
ホームページ >テクノロジー周辺機器 >AI >北京大学の最も強力なオープンソース aiXcoder-7B コード モデル!実際の開発シナリオに重点を置き、企業のプライベート展開向けに設計
北京大学の最も強力なオープンソース aiXcoder-7B コード モデル!実際の開発シナリオに重点を置き、企業のプライベート展開向けに設計

- 王林転載
- 2024-04-09 18:10:021667ブラウズ
テクノロジー界の最新の動向から判断すると、AI コード生成の概念は最近非常に人気が高まっています。
しかし、皆さん、AI プログラミングの質問はより人目を引くものだと感じていますが、実際の企業開発シナリオとなると、それだけでは十分ではないと常に感じていますか?
この瞬間、地味な上級プレイヤーである aiXcoder が行動を起こし、大きな動きを放ちました:
これは新しいオープンソースの大規模コード モデルです---aiXcoder-7B 基本バージョン は、 エンタープライズ ソフトウェア開発シナリオで を展開するのに特に適した大規模なコード モデルです。
ちょっと待ってください。#70 億パラメータ「のみ」を持つ大規模なコード モデルは、どのような AI プログラミング レベルを示すことができますか?
まず、HumanEval、MBPP、MultiPL-E の 3 つの主流の評価セットでのパフォーマンスを見てみましょう。その平均スコアは、実際に 340 億のパラメーターを備えた Codellama を上回っています。
後者は Meta から来ており、オープンソース業界で最も先進的な大規模 AI プログラミング モデルである Llama2 に基づいていることを知っておく必要があります。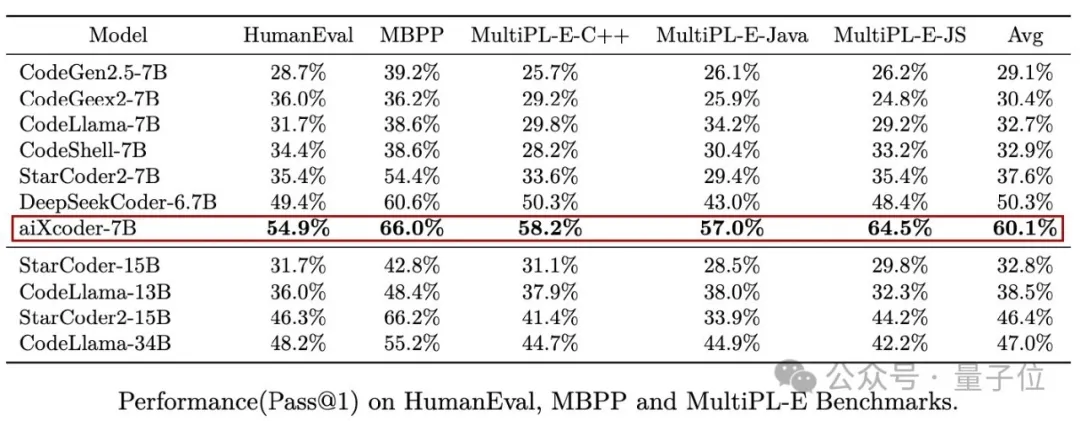
