
ホームページ >テクノロジー周辺機器 >AI >Google、大型モデルの「記憶喪失」を是正するために行動を起こす!フィードバック アテンション メカニズムはコンテキストの「更新」に役立ち、大規模なモデルに無制限のメモリを使用できる時代が到来します。
Google、大型モデルの「記憶喪失」を是正するために行動を起こす!フィードバック アテンション メカニズムはコンテキストの「更新」に役立ち、大規模なモデルに無制限のメモリを使用できる時代が到来します。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-17 15:40:01541ブラウズ
編集者 | Yi Feng
プロデュース | 51CTO テクノロジー スタック (WeChat ID: blog51cto)
Google がついに行動を起こしました。私たちはもう大型モデルの「記憶喪失」に悩まされることはありません。
TransformerFAM は、大規模なモデルに無制限のメモリを搭載することを約束して誕生しました。
早速、TransformerFAM の「有効性」を見てみましょう:
 写真
写真
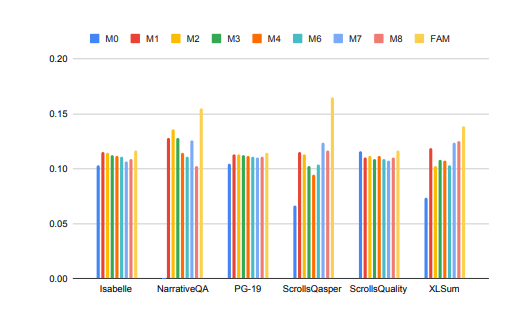
大規模なモデルの処理に時間がかかっていますコンテキストタスクのパフォーマンスが大幅に向上しました。
上の図では、Isabelle や NarrativeQA などのタスクでは、モデルが大量のコンテキスト情報を理解して処理し、特定の質問に対して正確な回答や要約を提供する必要があります。すべてのタスクにおいて、FAM で構成されたモデルは他のすべての BSWA 構成よりも優れており、ある点を超えると、BSWA メモリ セグメントの数を増やしてもメモリ機能を向上し続けることができないことがわかります。
長いテキストや長い会話の途中で、大きなモデルである FAM の「忘れられない」には何か意味があるようです。
Google 研究者は、新しい Transformer アーキテクチャである FAM (フィードバック アテンション メモリ) を導入しました。フィードバック ループを使用して、ネットワークが自身のドリフト パフォーマンスに注意を払えるようにし、Transformer の内部作業メモリの出現を促進し、無限に長いシーケンスを処理できるようにします。
簡単に言うと、この戦略は、大規模モデルの「記憶喪失」に人為的に対処するための戦略に似ています。大規模モデルと会話する前に、プロンプトを再度入力します。 FAM のアプローチはより高度です。モデルが新しいデータ ブロックを処理するとき、以前に処理された情報 (つまり、FAM) を動的に更新されるコンテキストとして使用し、それを現在の処理プロセスに再度統合します。
このようにして、「物忘れ」の問題にうまく対処できます。さらに良いことに、長期作業記憶を維持するためのフィードバック メカニズムが導入されているにもかかわらず、FAM は追加の重みを必要とせずに、事前トレーニングされたモデルとの互換性を維持するように設計されています。したがって、理論的には、大規模モデルの強力なメモリによってモデルが鈍くなったり、コンピューティング リソースをより多く消費したりすることはありません。
では、このような素晴らしい TransformerFAM はどのようにして発見されたのでしょうか?関連技術にはどのようなものがありますか?
1. 課題の観点から見ると、TransformerFAM はなぜ大規模モデルの「記憶力の向上」に役立つのでしょうか?
