
ホームページ >テクノロジー周辺機器 >AI >因果推論に基づく推奨システム: レビューと展望
因果推論に基づく推奨システム: レビューと展望

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-12 09:01:07927ブラウズ
この共有のテーマは、因果推論に基づく推奨システムであり、過去の関連研究をレビューし、この方向での将来の見通しを提案します。
なぜレコメンデーション システムで因果推論テクノロジーを使用する必要があるのでしょうか?既存の研究では、因果推論を使用して 3 種類の問題を解決しています (Gao et al. の TOIS 2023 論文『推奨システムにおける因果推論: 調査と今後の方向性』を参照):
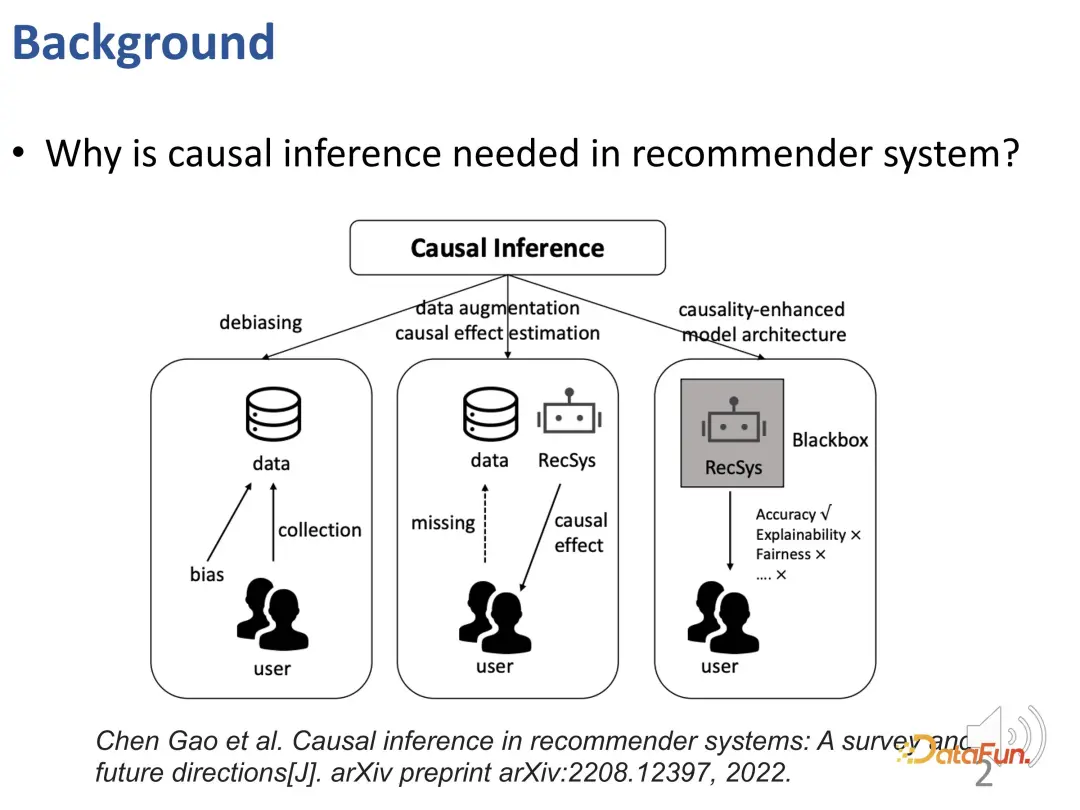
##まず、レコメンデーションシステムにはさまざまなバイアス(BIAS)が存在しており、因果推論はこれらのバイアスを除去する有効なツールです。
レコメンダー システムは、データ不足と因果関係を正確に推定できないという問題を解決するために課題に直面する可能性があります。この問題を解決するために、因果推論に基づくデータ強化または因果効果推定手法を使用して、データ不足と因果効果推定の難しさの問題を効果的に解決できます。
最後に、因果関係の知識または因果関係の事前知識を利用してレコメンデーション システムの設計をガイドすることで、レコメンデーション モデルをより適切に構築できます。この手法により、レコメンデーションモデルは従来のブラックボックスモデルを超え、精度が向上するだけでなく、解釈性や公平性も大幅に向上します。
これら 3 つのアイデアから始まり、この共有では次の 3 つの作業部分が導入されます:
- ユーザーの興味と適合性の解きほぐし学習 (Y. Zheng、Chen Gao、他) al. 因果的埋め込みによる推奨のためのユーザーの関心と適合性の解きほぐし[C]//Web Conference 2021 の議事録。2021: 2980-2991.)
- 長期的な関心と短期的な関心の解きほぐし学習 ( Y. Zheng、Chen Gao*、他、推奨のための長期的および短期的利益の解消[C]//ACM Web Conference 2022 の議事録。2022: 2256-2267.)
- 短いビデオの推奨事項 バイアスの除去(Y. Zheng、Chen Gao*、他 DVR: 継続時間バイアスの下で再生時間のゲインを最適化するマイクロビデオの推奨事項[C]//第 30 回 ACM 国際マルチメディア会議議事録。2022: 334- 345.)
1. ユーザーの興味と適合性の解きほぐし学習
まず、因果推論法による: ユーザーの興味と適合を区別し、対応する表現を学習します。これは前述の分類フレームワークの 3 番目の部分に属し、原因と結果についての事前知識がある場合にモデルをより解釈しやすくするものです。
研究の背景に戻ります。ユーザーと製品間のインタラクションの背後には、根深いさまざまな理由があることがわかります。一方では、それはユーザー自身の利益であり、他方では、ユーザーは他のユーザーの実践に従う傾向がある可能性があります (適合性)。特定のシステムでは、これが販売量や人気として現れる場合があります。例えば、既存のレコメンドシステムでは、売上の高い商品が前面に表示されるため、ユーザーの興味を超えた人気がインタラクションに影響を与え、偏りをもたらします。したがって、より正確な推奨を行うには、2 つの部分の表現の学習と解決を区別する必要があります。
なぜ解きほぐされた表現を学ぶ必要があるのでしょうか?ここで、さらに詳しい説明をしてみましょう。解きほぐされた表現は、オフラインのトレーニング データとオンラインの実験データの不整合な分布 (OOD) の問題を克服するのに役立ちます。実際のレコメンデーション システムでは、オフラインのレコメンデーション システム モデルが特定のデータ分布に基づいてトレーニングされている場合、オンラインで展開するとデータの分布が変化する可能性があることを考慮する必要があります。ユーザーの最終的な行動は、適合性と関心の共同作用によって生み出されます。これら 2 つの部分の相対的な重要性は、オンライン環境とオフライン環境では異なるため、データの分布が変化する可能性があります。分布が変化した場合、データの分布は変化しません。学習への関心が持続することを保証します。これは相互分散の問題です。下の図は、この問題を視覚的に示しています。この図では、トレーニング データ セットとテスト データ セットの間に分布の違いがあります。形状は同じですが、サイズと色が変化しています。形状予測の場合、従来のモデルはトレーニング データ セットのサイズと色に基づいて形状を推論する場合があります。たとえば、長方形は青で最大ですが、その推論はテスト データ セットには当てはまりません。