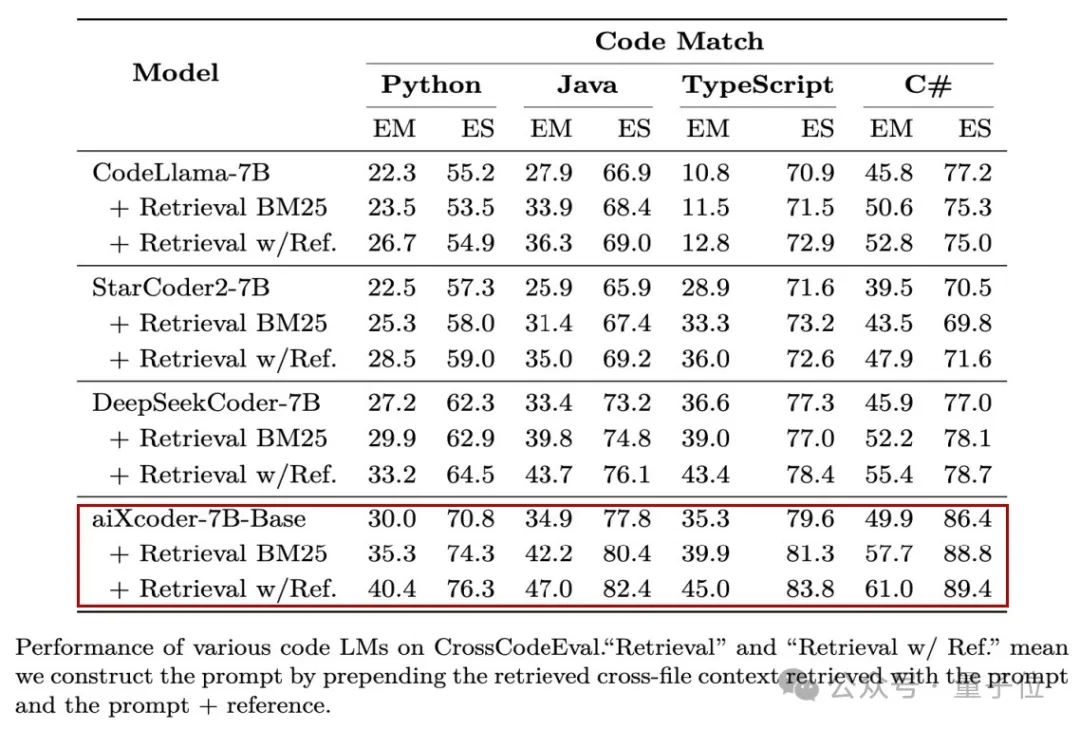
エンタープライズ レベルのソフトウェア プロジェクト 、 を対象としています。実際の開発シナリオで最も効果的です -コード 補完とファイル間を生成する機能がテストされており、両方とも "Long Bang Di" (No. 1) です。 これは、aiXcoder-7B が「仮想」を実行せず、企業の実際のビジネス シナリオを保持できることを意味します。
たとえば、実際の開発シナリオに近い評価セットである CrossCodeEval では、aiXcoder-7B が同レベルのモデルの中で最高の結果を一気に達成しました。
 数百億のパラメータを備えた最強のコード モデル
数百億のパラメータを備えた最強のコード モデル
最初に大規模なモデルを見てみましょう。
今回オープンソースとして公開されたのは、aiXcoder-7B Base バージョン
(対応する Instruct バージョンも後日リリース予定)で、最も驚くべき点は次のとおりです。 コード生成機能 SOTA に加えて、aiXcoder-7B は主流の評価でさまざまなアルゴリズムの質問に勝っただけでなく、より重要なことに、実際のエンタープライズ開発シナリオと一致する複数ファイルの複雑なコード シナリオにおいて、aiXcoder-7B はさらに優れたパフォーマンスを発揮しました。同じ大きさのパラメータ モデル。
