
ホームページ >テクノロジー周辺機器 >AI >Llama アーキテクチャは GPT2 より劣っていますか?魔法のトークンで記憶力が10倍になる?
Llama アーキテクチャは GPT2 より劣っていますか?魔法のトークンで記憶力が10倍になる?

- WBOY転載
- 2024-04-10 15:13:131306ブラウズ
7B スケール言語モデル LLM はどれだけの人間の知識を保存できるでしょうか?この値を数値化するにはどうすればよいでしょうか?トレーニング時間とモデル アーキテクチャの違いはこの値にどのような影響を与えるでしょうか?浮動小数点圧縮の量子化、混合エキスパート モデルの MoE、およびデータ品質の違い (百科事典の知識とインターネットのゴミ) は、LLM の知識容量にどのような影響を及ぼしますか?
Zhu Zeyuan (Meta AI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.3: 知識の法則のスケーリング」では、大規模な実験 (合計 50,000 のタスク、 4,200,000 GPU 時間 ) は 12 の法則を要約し、さまざまな文書に基づく LLM の知識容量のより正確な測定方法を提供します。

著者はまず、ベンチマーク データ セット (ベンチマーク) でのオープン ソース モデルのパフォーマンスを通じて LLM のスケーリング則を測定するのは非現実的であると指摘します。 )。たとえば、LLaMA-70B はナレッジ データ セットで LLaMA-7B より 30% 優れたパフォーマンスを示しますが、これはモデルを 10 倍に拡張しても容量が 30% しか増加しないという意味ではありません。モデルがネットワーク データを使用してトレーニングされた場合、モデルに含まれる知識の総量を推定することも困難になります。
別の例として、Mistral モデルと Llama モデルの品質を比較するとき、その違いはモデル アーキテクチャの違いによって引き起こされるのでしょうか、それともトレーニング データの準備の違いによって引き起こされるのでしょうか。 ?
上記の考察に基づいて、著者は、人工的に合成されたデータを作成し、その量と量を厳密に制御するという、論文「言語モデル物理学」シリーズの核となるアイデアを採用しています。データ内の知識の種類 データ内の知識ビットを調整します。同時に、著者はさまざまなサイズとアーキテクチャの LLM を使用して合成データでトレーニングし、トレーニングされたモデルがデータから学習した知識ビット数を正確に計算するための数学的定義を与えます。