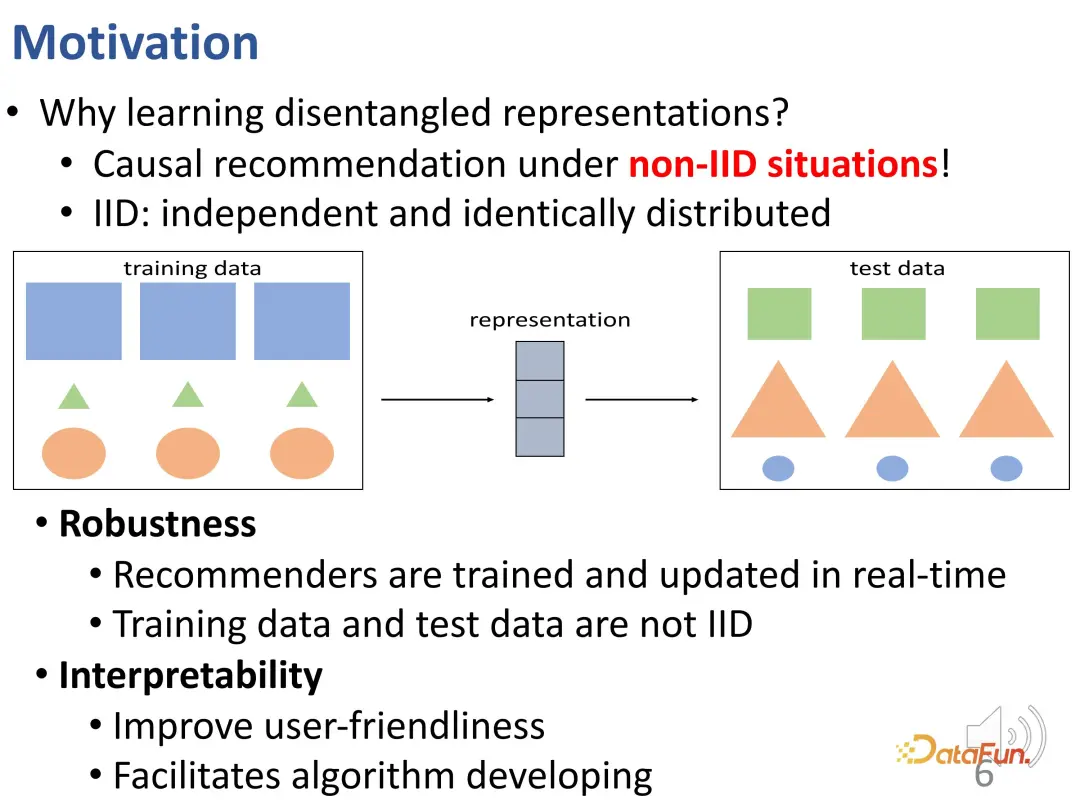
#この困難をより適切に克服したい場合は、各部分の表現が対応する要素によって決定されることを効果的に保証する必要があります。これは、もつれの解けた表現を学ぶ動機の 1 つです。潜在的な要因を解きほぐすことができるモデルは、上の図のような相互分布の状況でより良い結果を達成できます。たとえば、解きほぐしは輪郭、色、サイズなどの要素を学習し、形状を予測するために輪郭を使用することを好みます。
従来のアプローチは、IPS メソッドを使用して製品の人気のバランスをとることです。この方法では、推奨システム モデルの学習プロセス中に、過度に人気のある項目 (これらの項目は適合性の観点からより大きな重みを持ちます) にペナルティを与えます。しかし、このアプローチでは、関心と順応性を効果的に分離することなく、一緒に束ねることになります。

因果推論を通じて因果表現 (因果埋め込み) を学習することに関する初期の研究がいくつかあります。このタイプの作業の欠点は、いくつかの不偏データ セットに依存し、不偏データ セットを使用して偏りのあるデータ セットの学習プロセスを制限する必要があることです。それほど多くは必要ありませんが、もつれの解かれた表現を学習するには少量の不偏データが依然として必要です。したがって、実際のシステムへの適用可能性は比較的限られています。

- 可変的な適合性: 適合性は実際には、より一般的またはより一般的な概念であり、人気のバイアスが関係します。適合性はユーザーとアイテムの両方によって決定され、アイテムごとにユーザーの適合性が異なる場合もあり、その逆も同様です。
- #もつれを解くことの難しさ: もつれを解く表現を直接学ぶのは非常に困難です。観測データ (興味と適合性の両方によって影響を受ける行動) のみが取得できますが、ユーザーの興味についての根拠はありません。つまり、興味と適合性自体に対する明示的なラベルはありません。
- ユーザー行動の多因果性: ユーザーのインタラクションは、単一の要因から生じる場合もあれば、2 つの要因の組み合わせから生じる場合もあります。システムには、2 つの要素を効果的に組み合わせるための詳細な設計が必要です。
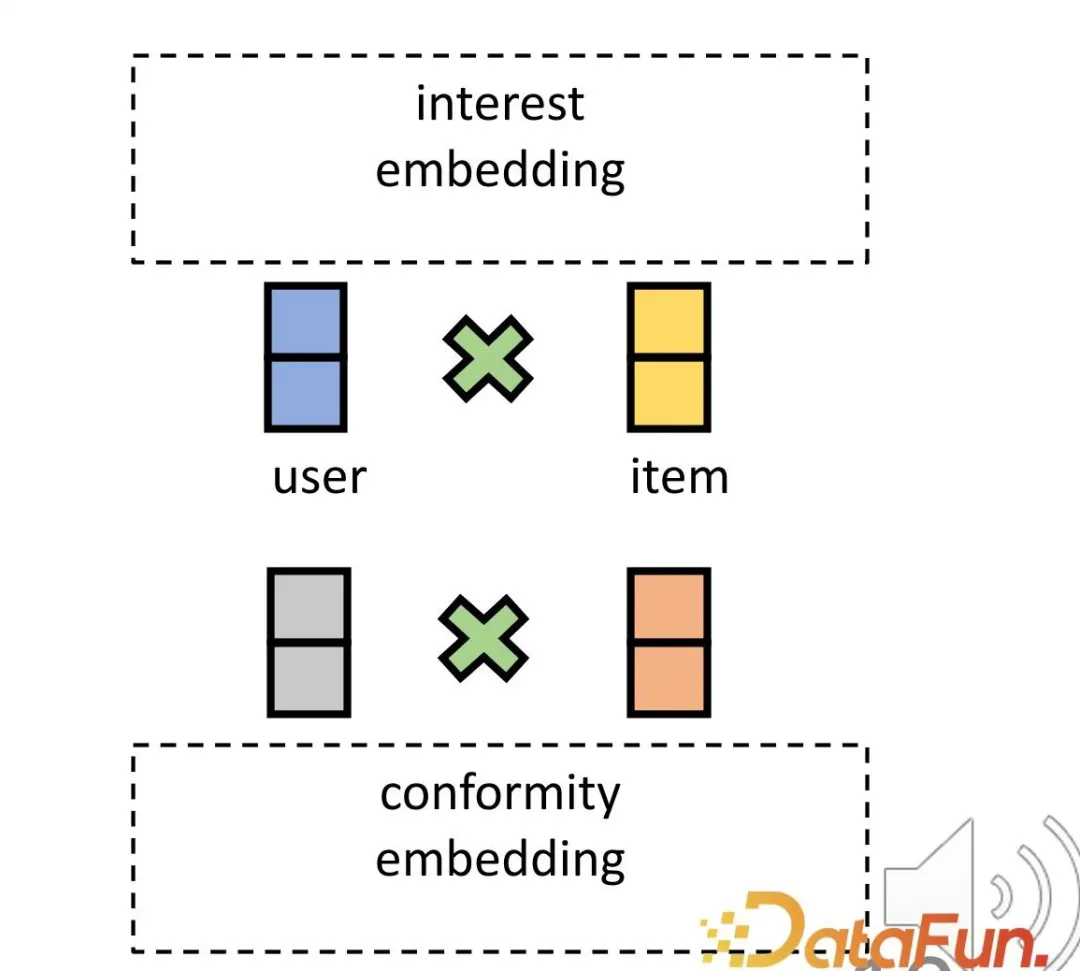
- #最初の課題を解決するために、関心と適合性の観点から、ユーザーと製品に対応する表現が設定されます。まず、ユーザーと製品間のインタラクションを高次元空間に埋め込むことで、多様な適合性を効果的に表現できます。第二に、この方法は、共通の表現に依存するのではなく、高次元空間における関心と適合性のもつれを効果的に直接解きほぐし、両者の独立性を達成することができます。
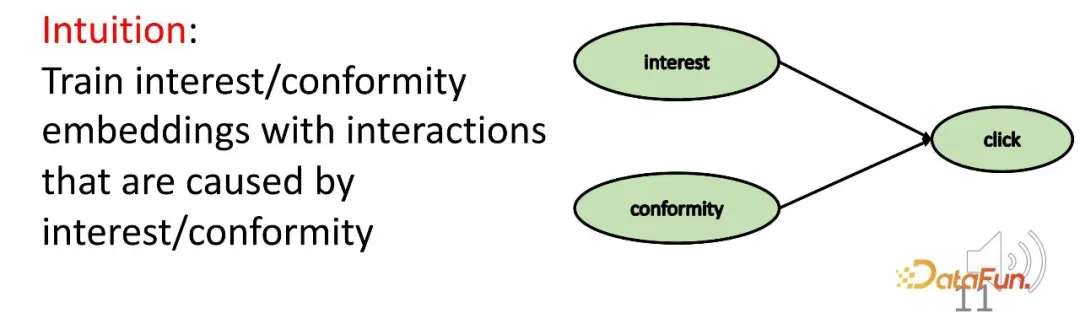
- #2 番目の課題を解決するには、因果推論における衝突関係を利用します。関心と適合性は共同して行動を引き起こし、衝突関係が存在します。この関係は、2 つの部分の対応する表現を学習するための特定の因果関係データを取得するために使用されます。
- ユーザー行動の多要素の課題を解決するには、マルチタスク プログレッシブを使用します。これら 2 つの要素を効果的に組み合わせて最終的な推奨事項を達成するための学習 (カリキュラム学習、CL) 方法。
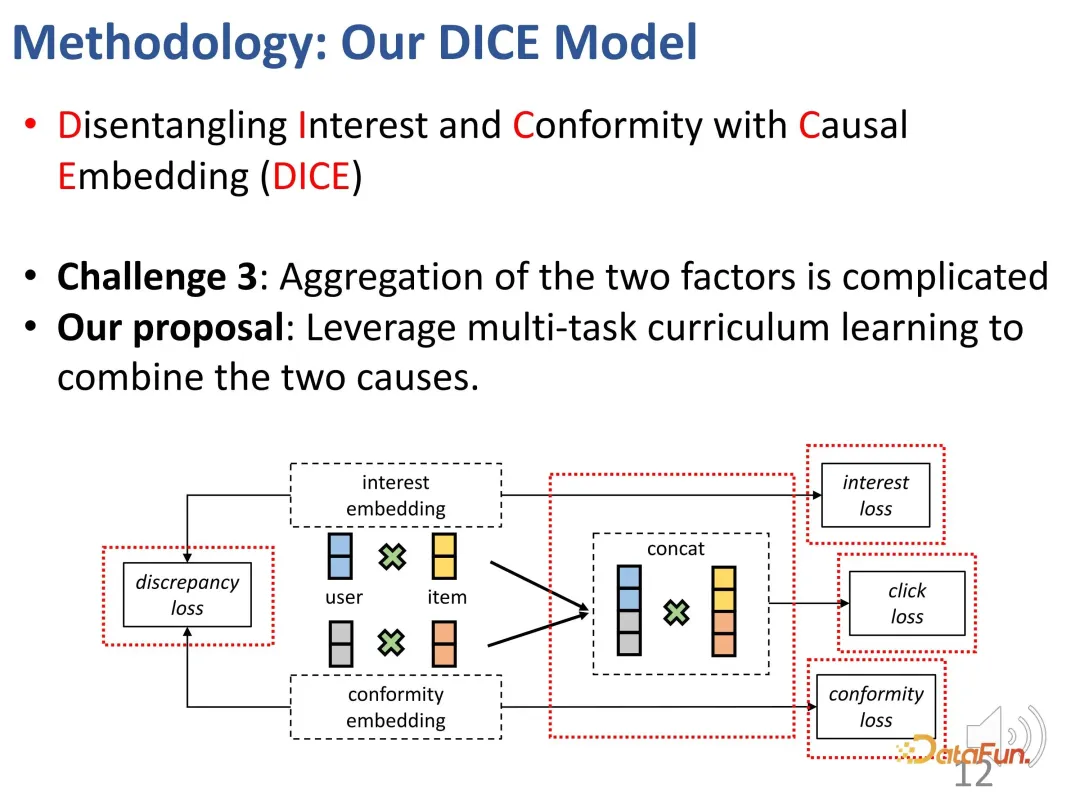 次に、3 つの部分 (因果的埋め込み、解きほぐされた表現学習、マルチタスク コース学習) を設計します。 ) の詳細 はじめにを展開します。
次に、3 つの部分 (因果的埋め込み、解きほぐされた表現学習、マルチタスク コース学習) を設計します。 ) の詳細 はじめにを展開します。
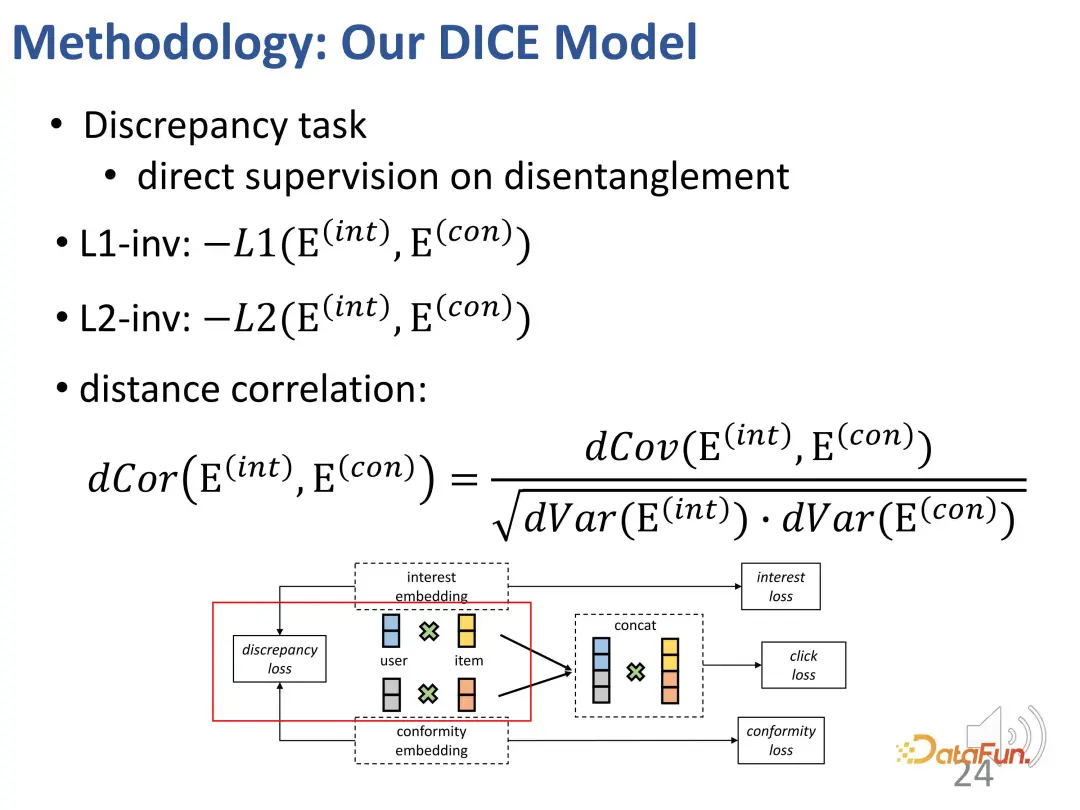
1. 因果の埋め込み
まず、興味や群集行動を含む構造的因果モデルを構築します。
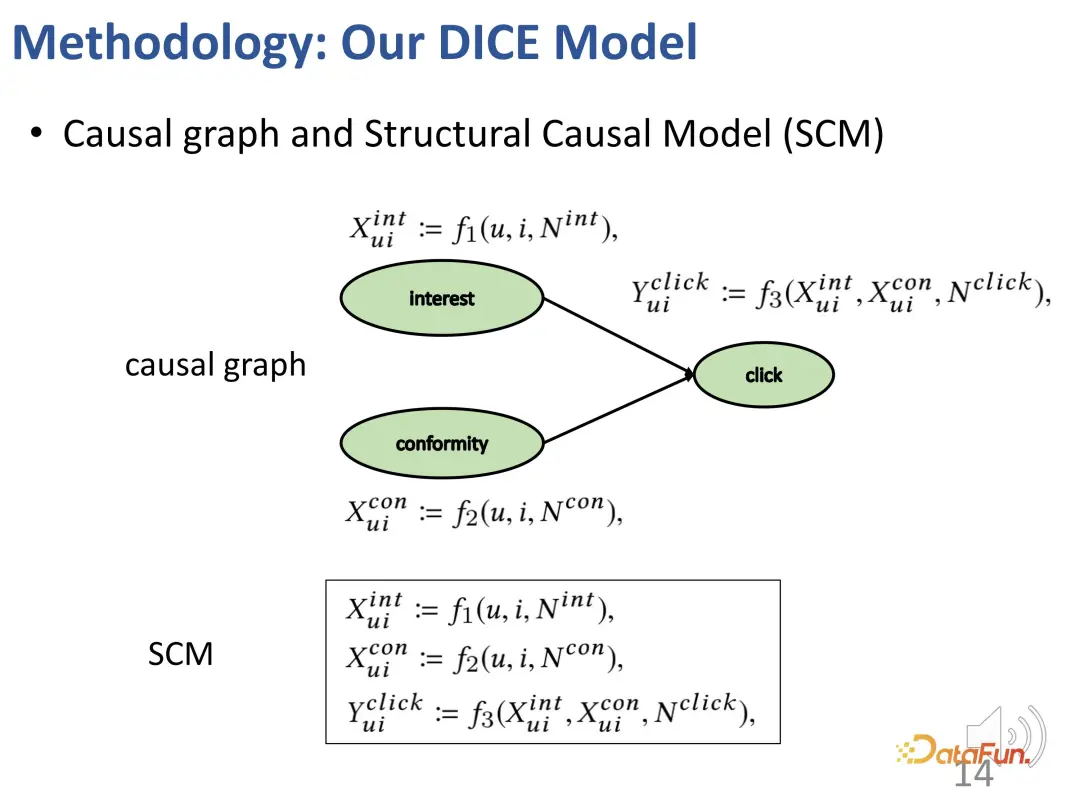 これら 2 つの要素に対応する独立した表現を割り当てます。ユーザー側とアイテム側のそれぞれの側に 2 つの表現部分があります。古典的なドット積を使用してマッチング スコアを計算します。最終的な予測タスクでは、両方の部分の内部積分スコアが考慮されます。