現時点で AI プログラミング ツールの最も実用的な機能は、完全なメソッド ブロック、条件判断ブロック、ループ処理ブロック、例外キャッチ ブロック、その他の状況を直接生成することを含む、生成と完了であることを知っておく必要があります。 実際の開発シナリオでは、開発プロジェクト全体のさまざまな関連ファイルを理解し、それらを生成するために特に必要です。 テストの結果、単一ファイル コンテキストと組み合わせた aiXcoder-7B Base バージョンのコード補完機能は、StarCoder2、CodeLlama、およびその他のモデルを上回り、Python、JS、および Java 言語で最高の総合スコアを獲得していることが示されています。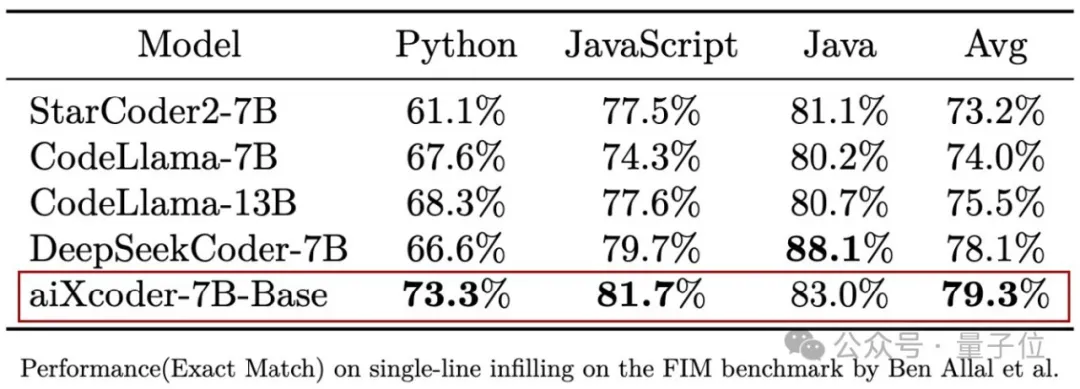 #これは、SantaCoder 評価セットの結果です。それだけではなく、aiXcoder チームはさらに大規模な評価コード生成完了データ セット
#これは、SantaCoder 評価セットの結果です。それだけではなく、aiXcoder チームはさらに大規模な評価コード生成完了データ セット
も提案しました。さらなる評価の後、その効果はより明らかです。 本日、評価セットもモデルとともに オープンソースになりましたので、ぜひチャレンジしてみてください~これは言及する価値があります。チームも特別であるということ 「イースターエッグ」が私たちに開かれました。つまり、aiXcoder-7B Base バージョンは、完了時にタスクを完了するために
より短いコードを使用する傾向があります。それは自然な「シンプルさ、美しさ」を持っています。 利点は自明です。プログラマーにとっては理解しやすく、バグは検出しやすくなります。
プライベート展開とパーソナライズされたカスタマイズが簡単 なぜこれほど優れたコード モデルを備えたオープンソースである必要があるのでしょうか?
