
ホームページ >ソフトウェアチュートリアル >オフィスソフトウェア >単一列データから重複値を削除するExcelの操作内容
単一列データから重複値を削除するExcelの操作内容

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-17 11:10:12800ブラウズ
方法 1: メニュー ボタン
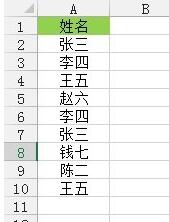
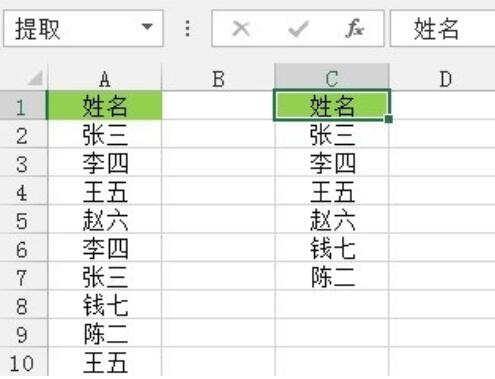
図に示すように、これがこの操作のソース データです。
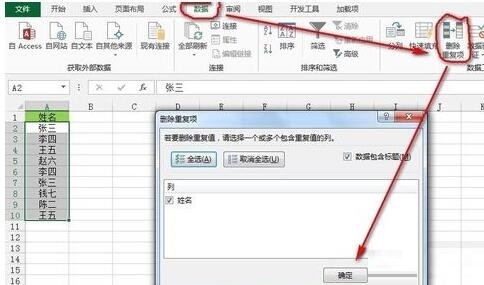
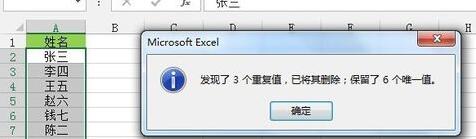
[データ]タブ--[データツール]リボン-[重複の削除]をクリックすると、[重複の削除]ダイアログボックスが表示されるので、[OK]をクリックします。データの単一列内の重複した値を削除します。
方法 2: ピボット テーブルによる方法
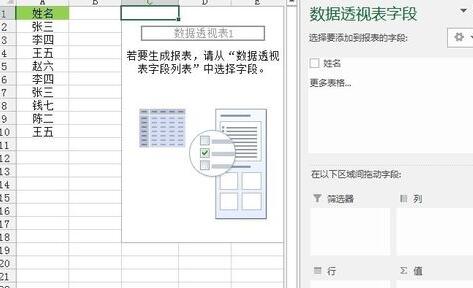
上記のデータ ソースを使用したまま、[挿入] タブをクリックし、[テーブル] リボンをクリックします。 [ピボットテーブル]を選択すると、図のようなプロンプトボックスが表示されますので、既存のワークシートのセルC1を選択し(必要に応じて新しいワークシートを選択できます)、[OK]をクリックしてピボットテーブルの作成を完了します。図:
[名前] の前のチェック ボックスをオンにすると、図に示すように、[名前] フィールドが「行」フィールドのフレームに表示されます。
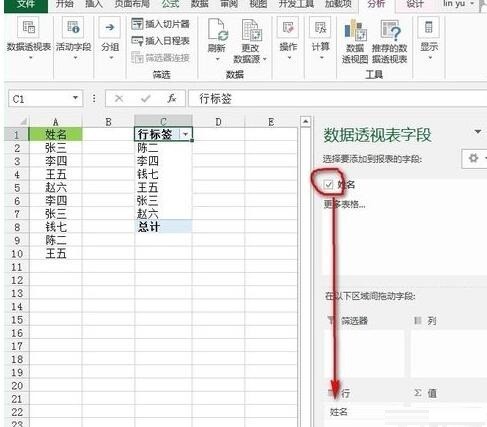
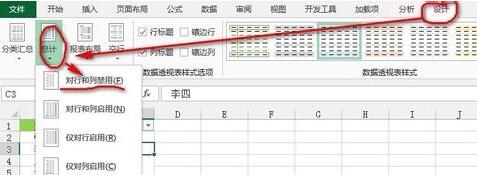
次に、ピボット テーブル内のデータを変更し、[行ラベル] が配置されているセルをクリックし、セルのテキストを [名前] に変更し、ピボット テーブル内の任意のセルをクリックします。をクリックし、[ピボットテーブルツール]--[デザイン]タブ--[レイアウト]リボン--[合計]の[行と列を無効にする]ボタンをクリックすると、図のように完了します。
 #方法 3: 数式の方法
#方法 3: 数式の方法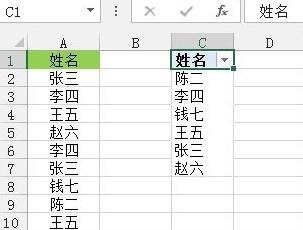
図に示すように、セル C1 に次の数式を入力し、Ctrl Shift Enter キーを 3 つ同時に押して終了し、ドラッグして終了します。数式を入力するセル 右下隅のフィルハンドルにより、重複しないデータのフィルタリングが完了します。
