
ホームページ >テクノロジー周辺機器 >AI >ReFT (Representation Fine-tuning): PeFT よりも優れた新しい大規模言語モデル微調整テクノロジ
ReFT (Representation Fine-tuning): PeFT よりも優れた新しい大規模言語モデル微調整テクノロジ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-15 15:30:021419ブラウズ
ReFT (Representation Finetuning) は、大規模な言語モデルを微調整する方法を再定義する画期的な手法です。
スタンフォード大学の研究者によって最近 (4 月) arxiv で公開された論文によると、ReFT は従来の重みベースの微調整方法とは大きく異なり、より効率的で効率的な方法を提供します。これらの大規模なモデルを新しいタスクやドメインに適応させる方法。

この論文を紹介する前に、PeFT について見てみましょう。
パラメータの効率的な微調整 PeFT
パラメータの効率的な微調整 (PEFT) は、パラメータを微調整するための効率的な微調整方法です。少数のモデルパラメータまたは追加のモデルパラメータ。従来の予測ネットワーク微調整方法と比較して、微調整に PEFT を使用すると、完全な微調整と同等のパフォーマンスを確保しながら、コンピューティングとストレージのコストを大幅に削減できます。この技術の応用範囲は広く、フルトリミングと同等の性能を実現できます。
PeFT の考えに基づいて、私たちがよく知っている LoRA が作成されており、有名な LoRA 以外にもさまざまなバリエーションが存在します。一般的に使用される PeFT メソッドは次のとおりです。
プレフィックス チューニング: 仮想トークンを使用して継続的な暗黙的なプロンプトを構築するこれは、2021 年にスタンフォード大学によってリリースされたメソッドです。
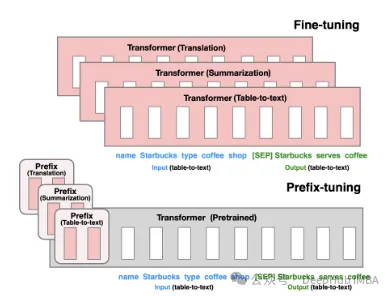
P-Tuning V1/V2 は、2021 年に清華大学によって提案されたテクノロジーであり、自然言語の離散モデルをトレーニング可能な暗黙的プロンプトに変換することを目的としています (連続パラメータ最適化問題)。 V2 バージョンでは、入力前に各レイヤーに微調整可能なパラメーターを追加することにより、V1 バージョンのパフォーマンスがさらに強化されています。この方法により、モデルの適用範囲と柔軟性が効果的に拡張されます。
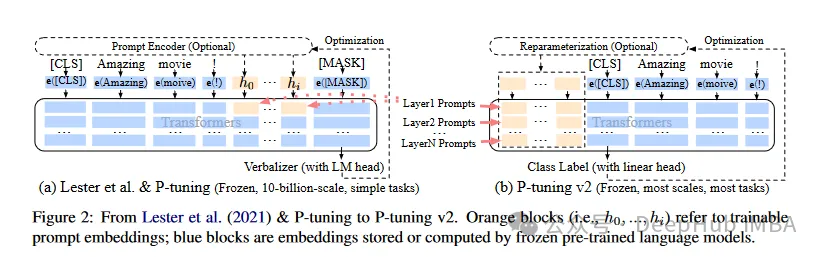
次に、私たちがよく知っており、最も古くから使用されている LoRA については、ここでは詳しく紹介しません。狭義には LoRA が現時点で最良であると理解できます。 PeFT 手法は、以下で紹介する ReFT とより適切に比較できます。
#Representation FinetuningReFT
ReFT (Representation Finetuning) は、推論プロセスに焦点を当てたグループです。隠れた表現言語モデルの重みを直接変更する代わりに介入する方法を学習します。
モデルのパラメーター セット全体を更新する従来の微調整手法とは異なり、ReFT はモデル表現の小さな部分を戦略的に操作することで動作し、その動作をガイドして下流のタスクをより効率的に解決します。
ReFT の背後にある中心的なアイデアは、言語モデルの解釈可能性に関する最近の研究に触発されています。豊富な意味情報は、これらのモデルによって学習された表現にエンコードされます。 ReFT は、これらの表現に介入することで、このエンコードされた知識を解放して活用し、より効率的かつ効果的なモデル適応を可能にすることを目指しています。
ReFT の主な利点は、パラメーターの効率性です。従来の微調整方法では、モデル パラメーターの大部分を更新する必要があり、特にモデルの場合、計算コストとリソースが大量に消費される可能性があります。数十億のパラメータを持つ大規模な言語モデルを使用します。 ReFT メソッドは通常、トレーニングに必要なパラメータが桁違いに少なく、その結果、トレーニング時間が短縮され、メモリ要件が少なくなります。