aiXcoder チームは、より多くの開発者の作業負担を軽減することが彼らの願いであると述べました。 今回、7Bの大規模なプロジェクトレベルのコードモデルをオープンソース化する理由は「エンタープライズ開発者が便利に使えるようにするため」です。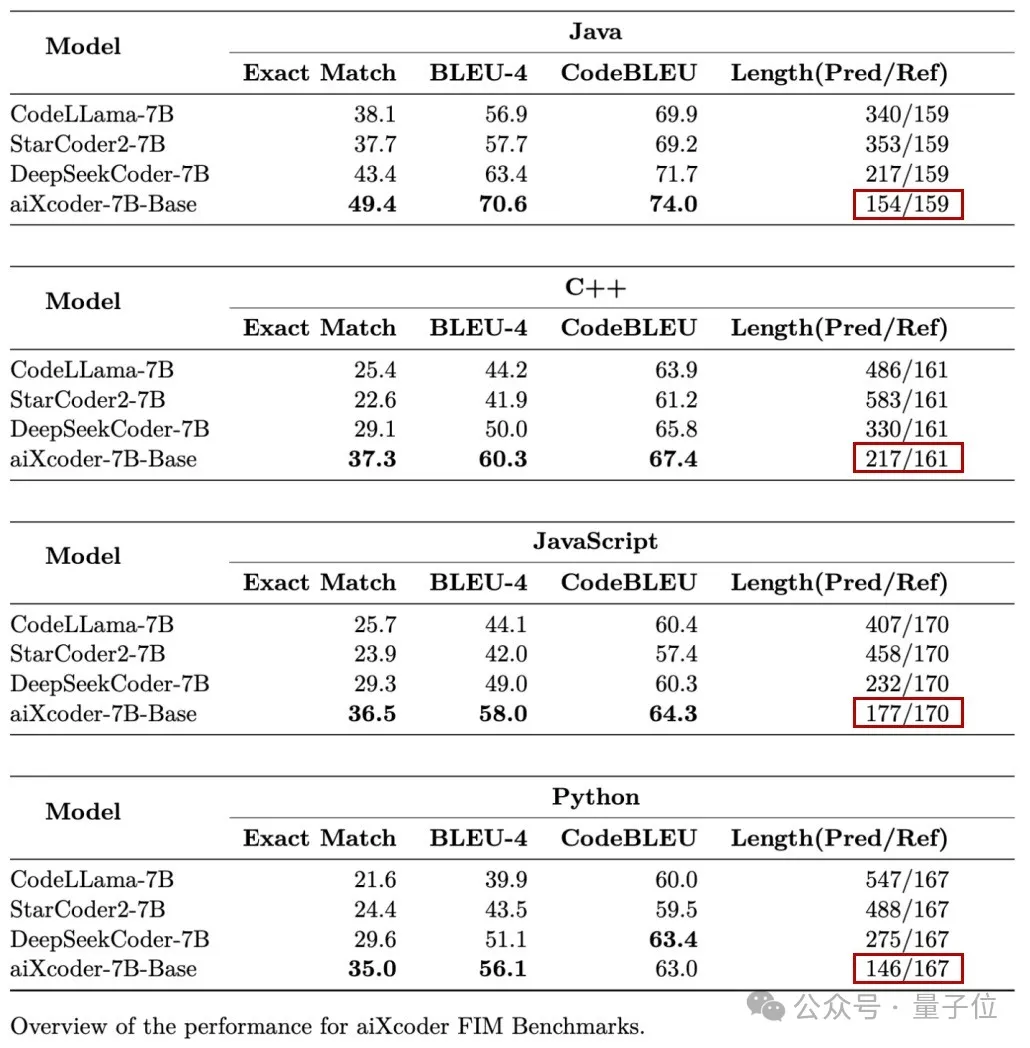 その特徴を 3 つの「簡単」で要約すると、次のようになります。
その特徴を 3 つの「簡単」で要約すると、次のようになります。
コード データは企業の中核となる知的財産権です。したがって、民営化された展開と学習は避けられず、通常、企業の展開リソースは限られています。
aiXcoder-7B 基本バージョンのパラメーター サイズはわずか 7B で、非常に軽量で導入が簡単で、低コストと優れたパフォーマンスという利点があります。
2 番目のポイントはカスタマイズが簡単です。
多くの企業は独自のソフトウェア開発フレームワークと API ライブラリを持っており、それに関連するビジネス ロジックとコード アーキテクチャの仕様は地域の状況に合わせてカスタマイズされており、非常にカスタマイズされています。同時に、これらのコンテンツは非公開です。
大規模モデルは、これらのエンタープライズ コード資産を学習する必要があり、効果的なパーソナライズされたトレーニングを通じて、企業で実際に使用できるようになります。
aiXcoder-7B Base バージョンには、このような簡単なカスタマイズ機能があります。
さらに、組み合わせも簡単です。
aiXcoder チームは、将来エンタープライズ サービスを提供する場合、複数の 7B モデルが MoE アーキテクチャを形成し、一連のソリューションに結合してエンタープライズ カスタマイズ サービスを完成できることを明らかにしました。