これら 2 つの要素に対応する独立した表現を割り当てます。ユーザー側とアイテム側のそれぞれの側に 2 つの表現部分があります。古典的なドット積を使用してマッチング スコアを計算します。最終的な予測タスクでは、両方の部分の内部積分スコアが考慮されます。
2. 解きほぐされた表現の学習
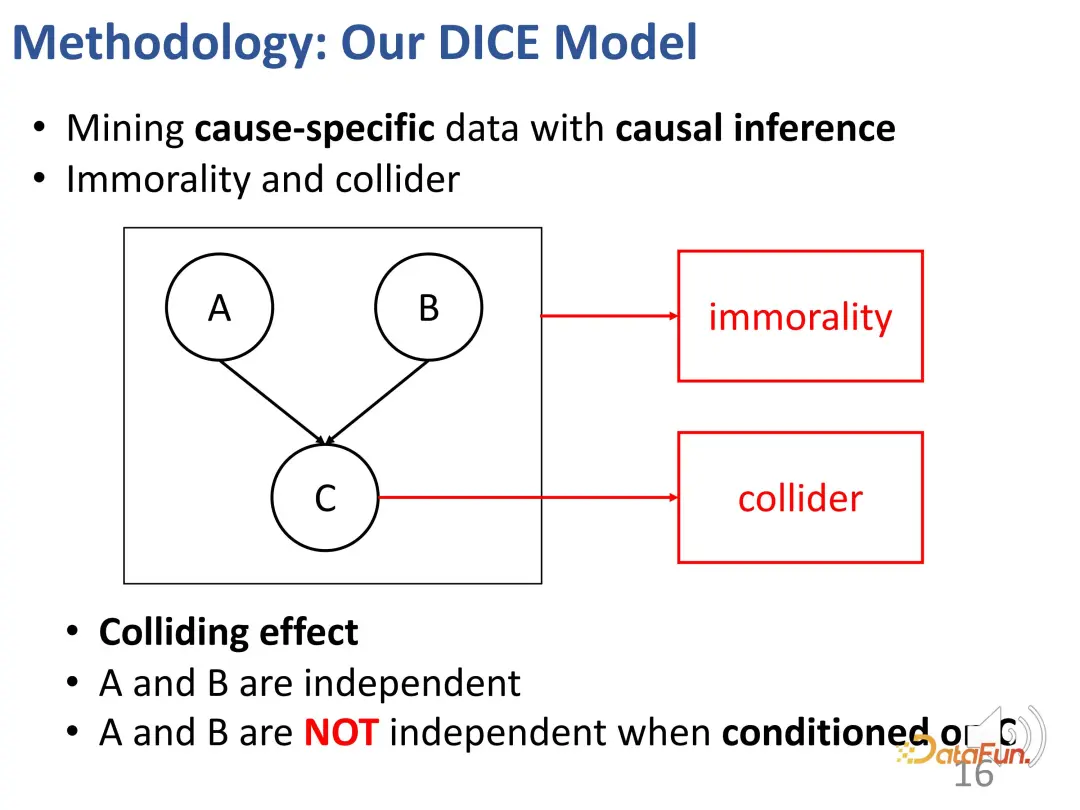
上記のような衝突構造を与えた後、条件 c を固定すると、a とb は実際には独立していません。この効果を説明する例を挙げてください。たとえば、a は生徒の才能を表し、b は生徒の勤勉さを表し、c は生徒が試験に合格できるかどうかを表します。この生徒が試験に合格し、特に優れた才能を持っていない場合、彼は非常に一生懸命勉強したに違いありません。別の生徒、彼は試験に落ちましたが、彼は非常に才能があるので、このクラスメートは十分に勉強しないかもしれません。
この考えに基づいて、この方法は、関心の一致と適合の一致を分割し、製品の人気を適合の代理として使用するように設計されています。
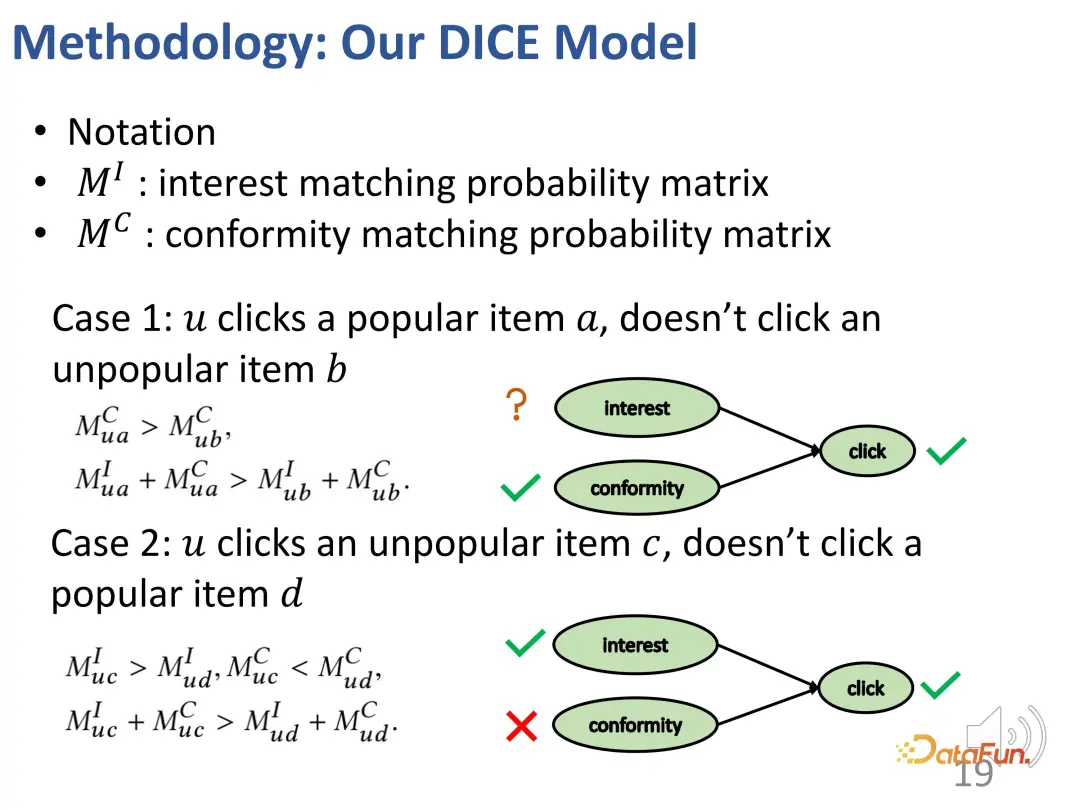
最初のケース: 先ほどの例と同様に、ユーザーがより人気のあるアイテム a をクリックし、あまり人気のない別のアイテム b をクリックしなかった場合、次のようになります。このような関心関係: ユーザーに対する a の適合性は b よりも大きく (a は b よりも人気があるため)、ユーザーに対する a の全体的な魅力 (関心の適合性) は b よりも大きい (ユーザーは a をクリックしたが b をクリックしなかったため) 。
2 番目のケース: ユーザーは人気のないアイテム c をクリックしましたが、人気のあるアイテム d をクリックしませんでした。その結果、次の関係が生じます: ユーザーに対する c の適合性は d 未満です。 (d は c よりも人気があるため)、しかし、ユーザーにとって c の全体的な魅力 (関心の適合性) は d よりも大きい (ユーザーは d ではなく c をクリックしたため)、そのためユーザーの c への関心は d よりも大きいです (理由は、前述の衝突関係)。
一般的に、上記の方法で 2 つのセットが構築されます。1 つは、ポジティブ サンプルよりも人気の低いネガティブ サンプル (ユーザーのポジティブ サンプルとユーザーのポジティブ サンプル) です。ネガティブ サンプルの関心間の対照的な関係は不明です)、2 つ目はポジティブ サンプルよりも人気のあるネガティブ サンプルです (ユーザーはネガティブ サンプルよりもポジティブ サンプルに興味があります)。これら 2 つの部分について、目標を絞った方法で 2 つの部分の表現ベクトルをトレーニングするために、対照学習の関係を構築できます。
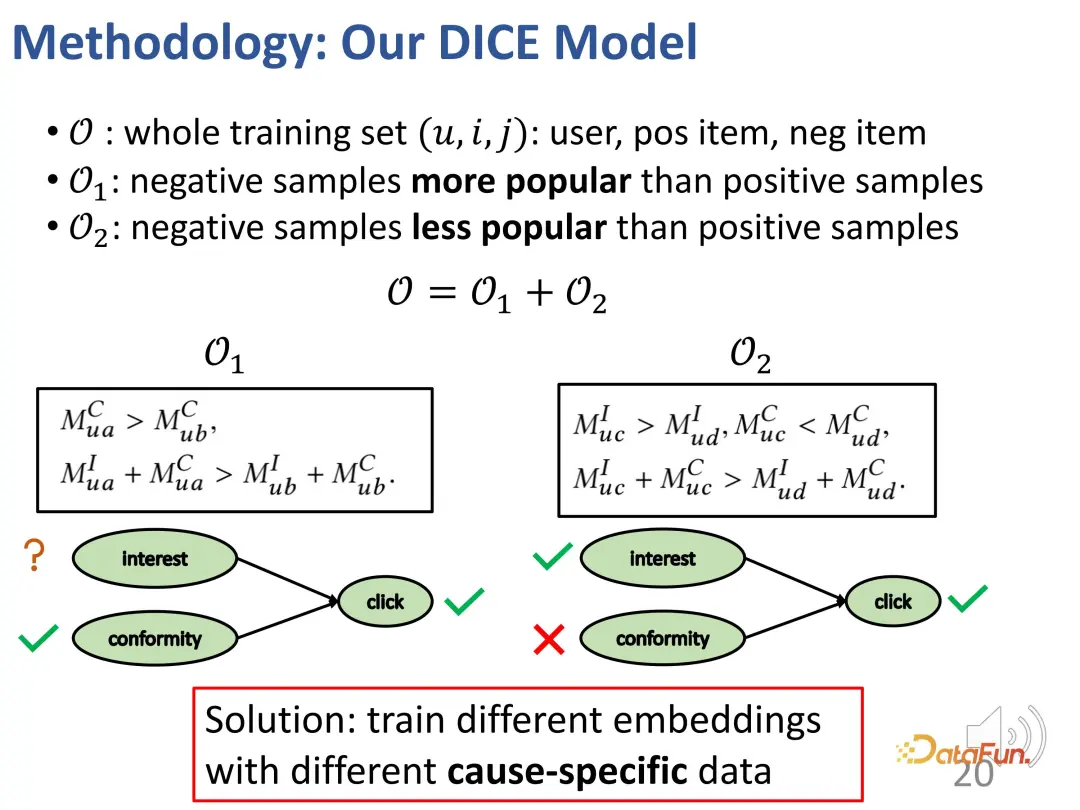
もちろん、実際のトレーニング プロセスでも、主な目標は観察されたインタラクション動作に適合させることです。ほとんどのレコメンデーション システムと同様に、BPR 損失はクリック動作を予測するために使用されます。 (u: ユーザー、i: 陽性サンプル製品、j: 陰性サンプル製品)。
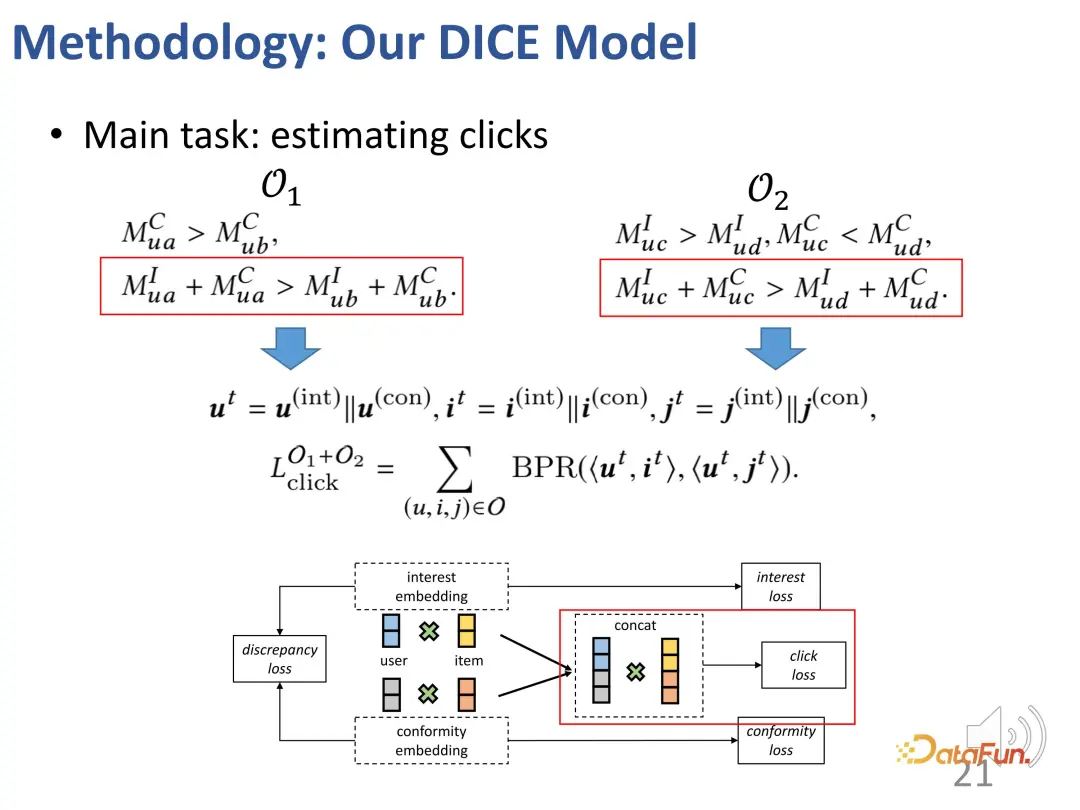
さらに、上記の考えに基づいて、対照学習方法の 2 つの部分も設計し、対照学習の損失関数を導入し、 2 つの追加部分 表現ベクトルの 2 つの部分を最適化するための表現ベクトルの制約
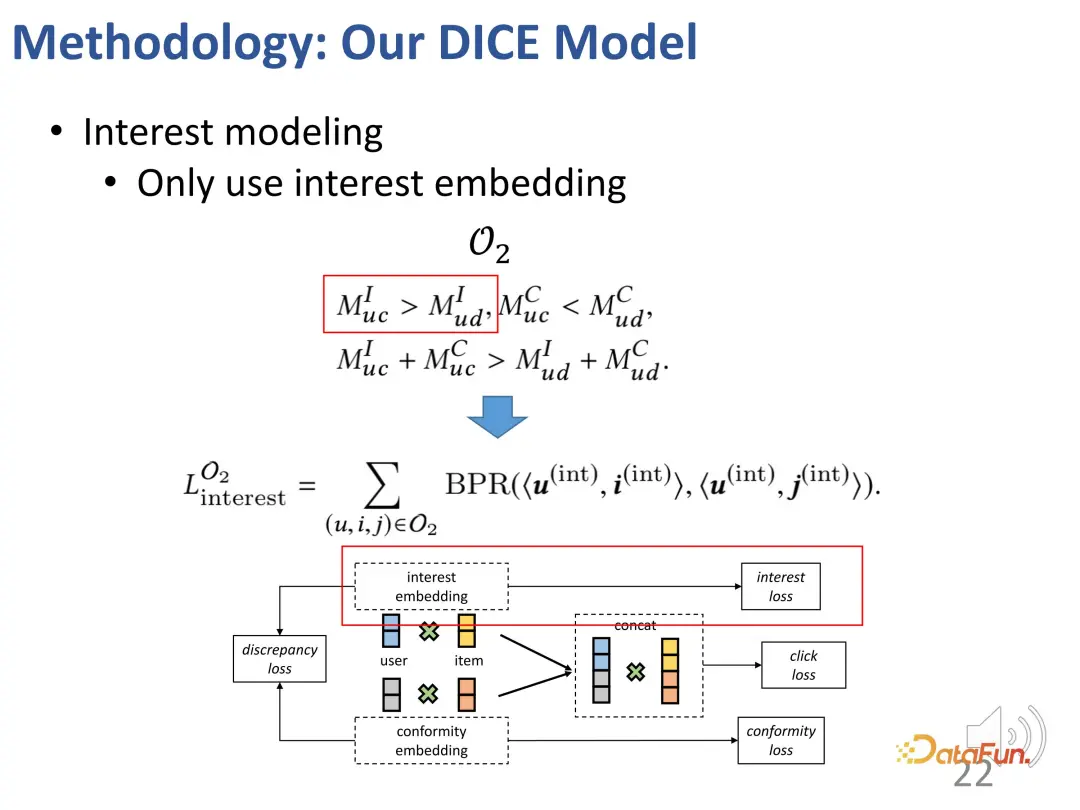
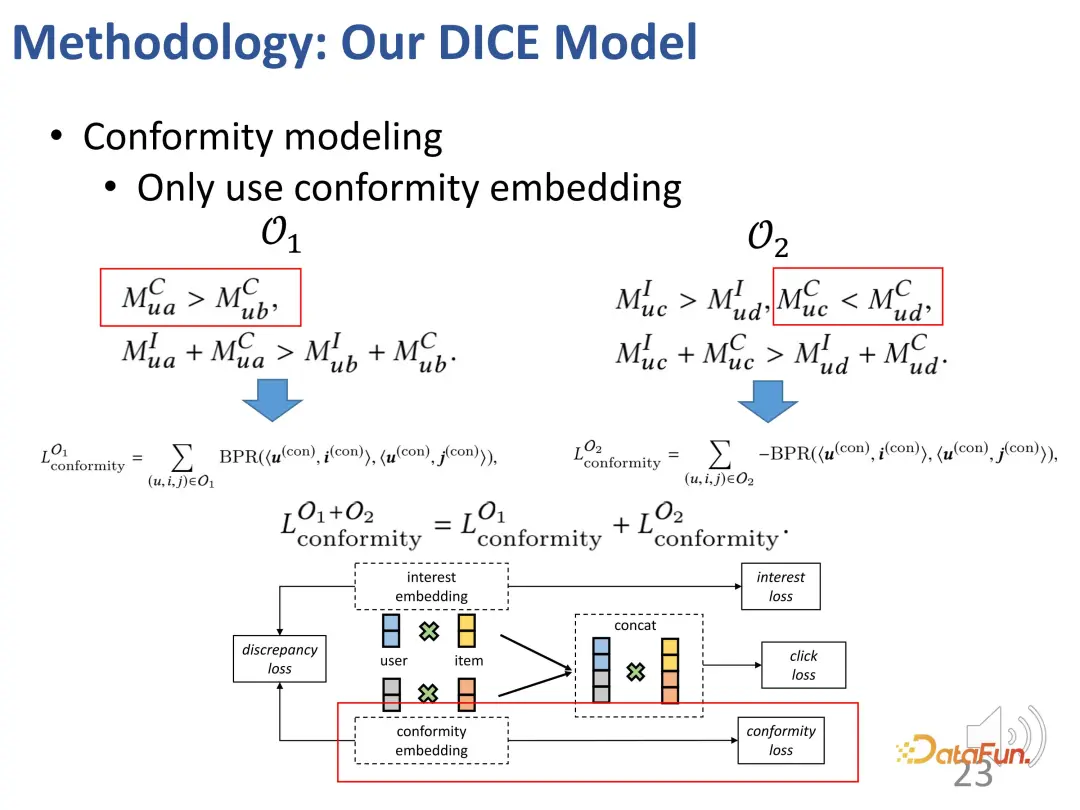
さらに、これら 2 つの部分も制約する必要があります。部分の表現ベクトルは、可能な限り互いに遠く離れています。近すぎると区別がつかなくなる可能性があるためです。したがって、2 つの部分表現ベクトル間の距離を制約するために、追加の損失関数が導入されます。
3. マルチタスク コース学習
最終的には、マルチタスク学習により複数の目標が統合されます。一緒に。このプロセスでは、学習の難易度が簡単なものから難しいものに段階的に移行するように戦略が設計されました。トレーニングの開始時は、識別の少ないサンプルを使用して、モデル パラメーターが一般的な正しい方向に最適化されるように導きます。その後、学習が困難なサンプルを徐々に見つけて、モデル パラメーターをさらに微調整します。 (ポジティブサンプルとの人気の差が大きいネガティブサンプルを単純サンプル、差が小さいサンプルを困難サンプルとみなします。)