ReFT と PeFT の違い
ReFT は、いくつかの重要な点で従来の PEFT 手法と異なります。 ##1. 介入の目標
##LoRA、DoRA、プレフィックスチューニングなどの PEFT 手法は、モデルの重みを変更するか、追加の重み行列を導入することに重点を置いています。 ReFT メソッドはモデルの重みを直接変更しません。フォワード パス中にモデルによって計算された隠れた表現に干渉します。2. 適応メカニズム
LoRA や DoRA などの PEFT メソッドは、重みの更新またはモデル重み行列の低ランク近似を学習します。これらの重みの更新は、推論中に基本モデルの重みに組み込まれるため、追加の計算オーバーヘッドは発生しません。 ReFT メソッドは、推論中に特定の層と場所でモデルの表現を操作する介入方法を学習します。この介入プロセスでは、ある程度の計算オーバーヘッドが発生しますが、より効率的な適応が可能になります。
3. 動機
#PEFT 法の主な動機は、パラメータを効果的に適応させ、計算コストを削減する必要があることです。大規模な言語モデルとメモリ要件を調整します。一方、ReFT 手法は、言語モデルの解釈可能性に関する最近の研究に触発されており、これらのモデルによって学習された表現には豊富な意味情報がエンコードされていることが示されています。 ReFT の目標は、このエンコードされた知識を活用し、モデルをより効率的に適合させることです。
4. パラメータ効率
PEFT メソッドと ReFT メソッドはどちらもパラメータ効率を重視して設計されていますが、実際には ReFT メソッドの方がパラメータ効率が高いことが証明されています。たとえば、LoReFT (低ランク線形部分空間 ReFT) メソッドは、通常、最先端の PEFT メソッド (LoRA) よりもトレーニングに必要なパラメーターが 10 ~ 50 倍少なく、さまざまな NLP ベンチマークで競合以上のパフォーマンスを達成します。
5. 解釈可能性
PEFT 手法は主に効率的な適応に焦点を当てていますが、ReFT 手法には追加の利点があります。 ReFT 手法は、特定の意味情報をエンコードすることが知られている表現に介入することで、言語モデルが言語をどのように処理して理解するかについての洞察を提供でき、より透明性が高く信頼できる人工知能システムにつながる可能性があります。
ReFT アーキテクチャ
ReFT モデル アーキテクチャは、介入の一般的な概念を定義します。これは基本的に、モデルの表現された変更の前方パス中に非表示にすることを意味します。まず、トークン シーケンスの文脈化された表現を生成するトランスフォーマー ベースの言語モデルを検討します。
n 個の入力トークン x = (x₁,…,xn) のシーケンスが与えられると、モデルはまずそれを h₁,…,hn に関して表現のリストに埋め込みます。次に、m 層は j 番目の隠れ表現を継続的に計算します。各隠れ表現はベクトル h∈λ です。ここで、d は表現の次元です。
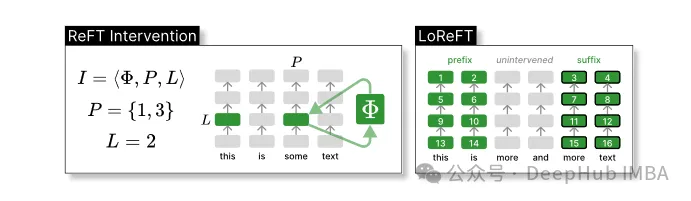
ReFT は、モデルの前方パス中に隠れた表現を変更する介入の概念を定義します。
介入 I は、トランスフォーマーベースの LM 計算によって表される単一の推論時間の介入アクションをカプセル化するタプル ⟨Φ, P, L です。この関数には 3 つのパラメーターが含まれています。
介入関数 Φ: 学習パラメータ Φ (Φ) で表されます。
介入が適用される入力位置 P≤{1,…,n} のセット。
層 L∈{1,…,m} に介入します。
その後、介入アクションは次のとおりです。
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}
介入は順伝播計算の直後に実行されます。が完了すると、後続のレイヤーで計算される表現に影響します。
