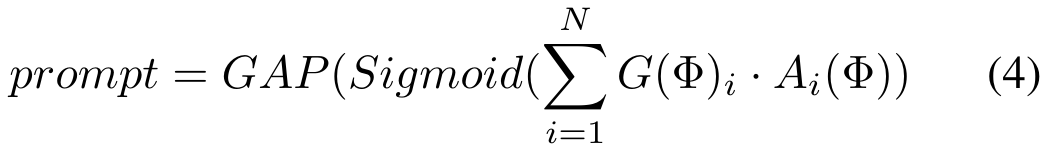

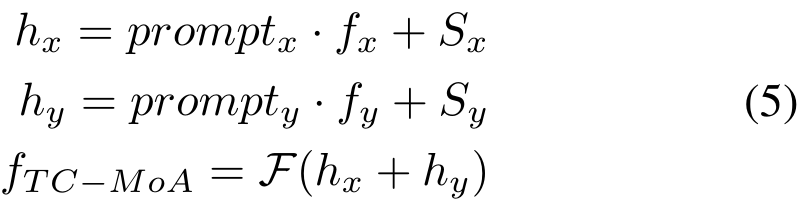

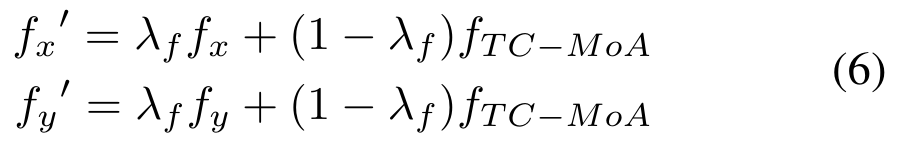




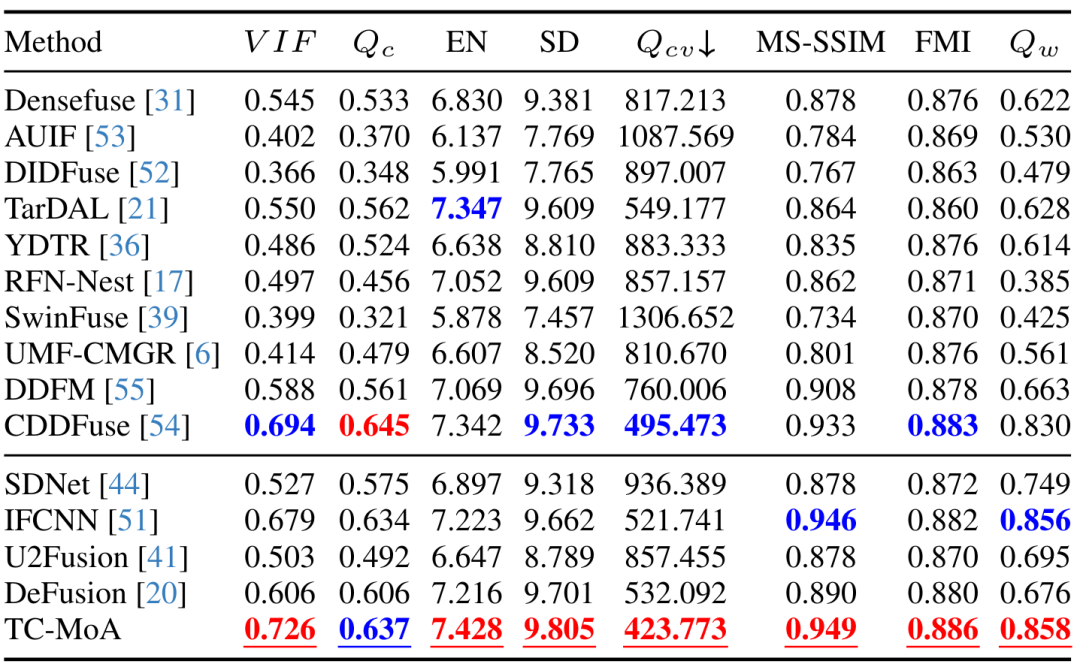
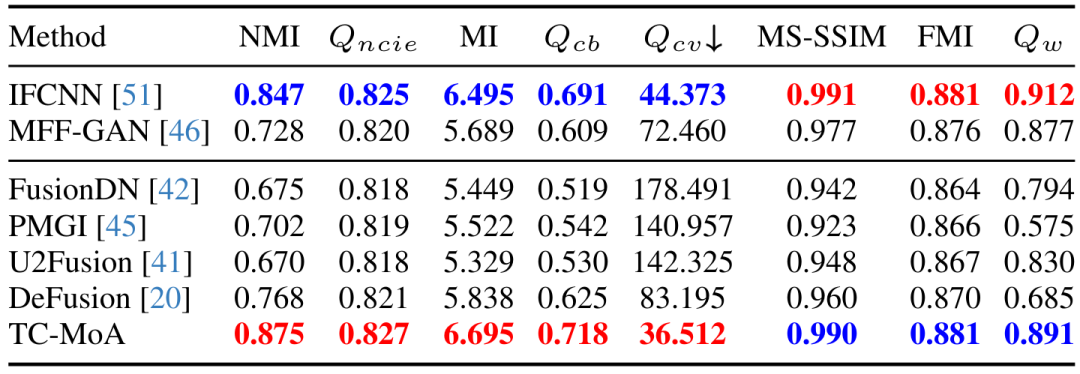 表 3 MFF タスク LLVIP データセット LLVIP データセットの定量的比較実験
表 3 MFF タスク LLVIP データセット LLVIP データセットの定量的比較実験 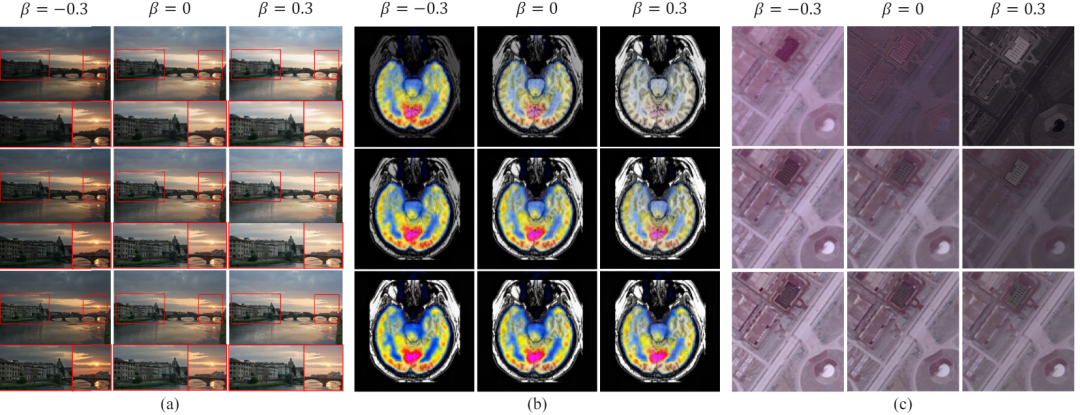 図 6未知のタスクに対する制御性と一般化
図 6未知のタスクに対する制御性と一般化