4. メソッドの効果
は、主要なランキング指標に対するメソッドのパフォーマンスを調べるために、一般的なデータセットでテストされました。 DICE は特定の推奨モデルに依存しない汎用フレームワークであるため、さまざまなモデルをバックボーンとみなしてプラグアンドプレイ フレームワークとして使用できます。

#まずは主人公のDICE。 DICE の改善はさまざまなバックボーン上で比較的安定していることがわかり、パフォーマンスの向上をもたらすことができる一般的なフレームワークと考えることができます。
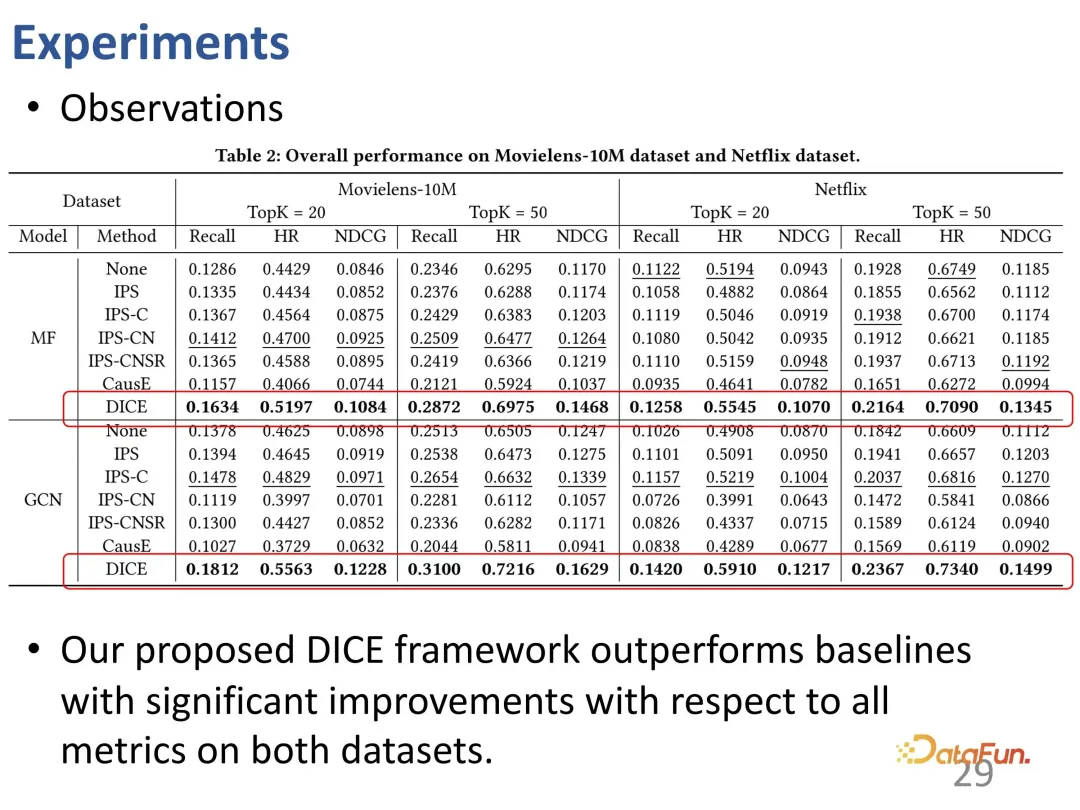
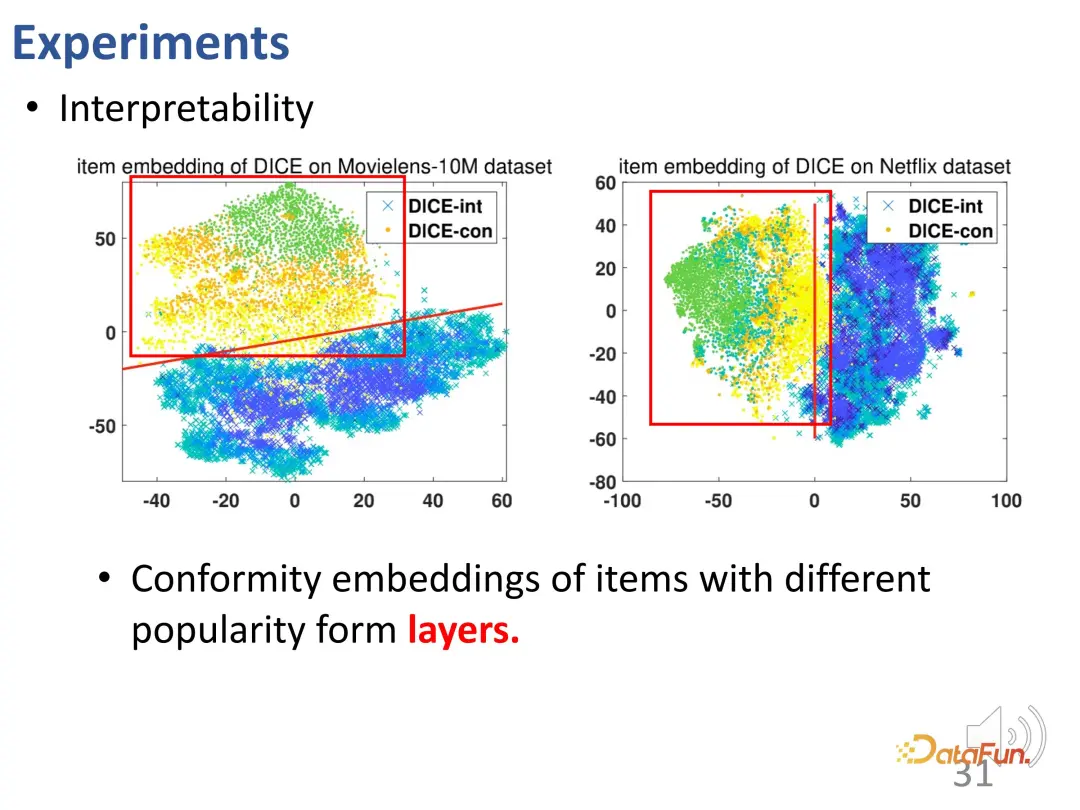
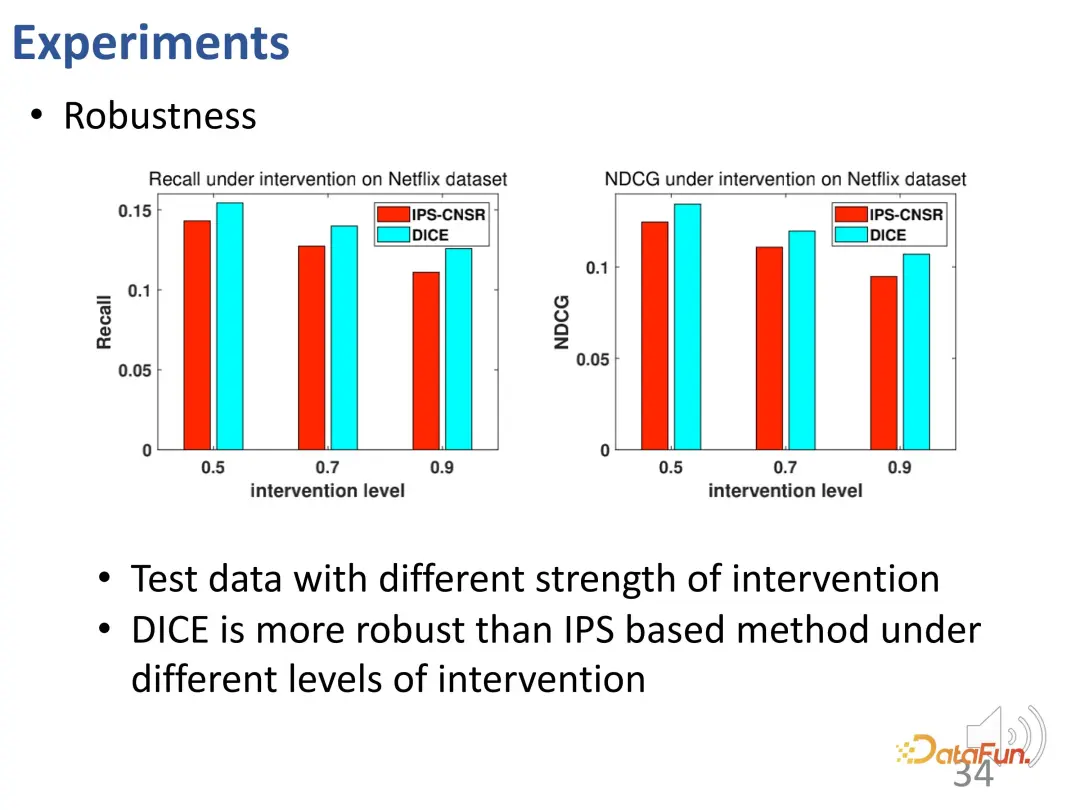
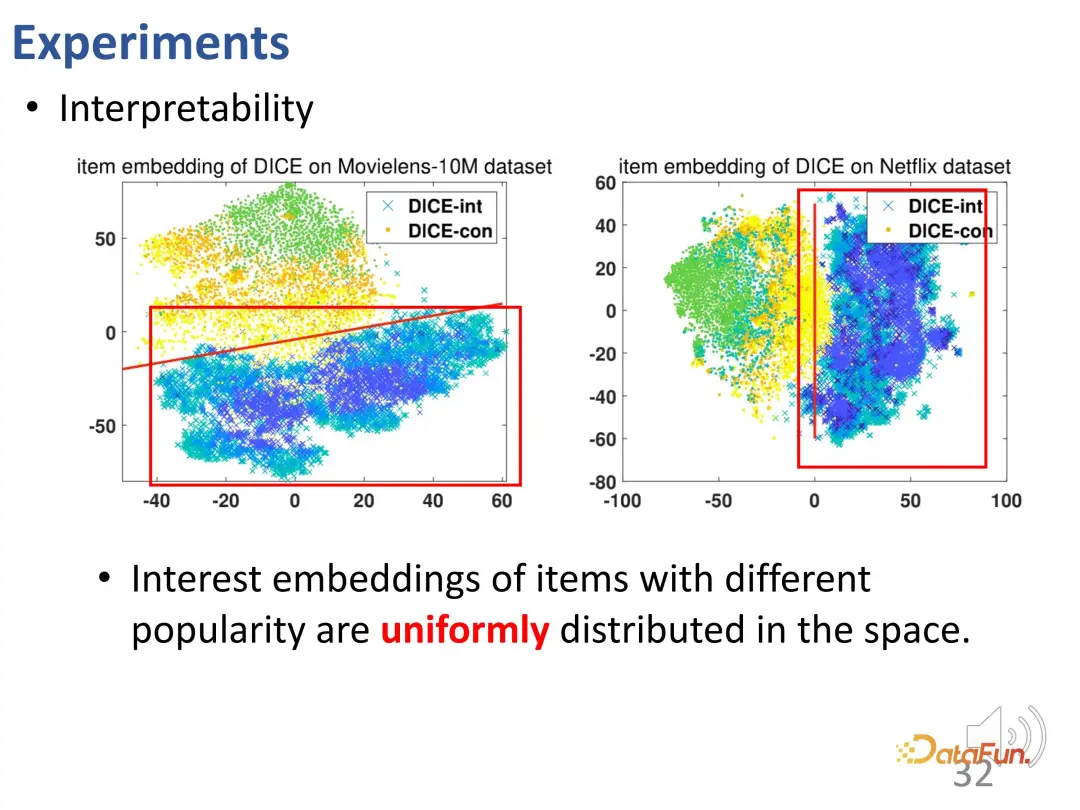 #DICE は、設計の意図した効果を実現します。さまざまな介入強度のデータに対してさらなるテストが行われ、その結果、さまざまな実験グループにおいて、DICE のパフォーマンスが IPS 手法よりも優れていることが示されました。
#DICE は、設計の意図した効果を実現します。さまざまな介入強度のデータに対してさらなるテストが行われ、その結果、さまざまな実験グループにおいて、DICE のパフォーマンスが IPS 手法よりも優れていることが示されました。
 要約すると、DICE は因果推論ツールを使用して、関心と適合のそれぞれに対応する表現ベクトルを学習し、非 IID 状況でも良好なパフォーマンスを提供します。そして解釈可能性。
要約すると、DICE は因果推論ツールを使用して、関心と適合のそれぞれに対応する表現ベクトルを学習し、非 IID 状況でも良好なパフォーマンスを提供します。そして解釈可能性。

2. 長期的な興味と短期的な興味の解きほぐし学習期的関心
2 番目の研究は主に、シーケンス推奨における長期的関心と短期的関心のもつれを解く問題を解決します。具体的には、ユーザーの関心は複雑であり、一部の関心は比較的安定したものは長期金利と呼ばれますが、金利の別の部分は突然発生する可能性があり、短期金利と呼ばれます。以下の例では、ユーザーは長期的には電子製品に興味がありますが、短期的には衣類を購入したいと考えています。これらの関心を適切に特定できれば、それぞれの行動の理由をより適切に説明でき、レコメンデーション システム全体のパフォーマンスを向上させることができます。
このような問題は、長期および短期の利益のモデル化と呼ぶことができます。つまり、長期的な利益を適応的にモデル化できます。さらに、ユーザーの現在の行動のどの部分が主に動かされているかを推測します。現在の行動を促進している興味を特定できれば、現在の興味に基づいてより適切な推奨を行うことができます。たとえば、ユーザーが短期間に同じカテゴリを閲覧する場合、それは短期的な興味である可能性がありますが、ユーザーが短期間に広範囲に探索する場合、以前に観察した長期的な興味をより参照する必要がある可能性があります。現在の興味に限定されるのではなく、興味のあること。一般に、長期的な利益と短期的な利益は性質が異なるため、長期的なニーズと短期的なニーズはよく分離される必要があります。 
一般的に言えば、協調フィルタリングは関心の動的な変化を無視するため、実際には長期的な関心を捕捉する方法であると考えることができます。既存のシーケンスの推奨事項は、短期的な利益のモデリングに重点を置いているため、長期的な利益が忘れられてしまいます。また、たとえ長期的な利益が考慮されていても、モデリングの際には依然として主に短期的な利益に依存しています。したがって、既存の方法では、これら 2 つの関心を組み合わせて学習するという点ではまだ不十分です。 
最近の研究では、短期モジュールと長期モジュールを別々に設計し、直接組み合わせることで、長期および短期の利益のモデリングを検討し始めています。一緒に。しかし、これらの手法では、最終的に学習されるユーザーベクトルは 1 つだけであり、その中には短期信号と長期信号の両方が含まれており、この 2 つは依然として絡み合った状態であり、さらなる改善が必要です。
しかし、長期的な利益と短期的な利益を分離することは依然として困難です:
- まず第一に、長期的な関心と短期的な関心は、実際にはまったく異なるユーザーの好みを反映しており、その特性も異なります。長期の関心は比較的安定した一般的な関心ですが、短期の関心は動的であり、急速に変化する可能性があります。
- #第二に、長期利益と短期利益に対する明示的なラベルがありません。収集される最終データのほとんどは実際には最終的な動作であり、それがどの種類の関心事に属するかについての根拠となる真実はありません。
- #最後に、長期的および短期的な利益のどの部分が現在の行動を推進しているのか、またどの部分がより重要であるのかも不明です。
#この問題に対応して、長期的な関心と短期的な関心を同時にモデル化する比較学習方法が提案されています。 (推奨のための長期的関心と短期的関心の対照学習フレームワーク (CLSR))
1. 長期的関心と短期的関心の分離
# #最初の課題は、長期利益と短期利益を分離することであり、長期利益と短期利益のそれぞれに対応する進化メカニズムを確立します。構造因果モデルでは、長期利益は時間とは無関係に設定され、短期利益は直前の瞬間の短期利益と一般的な長期利益によって決定されます。つまり、モデル化プロセス中、長期金利は比較的安定していますが、短期金利はリアルタイムで変化します。
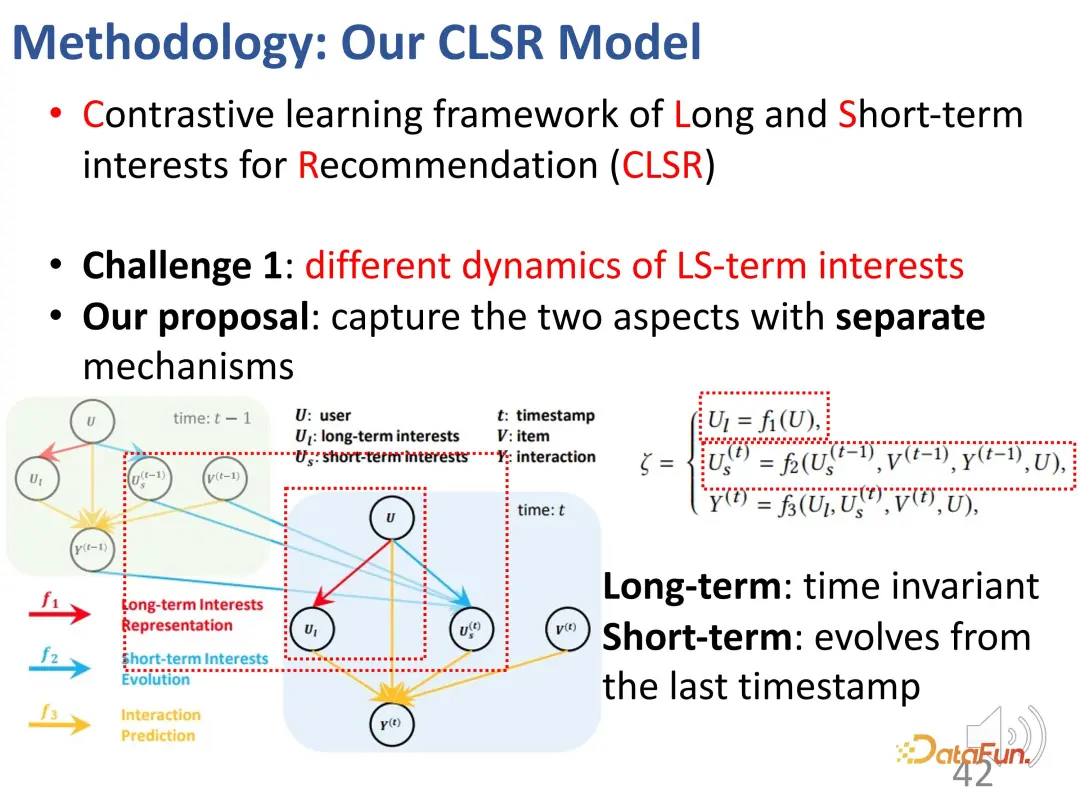
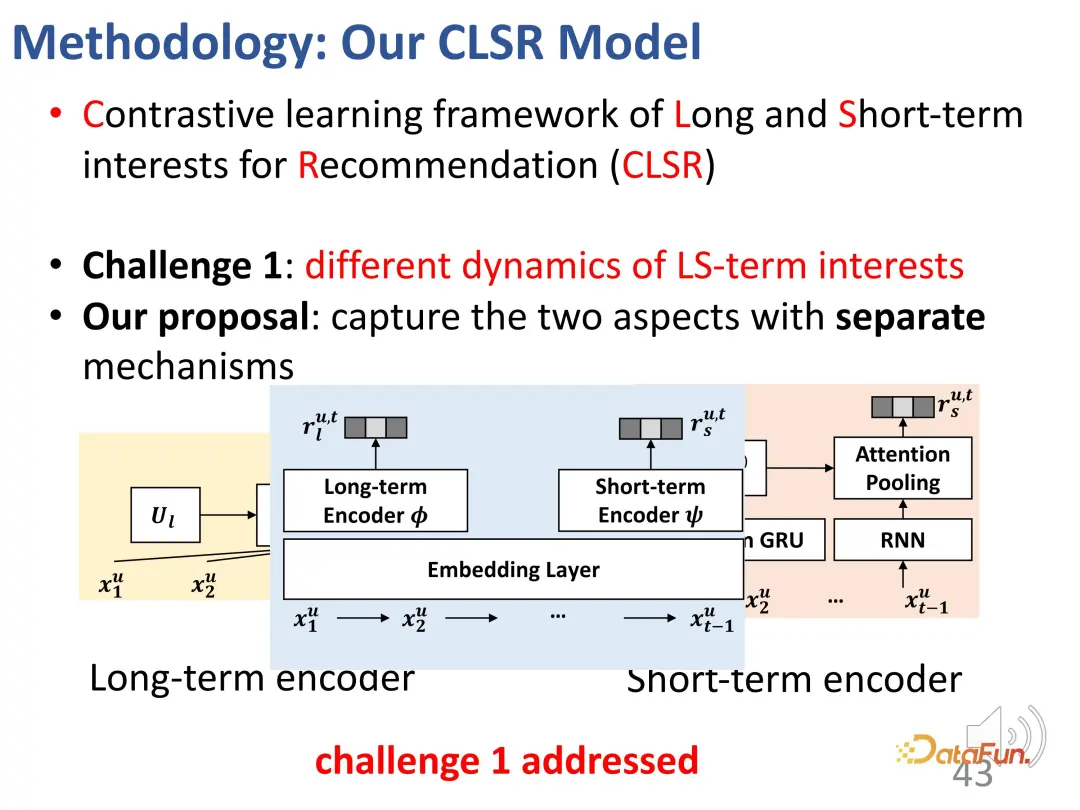
#2. 対照学習は、明示的な監視信号の欠如を解決します
2 番目の課題は、2 つの部分からなる利益に対する明示的な監視シグナルが欠如していることです。この問題を解決するために、監視のために対照的な学習方法が導入され、明示的なラベルを置き換えるために代理ラベルが構築されます。
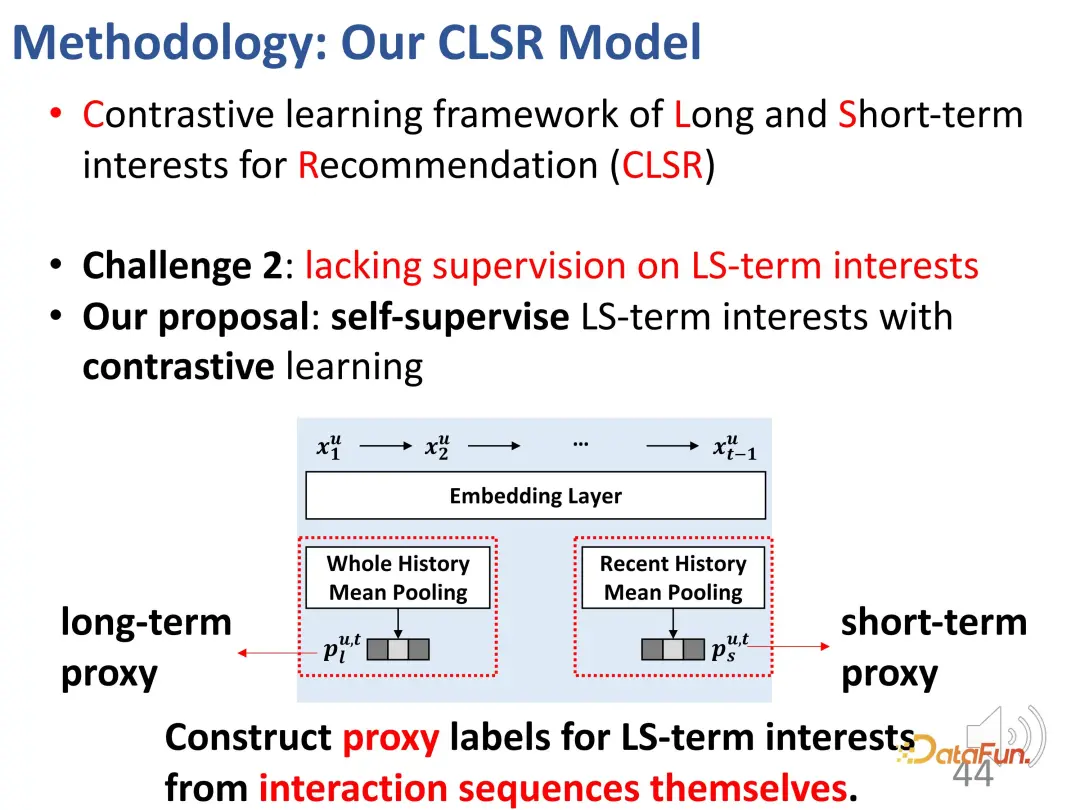
エージェント ラベルは 2 つの部分に分かれており、1 つは長期的な関心を持つエージェント用で、もう 1 つは短期的な興味を持つエージェント用です。興味のあること。
長期関心の学習において、プールの履歴全体を長期関心の代理ラベルとして使用すると、表現が学習されます。エンコーダによりこの方向を最適化します。
同じことが短期的な関心にも当てはまります。ユーザーの最近の行動の平均プールが短期的な代用として使用されます。同様に、それはユーザーの関心を直接表すものではありませんが、 、ユーザーの短期的な興味を反映している可能性があるため、学習プロセス中は可能な限りこの方向に最適化してください。
このようなエージェント表現は厳密には利益を表すものではありませんが、最適化の方向を表します。長期関心表現と短期関心表現の場合、それらは対応する表現に可能な限り近くなり、他の方向の表現から遠ざかり、それによって対比学習のための制約関数を構築します。同様に、プロキシ表現は実際のエンコーダ出力に可能な限り近づける必要があるため、対称的な 2 つの部分からなる損失関数となり、この設計により、前述の監視信号の不足が効果的に補われます。
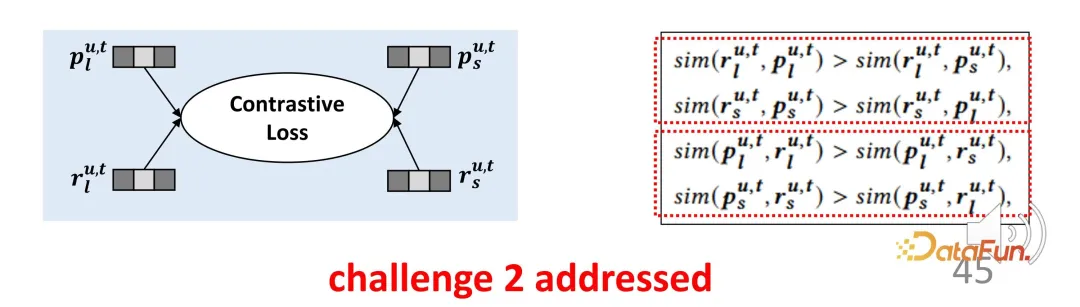
3. 長期と短期の関心の重みの区別
3 番目の課題は、特定の行動に対する関心のある 2 つの部分の重要性を判断することです。解決策は、2 つの関心事を適応的にマージすることです。この部分の設計は比較的シンプルで簡単です。これは、表現ベクトルの 2 つの部分がすでに存在しており、それらを混合するのは難しくないためです。具体的には、2 つの部分の利益のバランスをとるために重み α を計算する必要がありますが、α が比較的大きい場合は、現在の利益が主に長期的な利益によって支配され、その逆の場合も同様です。最後に、相互作用挙動の推定値が取得されます。
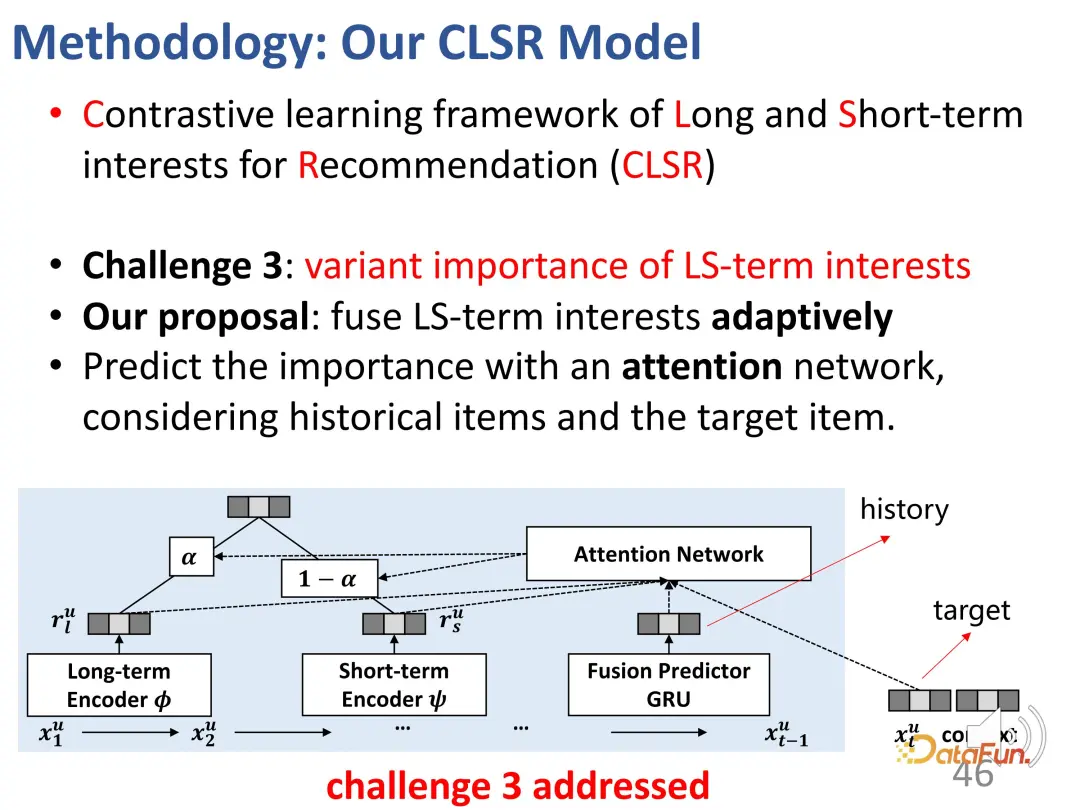
予測の場合、一方では上記の一般的な推奨システムの損失であり、他方では損失関数です。対照的な学習の重要性は、参加するという形で重み付けされます。

全体的なブロック図は次のとおりです:
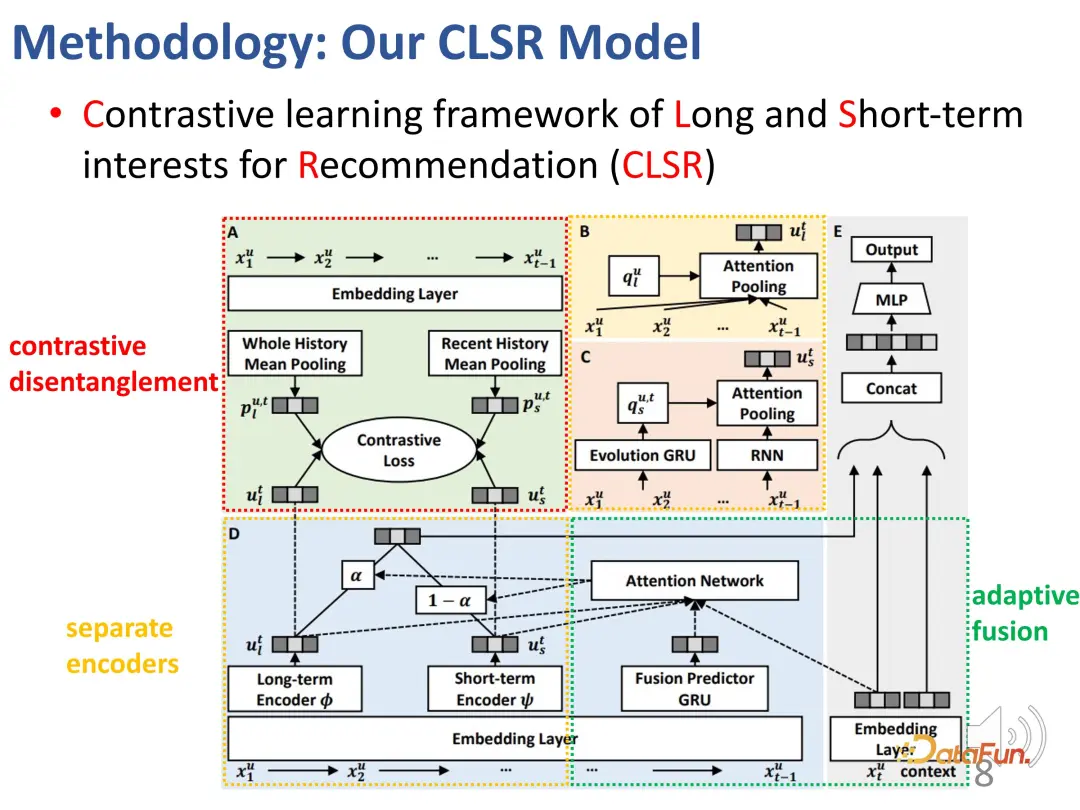
##ここでは、2 つの個別のエンコーダー (BCD)、対応するエージェント表現と対比学習の目標 (A)、および 2 つの部分を適応的にブレンドする興味を示します。
この作業では、淘宝網の e コマース データ セットや Kuaishou のショート ビデオ データ セットなどのシーケンス推奨データ セットが使用されました。方法は長期、短期、長期と短期の組み合わせの3種類に分けられます。