計算の効率を向上させるために、介入重みを低ランクに分解することもできます。これは、低ランクの線形部分空間 ReFT (LoReFT) を取得することです。
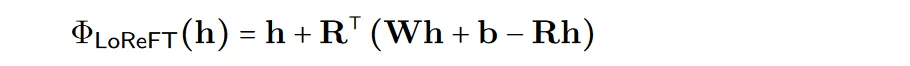
学習された投影ソース Rs = Wh b を上の式で使用します。 LoReFT は、R 列の R 次元部分空間の表現を編集して、線形投影 Wh b から取得した値を取得します。
ReFT 論文では、生成タスクについて、言語モデリングのトレーニング目標を使用し、すべての出力位置にわたるクロスエントロピー損失を最小限に抑えることに焦点を当てています。
pyreft ライブラリのコード例
スタンフォード大学の研究者は、pyreft ライブラリと同時にこの論文を発表しました。pyreft ライブラリは、上に構築されたライブラリです。 pyvene 任意の PyTorch モデルでアクティベーション介入を実行およびトレーニングするためのライブラリ。
pyreft は、HuggingFace で利用可能な事前トレーニング済み言語モデルと互換性があり、ReFT メソッドを使用して微調整できます。以下は、lama-27b モデルのレイヤー 19 の出力に単一の介入を適用する方法のコード例です。
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()
コードの残りの部分違いは、HuggingFace トレーニング モデルとは何の関係もありません。完全なデモを行ってみましょう:
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
トレーニングが完了したら、モデル情報を確認できます。
ああ、
LoReFT のパフォーマンス テスト
最後に、さまざまな NLP ベンチマークにおけるその優れたパフォーマンスを見てみましょう。以下は、スタンフォード大学の研究者によって示されたデータです。
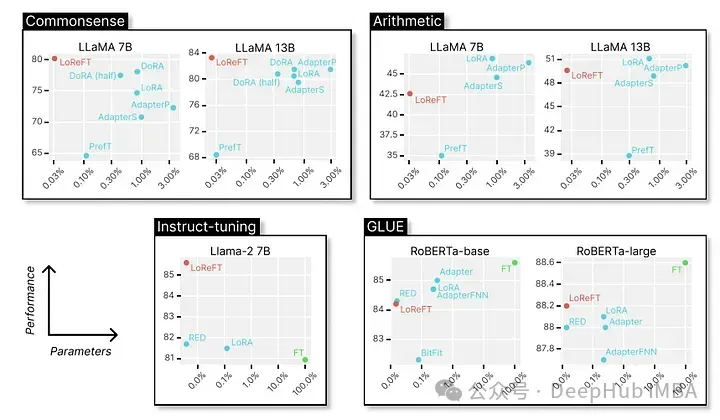
LoReFT は、BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e を含む 8 つの困難なデータセットで最先端のパフォーマンスを達成します。 、ARC-c、OBQA。 LoReFT は、既存の PEFT 手法よりも使用するパラメータが大幅に少ない (10 ~ 50 分の 1) にもかかわらず、他のすべての手法を大幅に上回り、大規模な言語モデルにエンコードされた常識知識を取得して活用する際の有効性を示しています。
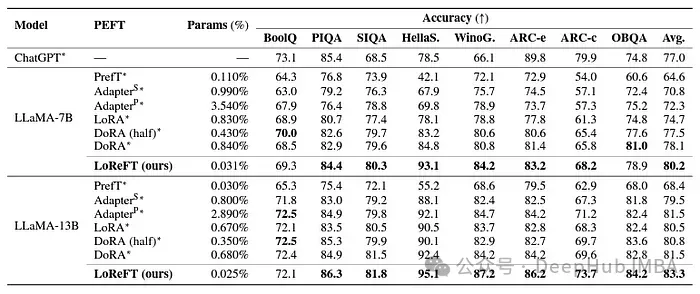
LoReFT は、数学的推論タスクでは既存の PEFT メソッドより優れたパフォーマンスを発揮しませんが、AQuA、GSM8K、MAWPS、SVAMP などのデータセットではより優れたパフォーマンスを発揮します。競争力のあるパフォーマンスを実証しました。研究者らは、LoReFT のパフォーマンスはモデルのサイズとともに向上することに注目し、言語モデルが成長し続けるにつれてその機能が拡張されることを示唆しています。
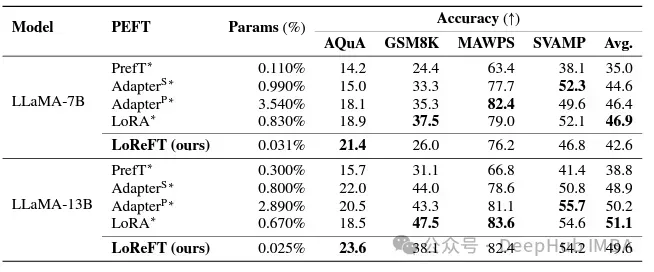
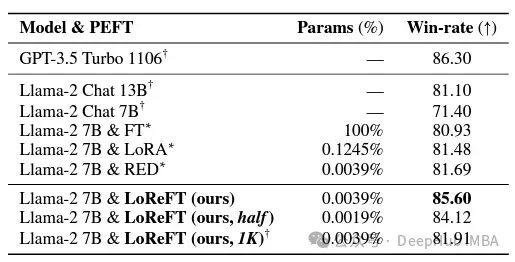
次の指導の分野では、LoReFT は Alpaca-Eval v1.0 ベンチマークでのすべての微調整手法を上回る顕著な結果を達成しました。完全な微調整を含みます(説明に注意してください)。 llama-27b モデルでトレーニングした場合、LoReFT は GPT-3.5 Turbo モデルよりも 1% 優れていますが、使用するパラメーターは他の PEFT 手法よりもはるかに少なくなります。
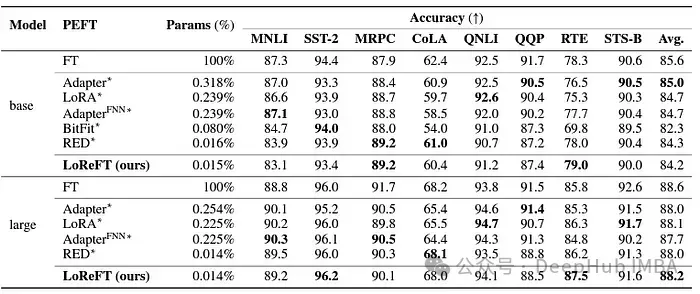
LoReFT は、GLUE で RoBERTa ベースおよび RoBERTa ラージ モデルに適用した場合、自然言語理解タスクでもその機能を実証しました 既存のモデルと同等のパフォーマンスPEFT 手法はベンチマーク テストで達成されます。