- #論文アドレス: https://arxiv.org/pdf/2404.05405.pdf
- 論文のタイトル: 言語モデルの物理学: パート 3.3、知識能力のスケーリング法則
この研究については、誰か ITこの方向性を示すのが合理的だと思われます。スケーリングの法則を非常に科学的な方法で分析できます。
また、この研究がスケーリングの法則を異なるレベルに引き上げたと信じている人もいます。実務者必読の論文であることは間違いありません。
研究の概要
著者らは、bioS、bioR、bioD の 3 種類の合成データを研究しました。 bioS は英語のテンプレートを使用して書かれた伝記、bioR は LlaMA2 モデル (合計 22 GB) を利用して書かれた伝記、bioD は詳細をさらに制御できる一種の仮想知識データ (知識の長さや知識の長さなど)語彙は制御できます(詳細はお待ちください)。著者 は、GPT2、LlaMA、および Mistral に基づく言語モデル アーキテクチャに焦点を当てています。その中で、GPT2 は更新された Rotary Position Embedding (RoPE) テクノロジを使用しています。
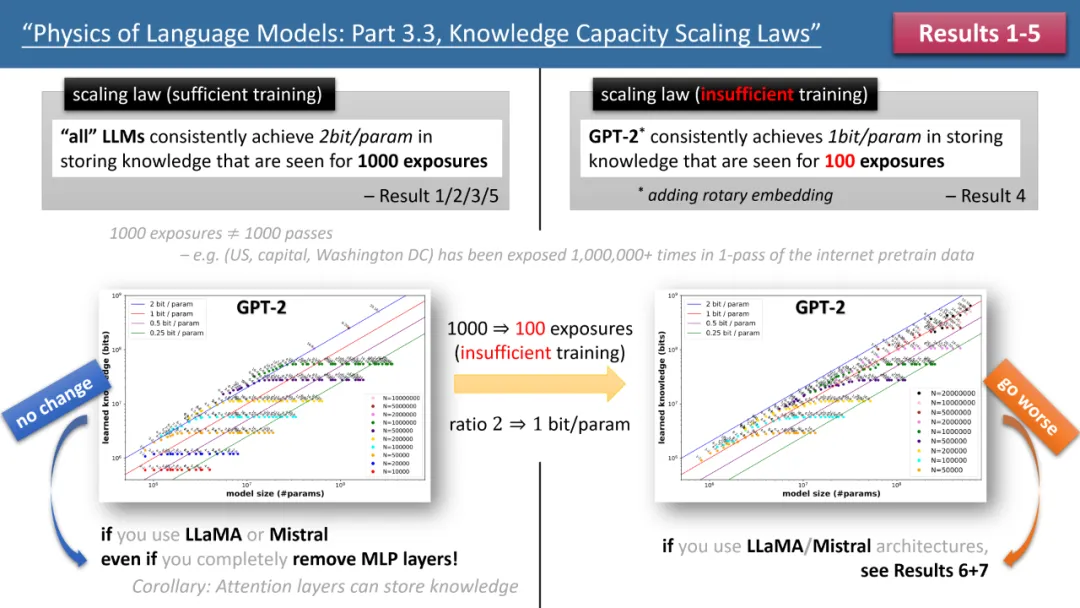 #左側の図は、十分なトレーニング時間が必要な場合のスケーリング則を示し、右側の図は、トレーニング時間が不十分な場合のスケーリング則を示します
#左側の図は、十分なトレーニング時間が必要な場合のスケーリング則を示し、右側の図は、トレーニング時間が不十分な場合のスケーリング則を示します
Top 図 1 は、著者が提案する最初の 5 つの法則を簡単にまとめたもので、左が「トレーニング時間が十分な場合」、右が「トレーニング時間が不十分な場合」の 2 つの状況に対応しています。一般的な知識 (中国の首都は北京であるなど) と、あまり新しい知識 (たとえば、清華大学の物理学科は 1926 年に設立されました) です。
トレーニング時間が十分であれば、GPT2 または LlaMA/Mistral のどのモデル アーキテクチャが使用されていても、モデルのストレージ効率が 2 ビット/パラメータに達する可能性があることを著者は発見しました。つまり、モデルごとの平均です。パラメータには 2 ビットの情報を保存できます。これはモデルの深さとは関係なく、モデルのサイズのみです。言い換えれば、7B モデルは、適切にトレーニングされていれば、140 億ビットの知識を保存できます。これは、ウィキペディアとすべての英語の教科書に記載されている人間の知識を合わせたものよりも多くなります。