4. 実験結果

実験結果全体を観察すると、次のことがわかります。短期的な関心が考慮される モデルは、長期的な関心のみを考慮するモデルよりもパフォーマンスが優れています。つまり、逐次推奨モデルは、一般に、純粋に静的な協調フィルタリング モデルよりも優れています。短期的な関心のモデリングにより、現在の行動に最も大きな影響を与える最近の関心の一部をより適切に特定できるため、これは合理的です。
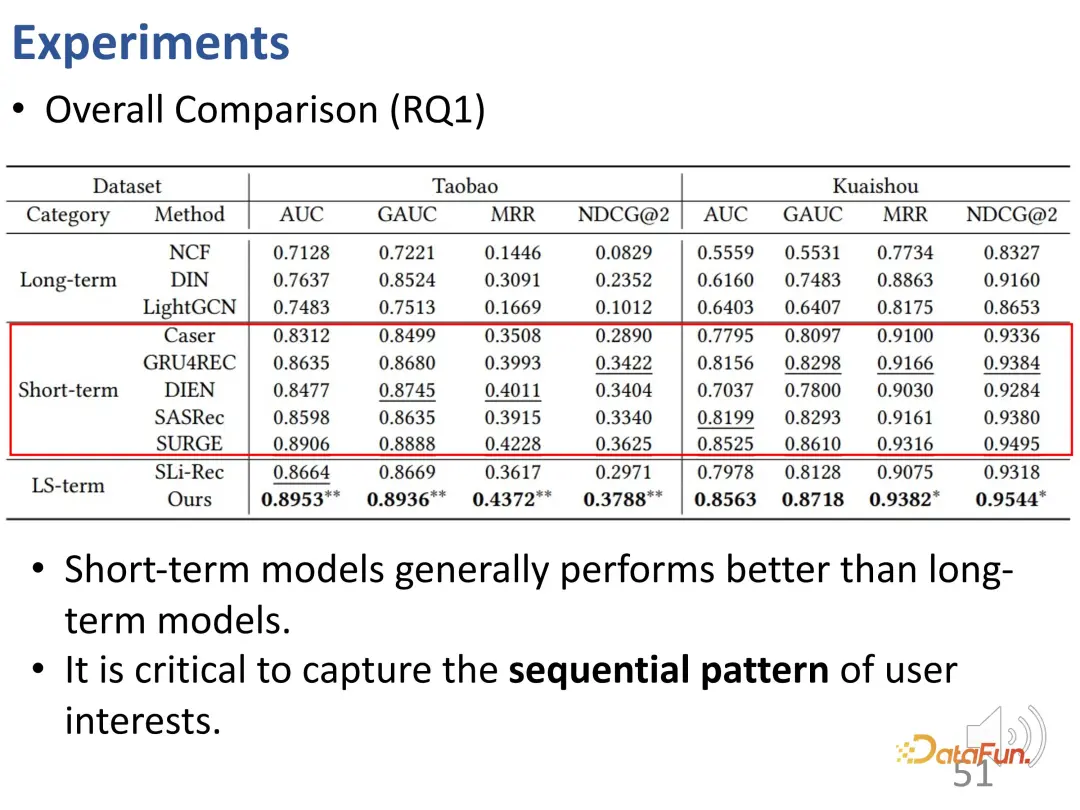
2 番目の結論は、長期的利益と短期的利益を同時にモデル化する SLi-Rec モデルが、必ずしも従来のシーケンスよりも優れているわけではないということです。オススメモデルです。これは既存の作品の欠点を浮き彫りにします。その理由は、2 つのモデルを混合するだけでバイアスやノイズが生じる可能性があるためです。ここでわかるように、実際には最良のベースラインは逐次的な短期金利モデルです。
私たちが提案した長期利益と短期利益の分離手法は、長期利益と短期利益の間のもつれ解除モデリング問題を解決し、2 つのデータセットと 4 つのデータセットで安定性を達成できます。インジケーター、最良の結果。
この解きほぐし効果をさらに調査するために、長期および短期の関心に対応する 2 つの部分の表現について実験が実行されました。 CLSR 学習の長期的関心、短期的関心、および Sli-Rec 学習の 2 つの関心を比較してください。実験結果は、私たちの研究 (CLSR) が各部分で一貫してより良い結果を達成できることを示し、また、長期利益モデリングと短期利益モデリングを融合する必要性も証明しています。なぜなら、両方を使用すると、最良の結果は利益を統合できるからです。 。
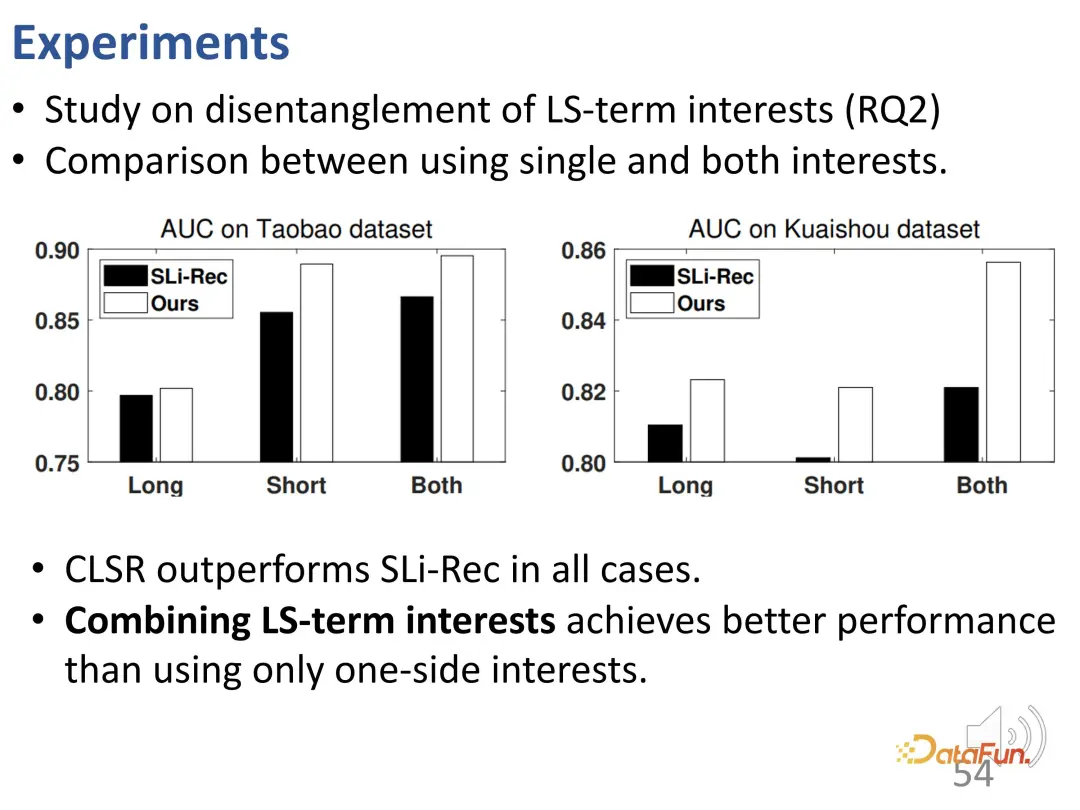
さらに、購入行動といいね行動を比較調査に使用します。これらの行動のコストはクリックよりも高いためです。購入にはお金がかかり、クリックには「いいね!」がかかります。運営にはコストがかかるため、これらの利益は実際には、安定した長期的な利益に対するより強い選好を反映しています。まず、パフォーマンスの比較に関しては、CLSR の方が優れた結果を達成しています。さらに、モデリングの 2 つの側面の重み付けはより合理的です。 CLSR は、長期的な利益に偏った行動に対して SLi-Rec モデルよりも大きな重みを割り当てることができ、これは前述の動機と一致しています。

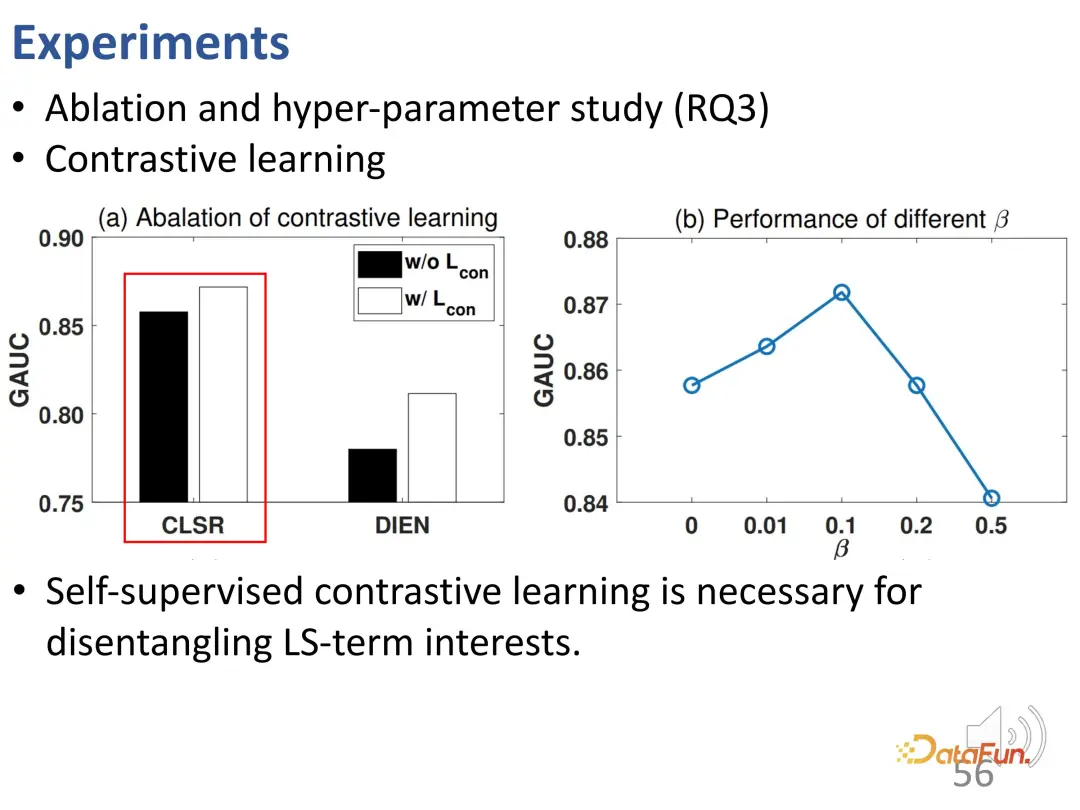
さらにアブレーション実験とハイパーパラメータ実験が行われました。まず、対照学習の損失関数が除去され、パフォーマンスが低下することがわかりました。これは、対照学習が長期的な関心と短期的な関心を解きほぐすために非常に必要であることを示しています。この実験は、CLSR が既存の手法に基づいて動作することもでき (自己教師あり対比学習は DIEN のパフォーマンスを向上させることができる)、プラグアンドプレイ手法であるため、CLSR がより優れた一般的なフレームワークであることをさらに証明します。 β に関する研究により、妥当な値は 0.1 であることがわかりました。
# 次に、適応融合と単純融合の関係をさらに詳しく検討します。適応重み融合は、すべての異なる α 値で安定して固定重み融合よりも優れたパフォーマンスを発揮します。これにより、各相互作用の動作が異なるサイズの重みによって決定される可能性があることが検証され、適応融合と最終的な動作予測の必要性によって目的の融合が達成されることが検証されます。
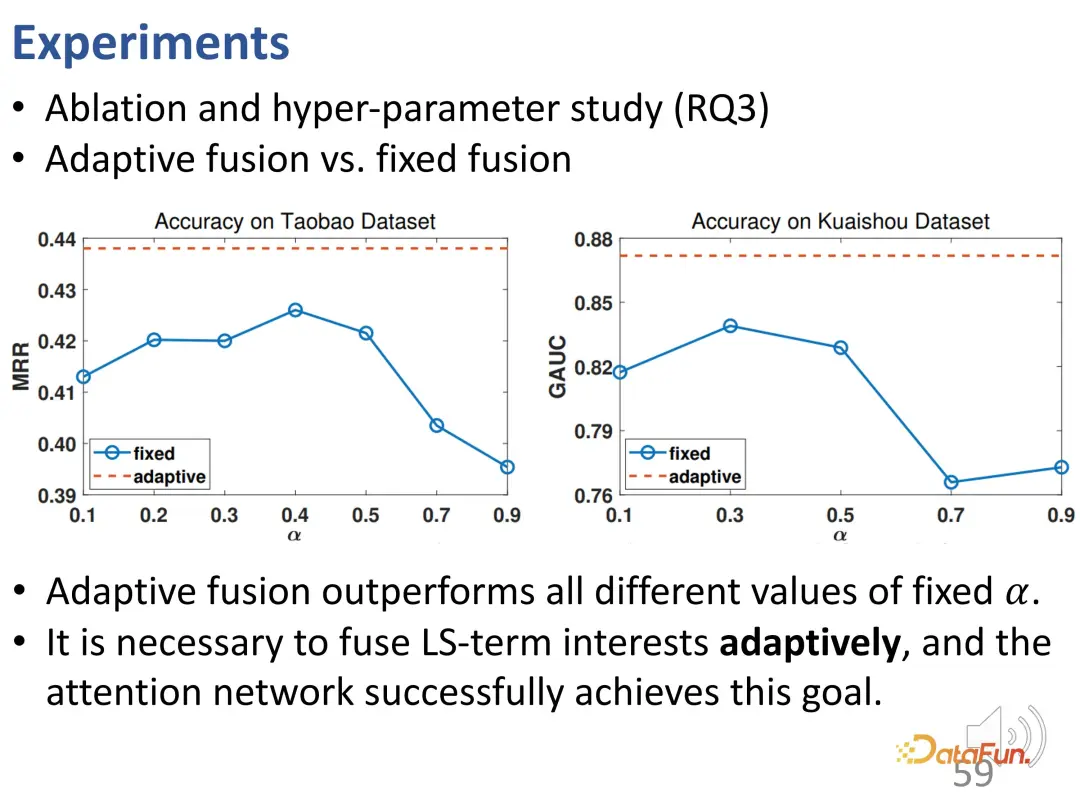
この研究では、配列関心における長期関心と短期関心をモデル化し、対応する表現ベクトルをそれぞれ学習する対照的な学習方法を提案します。解きほぐしを達成するために。実験結果は、この方法の有効性を示しています。

3. 短いビデオの推奨事項のバイアスを軽減する
先に紹介した2つの作品は、利害関係の解きほぐしに焦点を当てています。 3 番目の研究は、興味学習の行動修正に焦点を当てています。
短いビデオのレコメンデーションは、レコメンデーション システムの非常に重要な部分になっています。ただし、既存の短いビデオの推奨システムは依然として長いビデオの推奨パラダイムに従っており、いくつかの問題が発生する可能性があります。