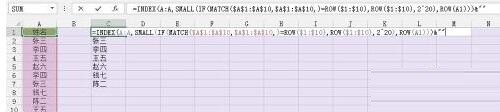 次に、式を順を追って説明します。まず、MATCH($A$1:$A$10,$A$1:$A$10,)=ROW($1)です。 : $10) は、参照領域 $A$1:$A$10 のセル A1 ~ A10 の位置が現在のセルの行番号の位置と等しいかどうかを調べることを意味します。同じであれば、データはその中で一意であることを意味します。この領域を通過し、IF(MATCH ()) を介して結合関数はこのフィールドの行番号を返し、それ以外の場合は 2^20=1048576 を返し、次に SMALL 関数を使用して取得した行番号を昇順に並べ替え、最後に次を使用します。 INDEX 関数は、行番号の位置の値を見つけるための &[] 主にフォールト トレランスのため、すべてのデータがフェッチされた場合に 1048576 の位置のみが残ると想定し、INDEX(A:A,1048576)=0、空のテキストを返すには &[] を追加します。
次に、式を順を追って説明します。まず、MATCH($A$1:$A$10,$A$1:$A$10,)=ROW($1)です。 : $10) は、参照領域 $A$1:$A$10 のセル A1 ~ A10 の位置が現在のセルの行番号の位置と等しいかどうかを調べることを意味します。同じであれば、データはその中で一意であることを意味します。この領域を通過し、IF(MATCH ()) を介して結合関数はこのフィールドの行番号を返し、それ以外の場合は 2^20=1048576 を返し、次に SMALL 関数を使用して取得した行番号を昇順に並べ替え、最後に次を使用します。 INDEX 関数は、行番号の位置の値を見つけるための &[] 主にフォールト トレランスのため、すべてのデータがフェッチされた場合に 1048576 の位置のみが残ると想定し、INDEX(A:A,1048576)=0、空のテキストを返すには &[] を追加します。 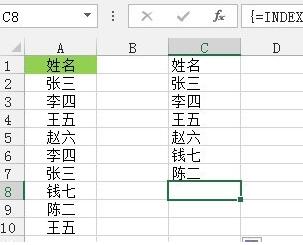
方法 4: SQL メソッド
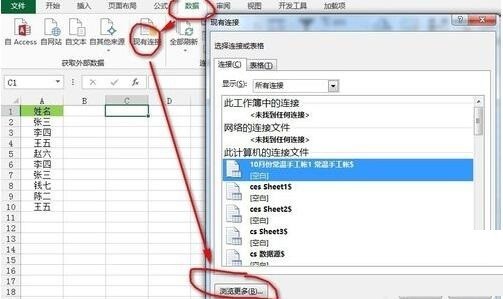
[データ] タブ - [外部データの取得] リボン - [既存の接続] をクリックし、[既存の接続] ダイアログ ボックスを開き、[参照] をクリックします。 [詳細] をクリックし、データ ソースが配置されているワークブックへのパスを見つけて [開く] をクリックすると、[テーブルの選択] ダイアログ ボックスが表示されるので、デフォルトの状態のままで [OK] ボタンをクリックします。例: 図に示すように:
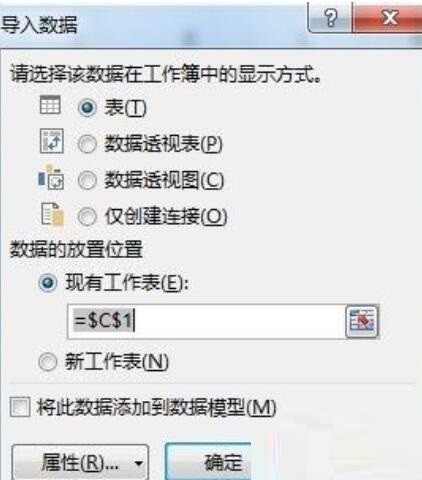
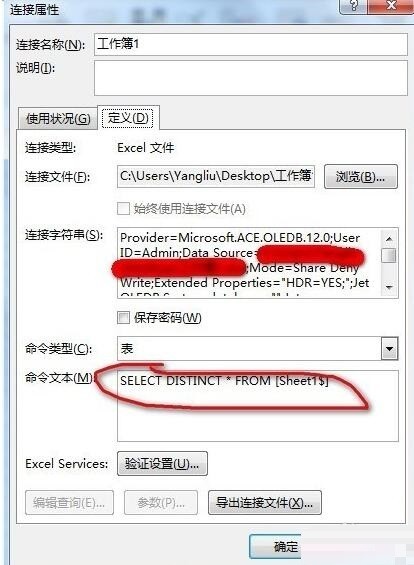
 次に、[テーブル] ラジオ ボタンを選択します。ここでは、既存のワークシートのセル C1 を選択します (新しいワークシートを選択することもできます)。必要)、[プロパティ] ボタンをクリックして [接続プロパティ] ダイアログ ボックスを開き、[定義] タブを見つけてコマンド テキストのテキストをクリアし、次のステートメントを入力します: SELECT DISTINCT * FROM [Sheet1$] (ここではSheet1 はソース データです。名前を入力します。ワークシートの名前を入力します。セル領域に他のフィールドがある場合、またはデータが行の先頭にない場合は、データも入力する必要があります。図に示すように、ソース領域 ([Sheet1$].A4 :A12)):
次に、[テーブル] ラジオ ボタンを選択します。ここでは、既存のワークシートのセル C1 を選択します (新しいワークシートを選択することもできます)。必要)、[プロパティ] ボタンをクリックして [接続プロパティ] ダイアログ ボックスを開き、[定義] タブを見つけてコマンド テキストのテキストをクリアし、次のステートメントを入力します: SELECT DISTINCT * FROM [Sheet1$] (ここではSheet1 はソース データです。名前を入力します。ワークシートの名前を入力します。セル領域に他のフィールドがある場合、またはデータが行の先頭にない場合は、データも入力する必要があります。図に示すように、ソース領域 ([Sheet1$].A4 :A12)): 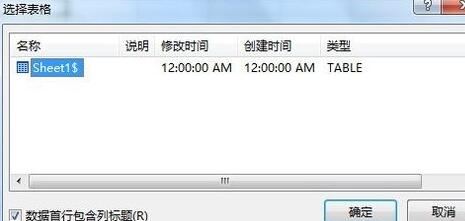
 #方法 5: 高度なフィルタリング方法
#方法 5: 高度なフィルタリング方法
[データ]タブ→[並べ替えとフィルター]リボン→[詳細]ボタンをクリックすると、図に示すように[詳細フィルター]ダイアログボックスが表示されます。

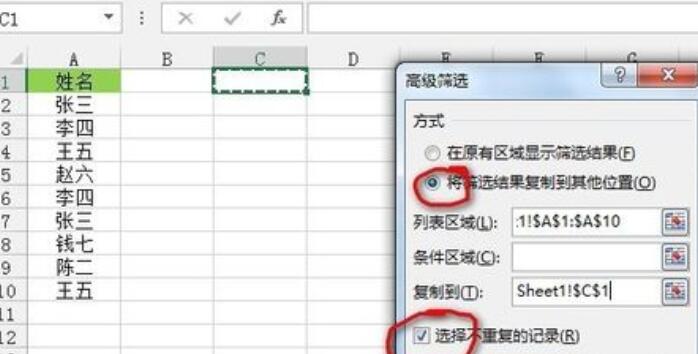
[フィルター結果を他の場所にコピー] を選択し、[リスト エリア] と [コピー先] の場所を選択して、[重複しないレコードを選択する] チェックボックスをオンにします。図の場合は、[OK]をクリックして重複値のフィルタリングを完了します。
以上が単一列データから重複値を削除するExcelの操作内容の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。