さらに驚くべきことは、従来の理論では、変圧器モデルの知識は主に MLP 層に保存されているということですが、著者の研究はこの見解を否定しています。すべての MLP 層が削除されたとしても、 、モデルはまだ 2 ビット/パラメータのストレージ効率を達成できます。
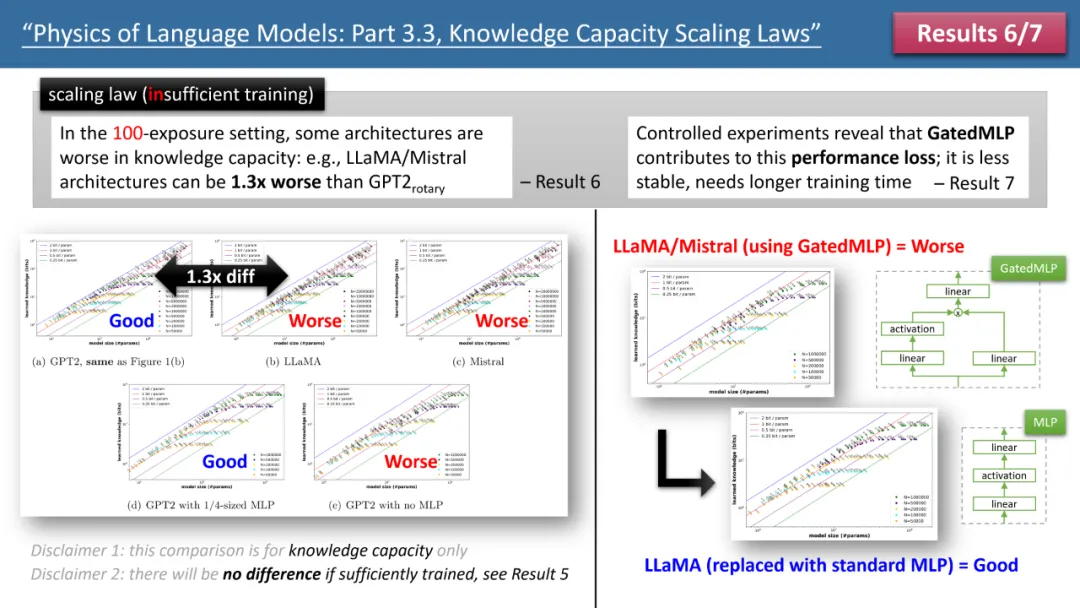
図 2: トレーニング時間が不十分な場合のスケーリング則
しかし、トレーニングを観察すると、時間が足りないと機種間の違いが顕著になってしまいます。上の図 2 に示すように、この場合、GPT2 モデルは LlaMA/Mistral よりも 30% 多くの知識を保存できます。これは、数年前のモデルがいくつかの点で今日のモデルを上回っていることを意味します。なぜこうなった?著者は、モデルと GPT2 の間の各差異を加算または減算して、LlaMA モデルのアーキテクチャを調整し、最終的に GatedMLP が 30% の損失の原因であることを発見しました。
強調しておきますが、GatedMLP はモデルの「最終的な」ストレージ レートに変化を引き起こしません。なぜなら、図 1 から、トレーニングが十分であれば変化しないことがわかるからです。ただし、GatedMLP では学習が不安定になるため、同じ知識でも学習時間が長くなり、学習セットにほとんど出現しない知識についてはモデルの保存効率が低下します。
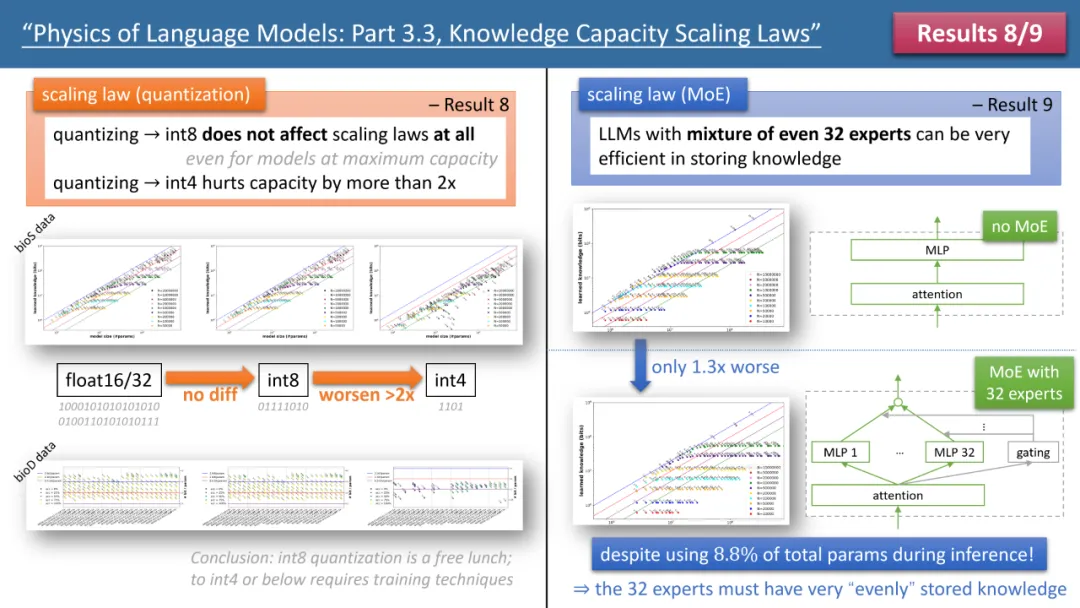
著者の法則 8法則 9 は、モデル スケーリング法則に対する量子化と MoE の影響を個別に研究し、その結論を上の図 3 に示します。 1 つの結果は、トレーニング済みモデルを float32/16 から int8 に圧縮しても、2 ビット/パラメーターのストレージ制限に達したモデルであっても、知識のストレージに影響を与えないことです。
これは、LLM が「情報理論の限界」の 1/4 に達する可能性があることを意味します。これは、int8 パラメーターはわずか 8 ビットですが、各パラメーターは平均して 2 ビットの知識を保存できるためです。著者は、これは普遍的な法則であり、知識表現の形式とは何の関係もない、と指摘する。
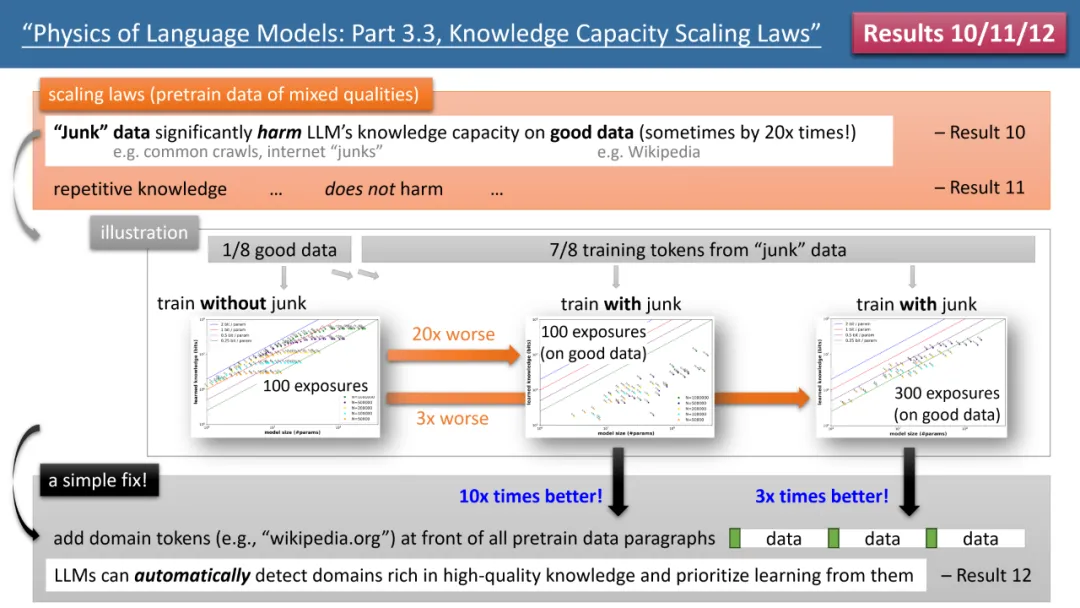
最も顕著な結果は、著者の法則 10 ~ 12 から得られます (図 4 を参照)。 (事前) トレーニング データの場合、1/8 は高品質の知識ベース (Baidu Encyclopedia など) から得られ、7/8 は低品質のデータ (一般的なクロールやフォーラムでの会話、さらには完全にランダムなゴミなど) から得られます。データ)。