たとえば、短いビデオのレコメンデーションにおけるユーザーの満足度とアクティビティをどのように評価するのでしょうか?最適化の目標は何ですか?一般的な最適化目標は、総再生時間または進行状況の監視です。完了率と視聴時間がより高いと推定される短いビデオは、推奨システムによって上位にランク付けされる場合があります。トレーニング中の視聴時間に基づいて最適化され、サービス中の推定視聴時間に基づいて並べ替えられ、視聴時間が長いビデオが推奨されます。
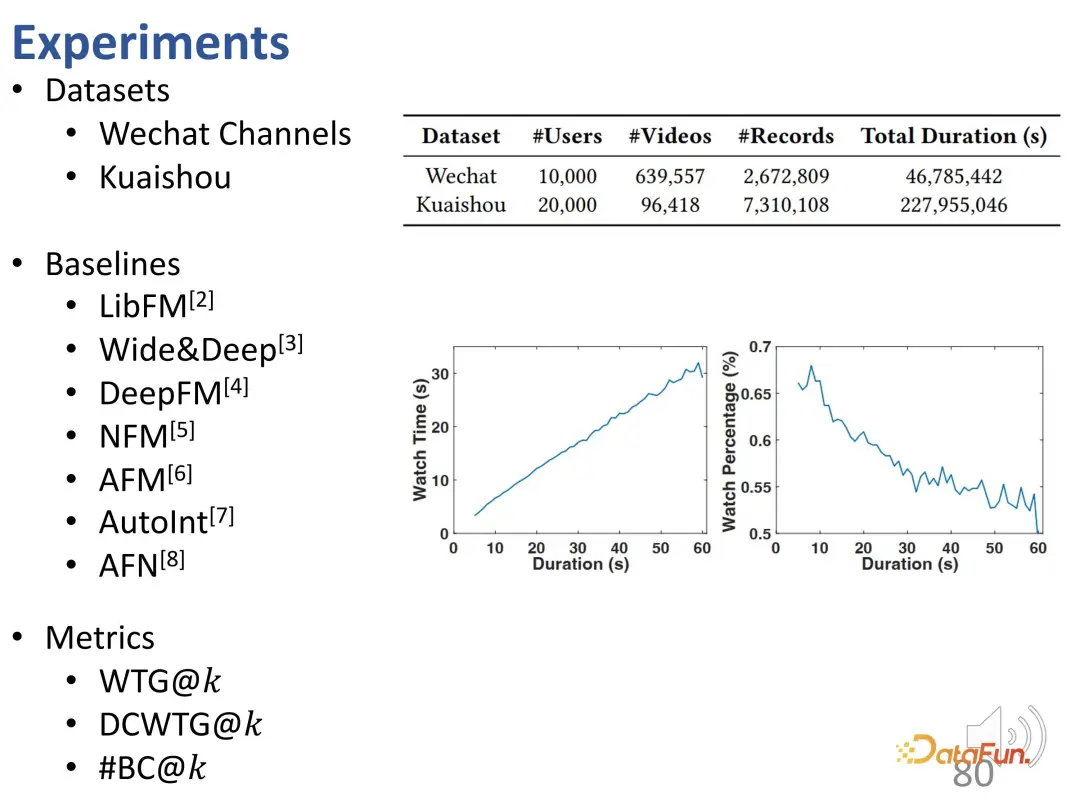
ただし、短いビデオのレコメンデーションの問題は、視聴時間が長くても、必ずしもユーザーがその短いビデオに非常に興味があること、つまり短いビデオ自体の長さを意味するとは限らないことです。は非常に重要な逸脱です。上記の最適化目標 (視聴時間または視聴の進行状況) を使用するレコメンデーション システムでは、長いビデオには当然の利点があります。この種の長いビデオをあまりにも多く推奨すると、ユーザーの興味と一致しない可能性がありますが、ユーザーがビデオをスキップすることによる運営コストにより、実際のオンライン テストやオフライン トレーニングの評価は非常に高くなります。したがって、総再生時間だけに頼るのは十分ではありません。
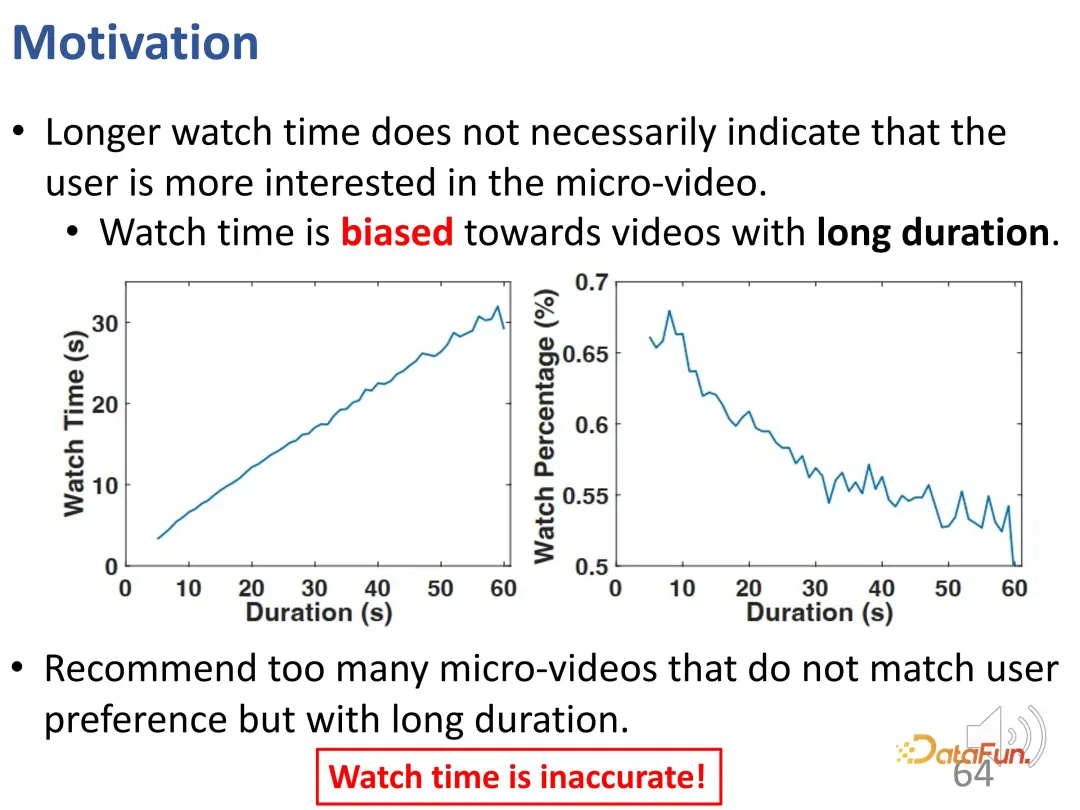
ご覧のとおり、短いビデオには 2 つのフォームがあります。 1 つは vlog のような長いビデオで、もう 1 つは短いエンターテイメント ビデオです。実際のトラフィックを分析した結果、基本的に長い動画を公開するユーザーの方が推奨トラフィックが多く、この比率は大きく異なることがわかりました。総再生時間だけを評価に使用することは、ユーザーの興味に応えられないだけでなく、不公平になる可能性があります。
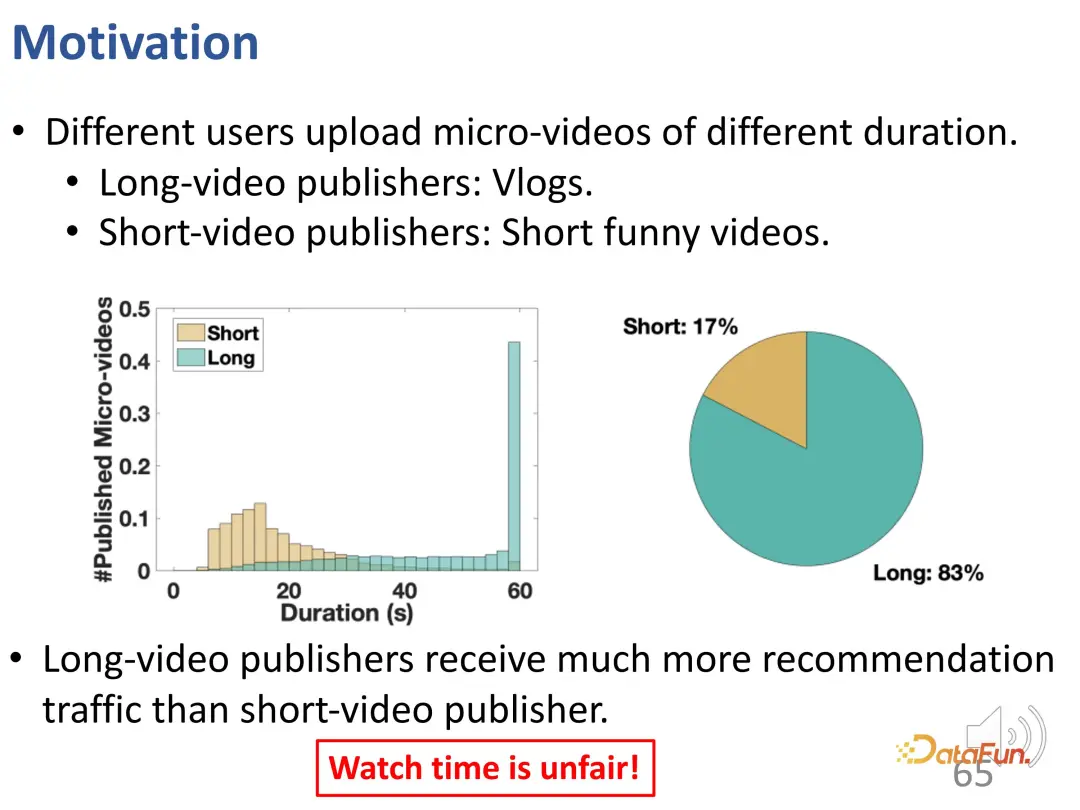
この作業では、次の 2 つの問題を解決したいと考えています。ユーザーの満足度を公平に評価する方法。
- #この偏りのないユーザーの関心を学習して、適切な推奨事項を提供する方法。
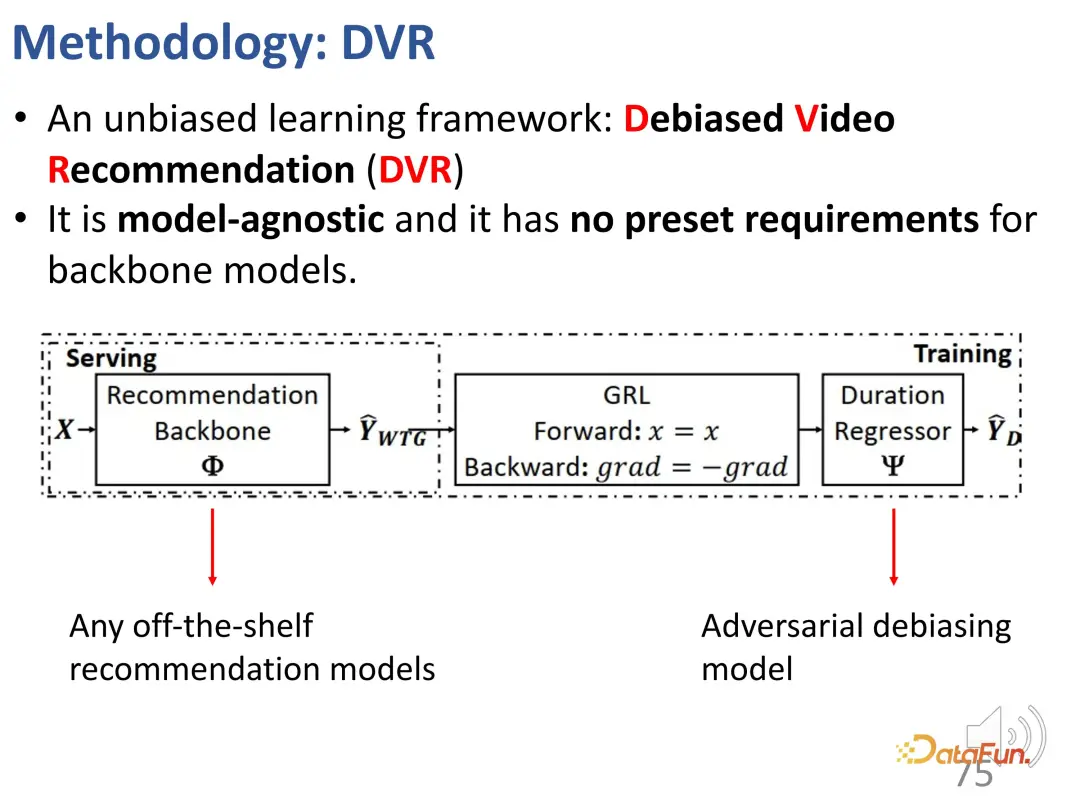
- #実際、中心的な課題は、長さが異なる短いビデオを直接比較できないことです。この問題は自然であり、さまざまなレコメンダー システムで遍在しており、さまざまなレコメンダー システムの構造は大きく異なるため、設計された方法はモデルに依存しない必要があります。
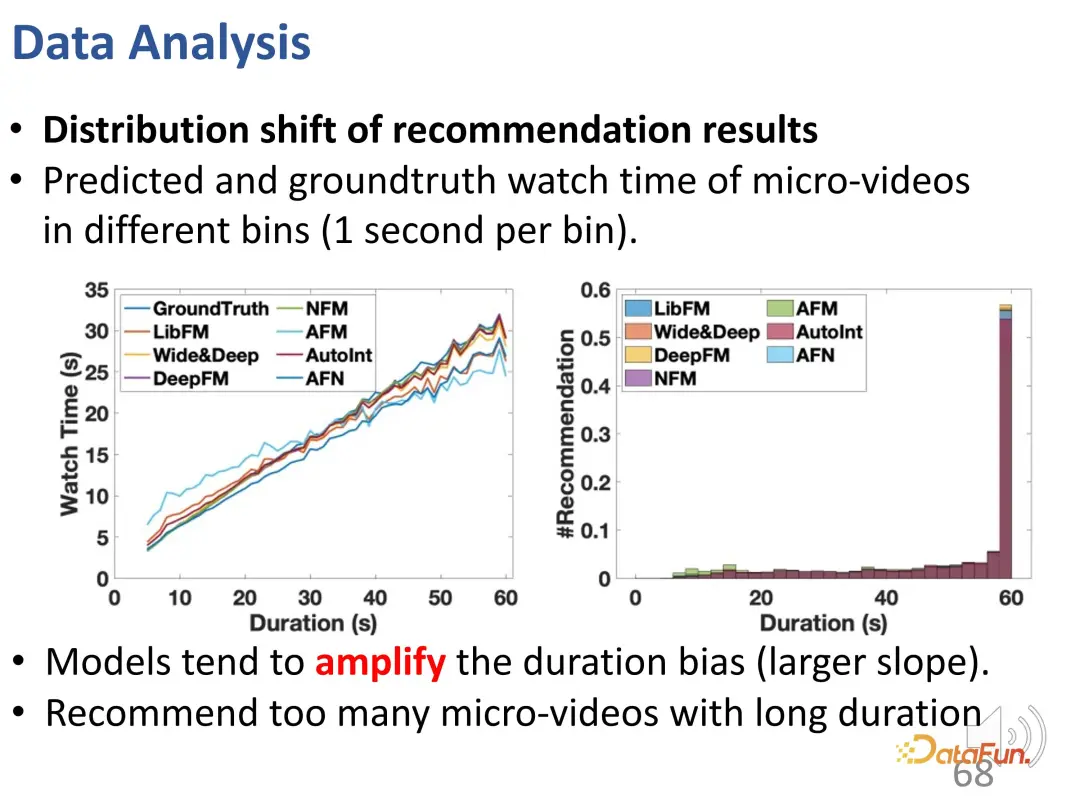
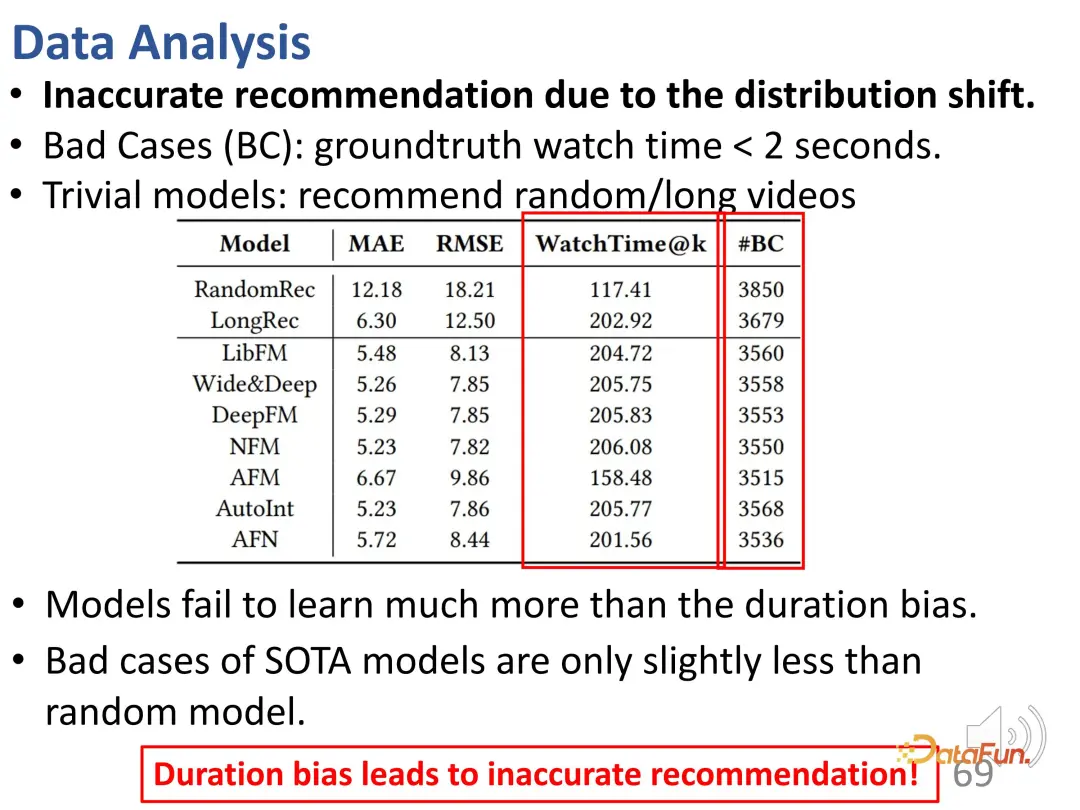
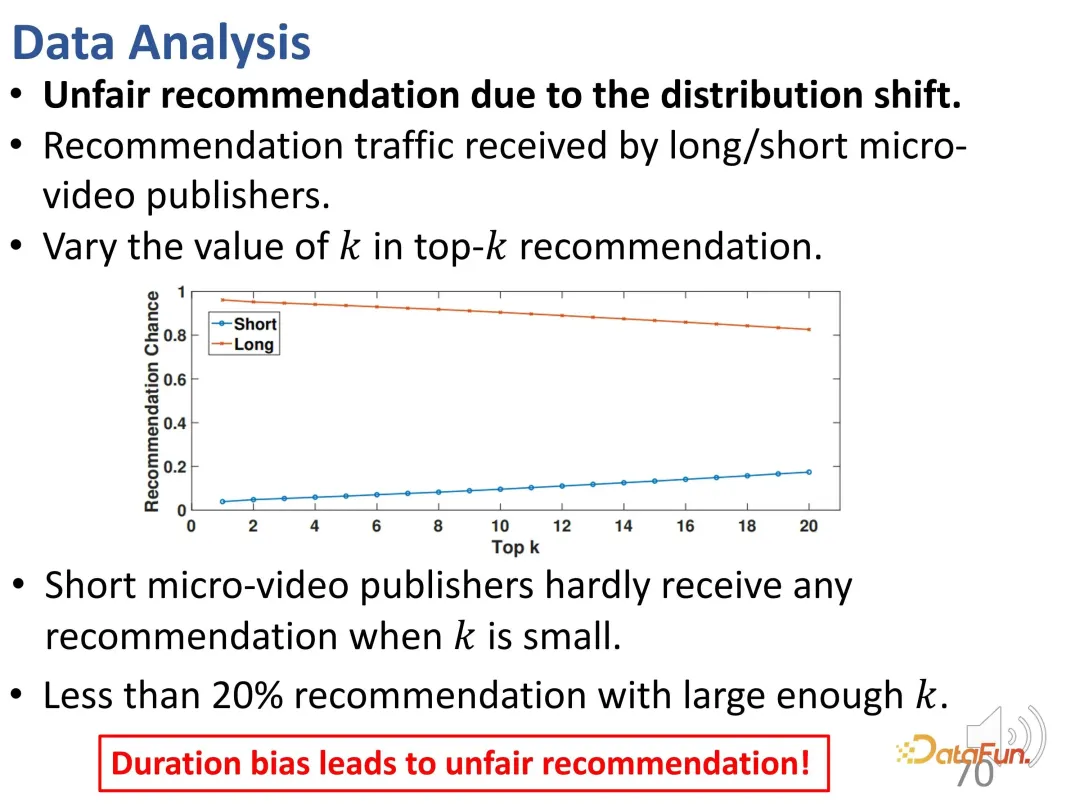
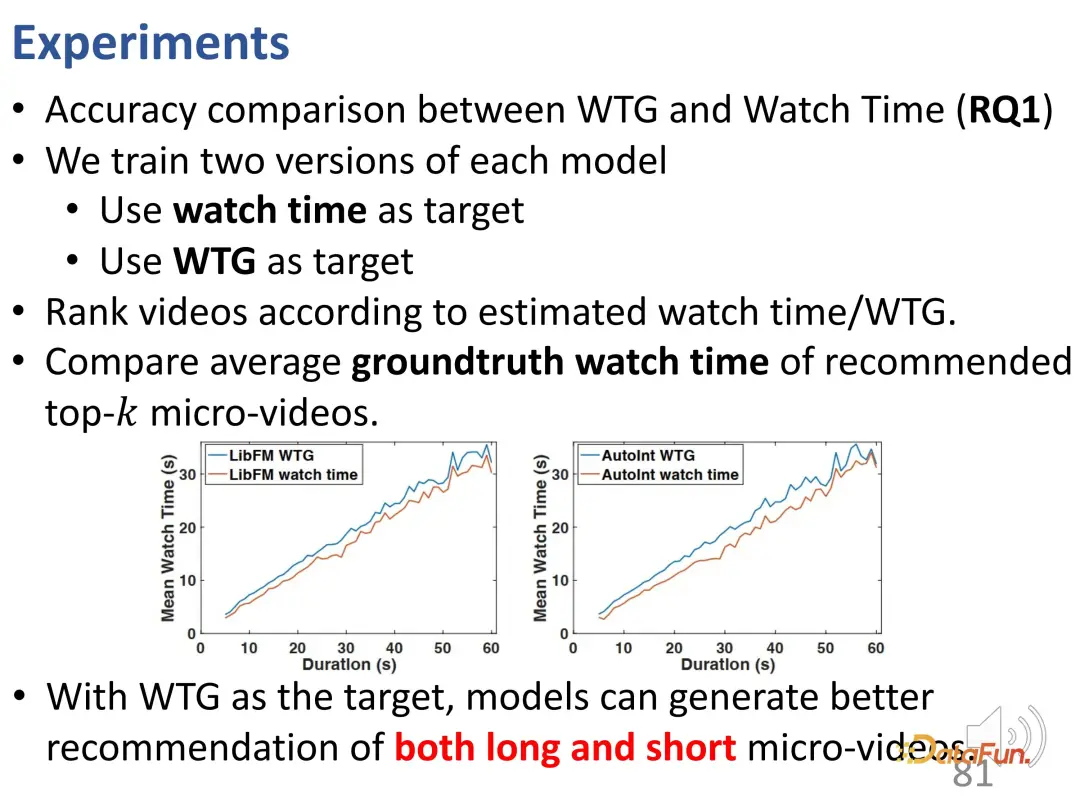
曲線から、継続時間の偏差が強化されていることがわかります。グランドトゥルース曲線と比較して、長時間のビデオ視聴の予測結果では、推奨モデルの方が大幅に高くなっています。時間。予測モデルでは、長いビデオの過剰な推奨には問題があります。 また、レコメンド結果には不正確なレコメンド(#BC)が多く含まれていることも判明しました。 #悪いケース、つまり、視聴時間が 2 秒未満で、ユーザーが非常に嫌がる動画がいくつか見られます。ただし、バイアスの影響により、これらの動画は誤って推奨されます。つまり、モデルは推奨された動画の長さの違いのみを学習し、基本的には動画の長さしか区別できませんでした。なぜなら、望ましい予測結果は、ユーザーの視聴時間を増やすために長いビデオを推奨することだからです。したがって、モデルはユーザーが好きな動画ではなく、長い動画を選択します。これらのモデルにはランダムな推奨と同じ数の悪いケースさえ含まれていることがわかり、このバイアスにより非常に不正確な推奨がもたらされます。 さらに、ここには不公平の問題があります。コントロールのトップ k 値が小さい場合、短いビデオ パブリッシャーを推奨することは困難です。k 値が十分に大きい場合でも、そのような推奨の割合は 20% 未満です。 まず、すべての動画を等間隔で異なる再生時間グループに分割し、各再生時間グループにおけるユーザーの関心の度合いを比較します。固定期間グループでは、ユーザーの興味を期間で表すことができます。 WTG の導入後、WTG は実際には、元の継続時間に注意を払うことなく、ユーザーの興味の強さを表現するために直接使用されます。 WTG の評価では、分布はより均等になります。