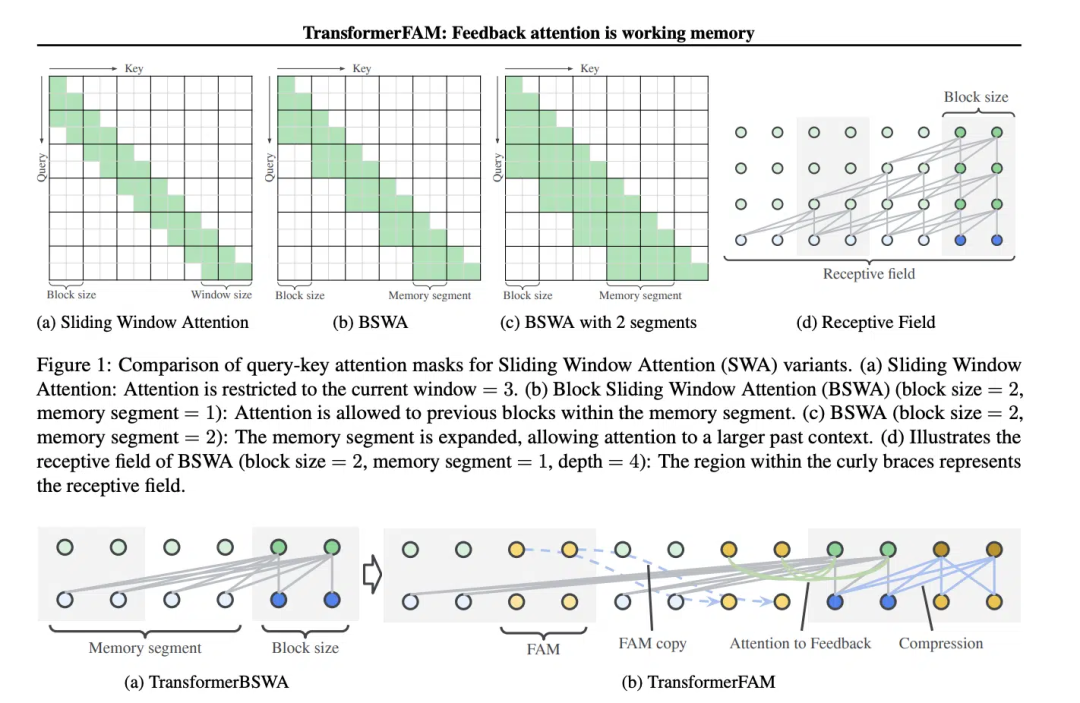
スライディング ウィンドウ アテンション (SWA) の概念は、TransformerFAM の設計にとって重要です。
従来の Transformer モデルでは、シーケンスの長さが増加するにつれて自己注意 (Self-Attendance) の複雑さが二次関数的に増加するため、長いシーケンスを処理するモデルの能力が制限されます。
「映画『メメント』(2000) では、主人公は前向性健忘症に苦しんでいます。つまり、過去 10 分間に何が起こったのか思い出せないのですが、長期記憶は損なわれておらず、重要なタトゥーを入れなければなりませんでした。現在の大規模言語モデル (LLM) の状態と同様に、身体に情報を記憶させているのです」と論文には書かれています。
 映画「メモリー」のスクリーンショット、写真はインターネットから取得したものです
映画「メモリー」のスクリーンショット、写真はインターネットから取得したものです
スライディング ウィンドウ アテンション (スライディング ウィンドウ アテンション)、改良されたアテンション メカニズムです長いシーケンスデータを処理するため。これは、コンピューター サイエンスのスライディング ウィンドウ手法からインスピレーションを得ています。自然言語処理 (NLP) タスクを扱う場合、SWA を使用すると、モデルはシーケンス全体ではなく、各タイム ステップの入力シーケンスの固定サイズのウィンドウのみに焦点を当てることができます。したがって、SWA の利点は、計算量を大幅に削減できることです。
 写真
写真
ただし、SWA には制限があります。注意範囲がウィンドウ サイズに制限されているため、モデルはウィンドウの外側を考慮できなくなります。重要な情報。
TransformerFAM は、スライディング ウィンドウ アテンションの各ブロックにコンテキスト表現を再入力するためのフィードバック アクティベーションを追加することで、統合されたアテンション、ブロック レベルの更新、情報圧縮、およびグローバル コンテキスト ストレージを実現します。
TransformerFAM では、フィードバック ループを通じて改善が達成されます。具体的には、現在のシーケンス ブロックを処理するときに、モデルは現在のウィンドウ内の要素に焦点を当てるだけでなく、以前に処理されたコンテキスト情報 (つまり、以前の「フィードバックのアクティブ化」) をアテンション メカニズムへの追加入力として再導入します。このようにして、モデルの注意ウィンドウがシーケンス上をスライドしても、以前の情報の記憶と理解を維持することができます。
したがって、これらの改善により、TransformerFAM は LLM に無限長のシーケンスを処理できる可能性を与えます。
二、有了工作記憶的大模型,繼續向AGI邁進
TransformerFAM在研究中展現出了積極的前景,這將毫無疑問地提升AI在理解和生成長文本任務中的效能,例如處理文件摘要、故事產生、問答等工作。
 圖片
圖片
同時,無論是智慧助理或是情感陪伴,一個有無限記憶力的AI聽起來都比較有吸引力。
有趣的是,TransformerFAM的設計靈感來自生物學中的記憶機制,這點與AGI追求的自然智慧模擬不謀而合。這篇論文正是一個來自神經科學的概念──基於注意力的工作記憶──整合到深度學習領域的嘗試。
TransformerFAM透過回饋循環為大模型引入了工作記憶,使得模型不僅能夠記住短期的訊息,還能夠在長期序列中維持對關鍵訊息的記憶。
透過大膽的想像,研究者在真實世界與抽象概念間假設起橋樑。隨著TransformerFAM這樣的創新成果持續湧現出來,科技的瓶頸會一次次被突破,一個更聰明、互聯的未來正向我們徐徐地展開畫卷。
想了解更多AIGC的內容,請造訪:
51CTO AI.x社群
https://www.51cto.com/aigc/
以上がGoogle、大型モデルの「記憶喪失」を是正するために行動を起こす!フィードバック アテンション メカニズムはコンテキストの「更新」に役立ち、大規模なモデルに無制限のメモリを使用できる時代が到来します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。