では、
低品質のデータは、LLM による高品質の知識の吸収に影響を及ぼしますか?その結果は驚くべきもので、たとえ高品質データのトレーニング時間が一定であったとしても、低品質データの「存在自体」によって、モデルが高品質の知識を蓄積する量が 20 分の 1 に減少する可能性があります。高品質データの学習時間が 3 倍に延長されたとしても、知識の蓄えは 3 分の 1 に減少します。これは金を砂の中に投げ込むようなもので、高品質のデータが無駄にされています。
それを修正する方法はありますか?著者は、すべての (事前) トレーニング データに独自の Web サイトのドメイン名トークンを追加するだけの、シンプルだが非常に効果的な戦略を提案しました。たとえば、すべての Wikipedia データを wikipedia.org に追加します。このモデルでは、どの Web サイトに「ゴールド」ナレッジがあるかを特定するための事前知識は必要ありませんが、事前トレーニング プロセス中に、高品質のナレッジを持つWeb サイトを 自動的に検出し、 自動的に これを行うことができます。高品質のデータによりストレージ容量が解放されます。
著者は、検証するための簡単な実験を提案しました。高品質のデータが特別なトークンで追加された場合 (特別なトークンであれば何でもよく、モデルはそれがどのトークンであるかを知る必要はありません)事前に) を実行すると、モデルの知識記憶容量が即座に 10 倍に増加します。すごいと思いませんか?したがって、ドメイン名トークンを事前トレーニング データに追加することは、非常に重要なデータ準備操作です。#図 4: スケーリングの法則、モデルの欠陥、および事前トレーニング データに「一貫性のない知識の品質」がある場合のそれらの修復方法
結論
著者は、データを合成することによって、トレーニング プロセス中にモデルが獲得した知識の総量を計算する方法を「」に使用できると考えています。モデルのアーキテクチャ、トレーニング方法を評価し、「データ準備」は体系的で正確なスコアリング システムを提供します。これは従来のベンチマーク比較とはまったく異なり、より信頼性が高くなります。彼らは、これが将来の LLM の設計者がより多くの情報に基づいた意思決定を行うのに役立つことを期待しています。
以上がLlama アーキテクチャは GPT2 より劣っていますか?魔法のトークンで記憶力が10倍になる?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。