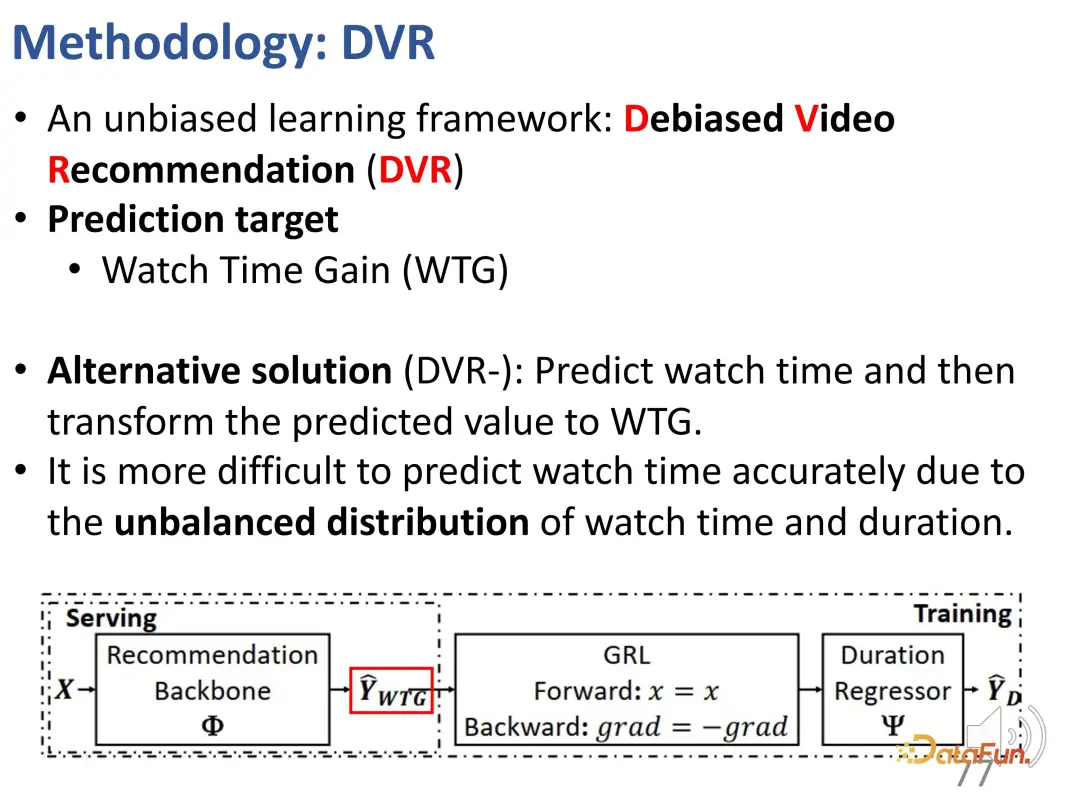
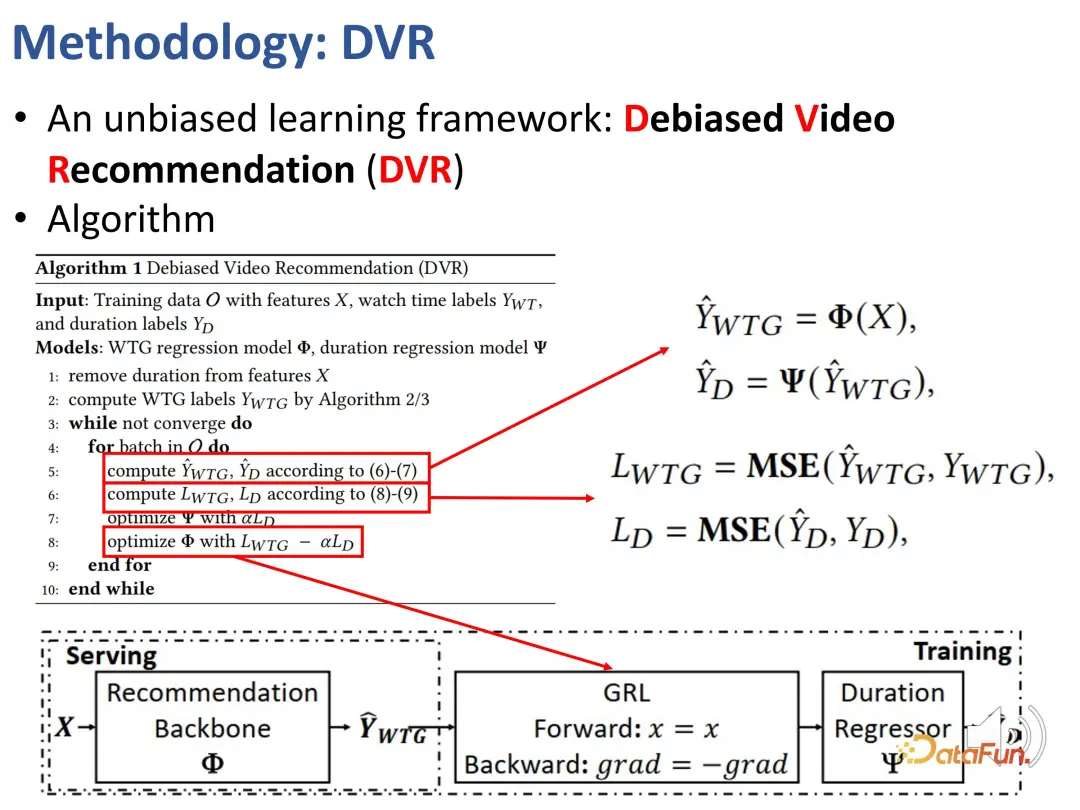
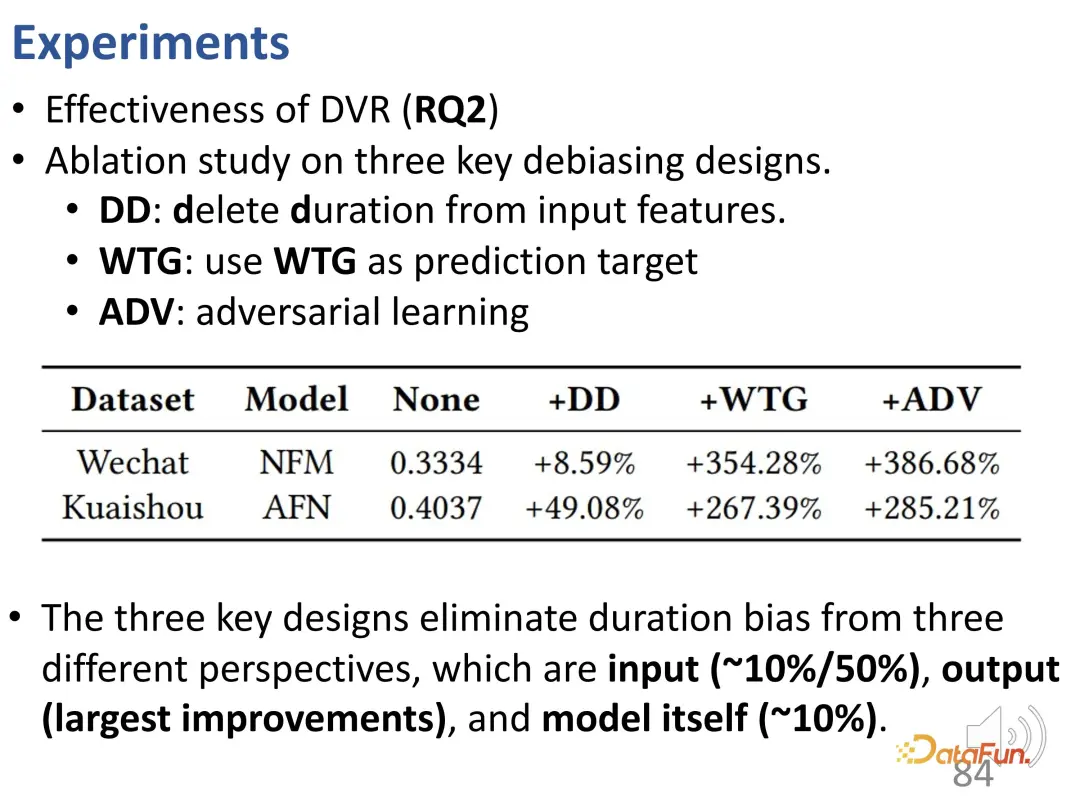
以前、期間に関係なくユーザーの関心を反映できる指標、つまり WTG と NDWTG を定義しました。次に、バイアスを排除でき、特定のモデルに依存せず、さまざまなバックボーンに適用できる推奨方法を設計します。 DVR (Debiased Video Recommendation) という手法が提案されており、その中心的な考え方は、推奨モデルにおいて、入力特徴量が複雑で継続時間に関する情報が含まれている可能性がある場合でも、継続時間に関連する特徴量を削除できれば、モデルの出力がこれらの期間の特徴を無視する場合、その出力は不偏であると見なすことができ、これはモデルが期間に関連する特徴をフィルタリングして不偏の推奨を達成できることを意味します。これには、推奨モデルの出力に基づいて継続時間を予測する別のモデルが必要であるという対立的な考え方が含まれますが、正確に継続時間を予測できない場合は、前のモデルの出力には継続時間の特徴が含まれていないと見なされます。したがって、敵対的学習方法を使用して推奨モデルに回帰層を追加し、予測された WTG に基づいて元の継続時間を予測します。バックボーン モデルが確かに偏りのない結果を達成できる場合、回帰層は元の期間を再予測して復元することはできません。 3. 実験結果
最後に、この共有内容をまとめます。まず、ユーザーの興味と適合性に関するエンタングルメント学習を理解します。次に、長期的利益と短期的利益のもつれの解消が、逐次行動モデリングの観点から研究されます。最後に、短いビデオの推奨における視聴時間の最適化の問題を解決するためのバイアス除去学習方法を提案します。 以上が今回のシェア内容となります、よろしくお願いいたします。 [1] Gao et al. Causal Inference in Recommender Systems: A Survey and Future Directions、TOIS 2024 [2] Zheng et al. Disentangling User Interest and Conformity for Recommendation with Causal Embedding, WWW 2021. [3] Zheng et al. DVR: 視聴を最適化するマイクロビデオ レコメンデーション-期間バイアス下の時間利得、MM 2022 [4] Zheng et al. Disentangling Long and Short-Term Interests for Recommendation、WWW 2022.
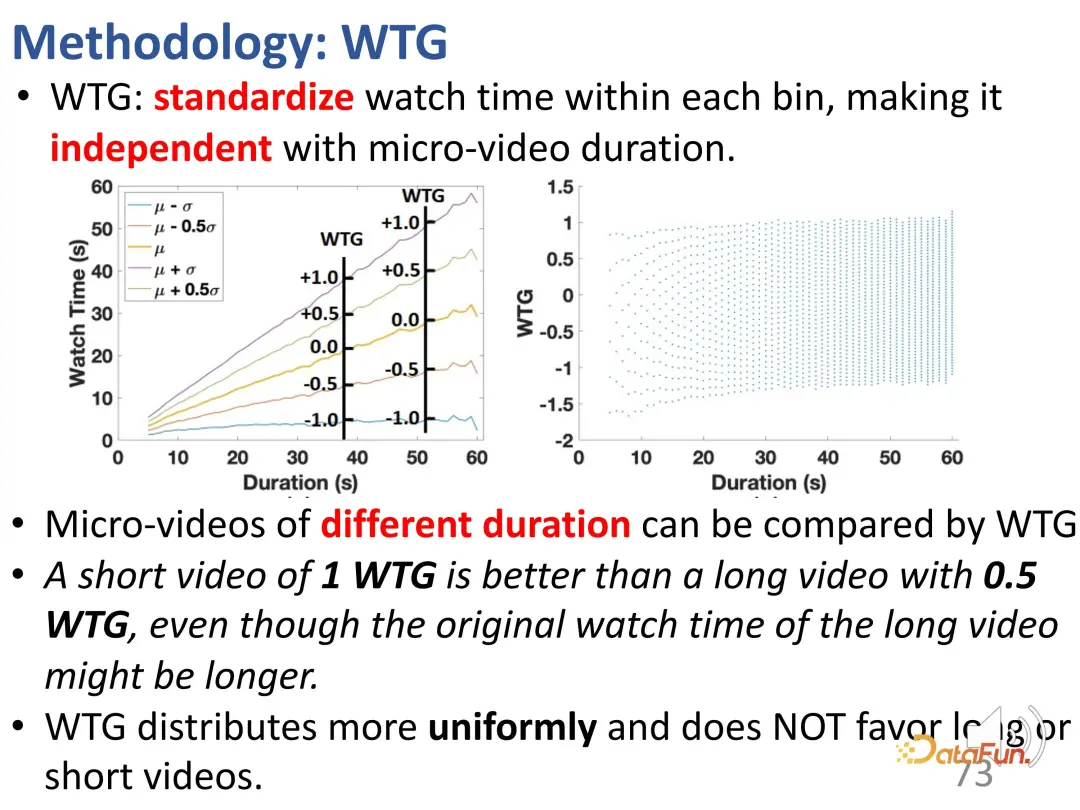
この問題を解決するために、私たちは最初に と呼ばれる方法を提案しました。 WTG (視聴時間ゲインと呼ばれる新しい指標。公平性を図るために視聴時間を考慮に入れます。たとえば、ユーザーは 60 秒のビデオを 50 秒間視聴しましたが、別のビデオも 60 秒の長さでしたが、視聴されたのは 5 秒だけでした。 60 秒のビデオを制御すると、2 つのビデオ間の関心の違いは明らかです。これはシンプルですが効果的なアイデアで、再生時間は他のビデオ データの時間が同じである場合にのみ意味を持ちます。

 #WTG に基づいて、並べ替え位置の重要性がさらに考慮されます。 WTG は 1 つの指標 (単一ポイント) のみを考慮するため、この累積効果がさらに考慮されます。つまり、ソートされたリスト内の各要素のインデックスを計算するときは、各データ ポイントの相対位置も考慮する必要があります。この考え方はNDCGと似ています。したがって、これに基づいて DCWTG が定義されました。
#WTG に基づいて、並べ替え位置の重要性がさらに考慮されます。 WTG は 1 つの指標 (単一ポイント) のみを考慮するため、この累積効果がさらに考慮されます。つまり、ソートされたリスト内の各要素のインデックスを計算するときは、各データ ポイントの相対位置も考慮する必要があります。この考え方はNDCGと似ています。したがって、これに基づいて DCWTG が定義されました。 2. バイアスを排除するための推奨方法




関連文献:
以上が因果推論に基づく推奨システム: レビューと展望の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。