パラメータの数において、以前の最も効果的な PEFT 手法と一致した場合、LoReFT は感情分析や自然言語推論などのさまざまなタスクで同様のスコアを達成しました。
概要
ReFT、特に LoReFT の成功は、人類の将来に大きな影響を与えます。自然言語処理と大規模言語 モデルの実用化は非常に重要です。 ReFT のパラメータ効率により、計算リソースとトレーニング時間を最小限に抑えながら、大規模な言語モデルを特定のタスクまたはドメインに適応させるための効果的なソリューションになります。
そして、ReFT は、大規模な言語モデルの解釈可能性を高めるための独自の視点も提供します。常識的推論、算術推論、指示に従うなどのタスクで成功することは、このアプローチの有効性を示しています。現在、ReFT は新たな可能性を切り開き、従来のチューニング手法の限界を克服すると期待されています。
LoReFT のパフォーマンス テスト
最後に、さまざまな NLP ベンチマークにおけるその優れたパフォーマンスを見てみましょう。以下は、スタンフォード大学の研究者によって示されたデータです。
LoReFT は、BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e を含む 8 つの困難なデータセットで最先端のパフォーマンスを達成します。 、ARC-c、OBQA。 LoReFT は、既存の PEFT 手法よりも使用するパラメータが大幅に少ない (10 ~ 50 分の 1) にもかかわらず、他のすべての手法を大幅に上回り、大規模な言語モデルにエンコードされた常識知識を取得して活用する際の有効性を示しています。
LoReFT は、数学的推論タスクでは既存の PEFT メソッドより優れたパフォーマンスを発揮しませんが、AQuA、GSM8K、MAWPS、SVAMP などのデータセットではより優れたパフォーマンスを発揮します。競争力のあるパフォーマンスを実証しました。研究者らは、LoReFT のパフォーマンスはモデルのサイズとともに向上することに注目し、言語モデルが成長し続けるにつれてその機能が拡張されることを示唆しています。
次の指導の分野では、LoReFT は Alpaca-Eval v1.0 ベンチマークでのすべての微調整手法を上回る顕著な結果を達成しました。完全な微調整を含みます(説明に注意してください)。 llama-27b モデルでトレーニングした場合、LoReFT は GPT-3.5 Turbo モデルよりも 1% 優れていますが、使用するパラメーターは他の PEFT 手法よりもはるかに少なくなります。
LoReFT は、GLUE で RoBERTa ベースおよび RoBERTa ラージ モデルに適用した場合、自然言語理解タスクでもその機能を実証しました 既存のモデルと同等のパフォーマンスPEFT 手法はベンチマーク テストで達成されます。
パラメータの数において、以前の最も効果的な PEFT 手法と一致した場合、LoReFT は感情分析や自然言語推論などのさまざまなタスクで同様のスコアを達成しました。
概要
ReFT、特に LoReFT の成功は、人類の将来に大きな影響を与えます。自然言語処理と大規模言語 モデルの実用化は非常に重要です。 ReFT のパラメータ効率により、計算リソースとトレーニング時間を最小限に抑えながら、大規模な言語モデルを特定のタスクまたはドメインに適応させるための効果的なソリューションになります。
そして、ReFT は、大規模な言語モデルの解釈可能性を高めるための独自の視点も提供します。常識的推論、算術推論、指示に従うなどのタスクで成功することは、このアプローチの有効性を示しています。現在、ReFT は新たな可能性を切り開き、従来のチューニング手法の限界を克服すると期待されています。
以上がReFT (Representation Fine-tuning): PeFT よりも優れた新しい大規模言語モデル微調整テクノロジの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。