さまざまな企業は、独自のニーズを満たす MoE バージョン コードの大規模モデル ソリューションを入手できます。
aiXcoder-7B Base バージョンはオープンソース路線を採用しており、B サイド市場に焦点を当て、将来的にはエンタープライズ バージョンをリリースする予定であることがわかりました。
このようにして、aiXcoder はエンタープライズ レベルのユーザーに正確かつ効率的かつ継続的なソフトウェア開発サービスを提供し続け、プロジェクトの開発効率とコード品質を継続的に向上させるのに役立ちます。
たとえば、デジタル インテリジェンス変革が進む業界の大手証券会社は、aiXcoder の大規模モデル ソリューションを採用して、コードの大規模モデルをローカル環境に民営化して展開し、モデルの柔軟な調整方法を採用しました。インテリジェント開発システムが、それを使用するチームの規模に対応できるようにします。
この導入方法は、それをサポートするのに十分なコンピューティング能力を確保するだけでなく、高いハードウェアしきい値によって引き起こされる課題を回避するだけでなく、企業の日常的なコーディングのニーズにも応えることができます。
既存の実装データのフィードバックによると、パーソナライズされたトレーニングと企業独自のドメイン知識を組み合わせた後、ビジネス ロジック コードでのコード生成の割合が以前と比べて 2 倍に増加しました。 結果を読んだ後、モデルの実際の効果は何でしょうか?次に、雰囲気を味わうためのデモをいくつか紹介します。
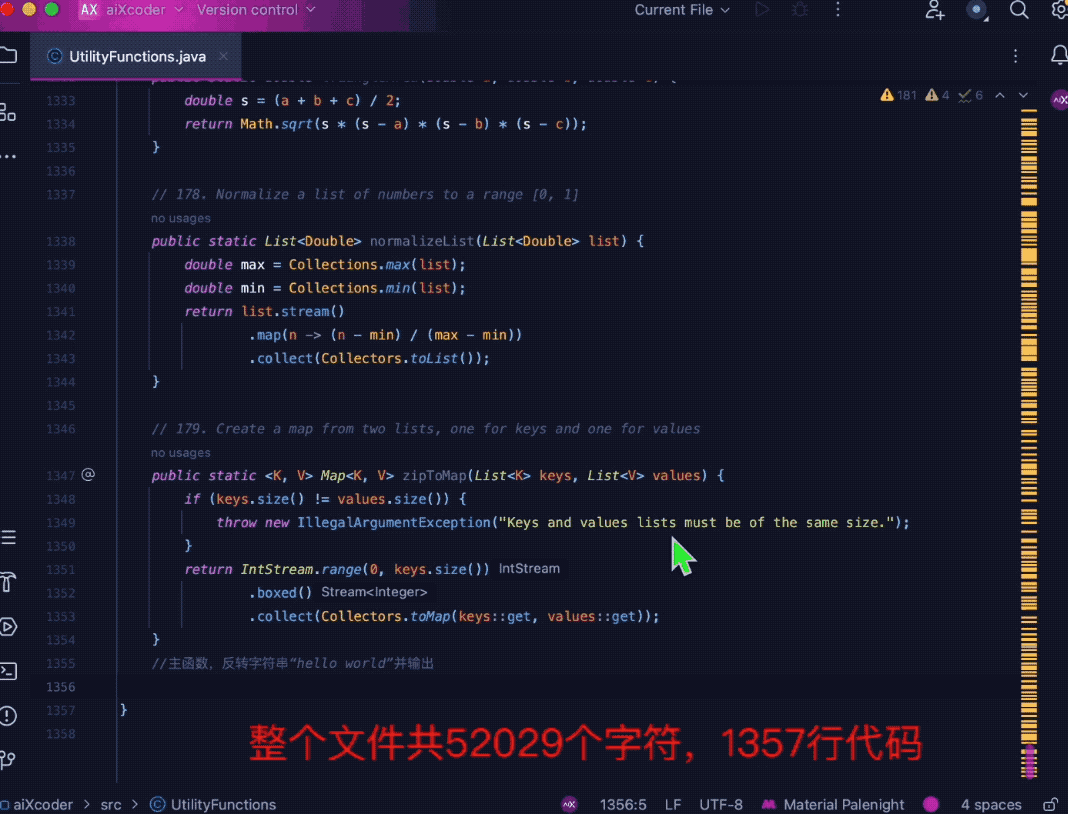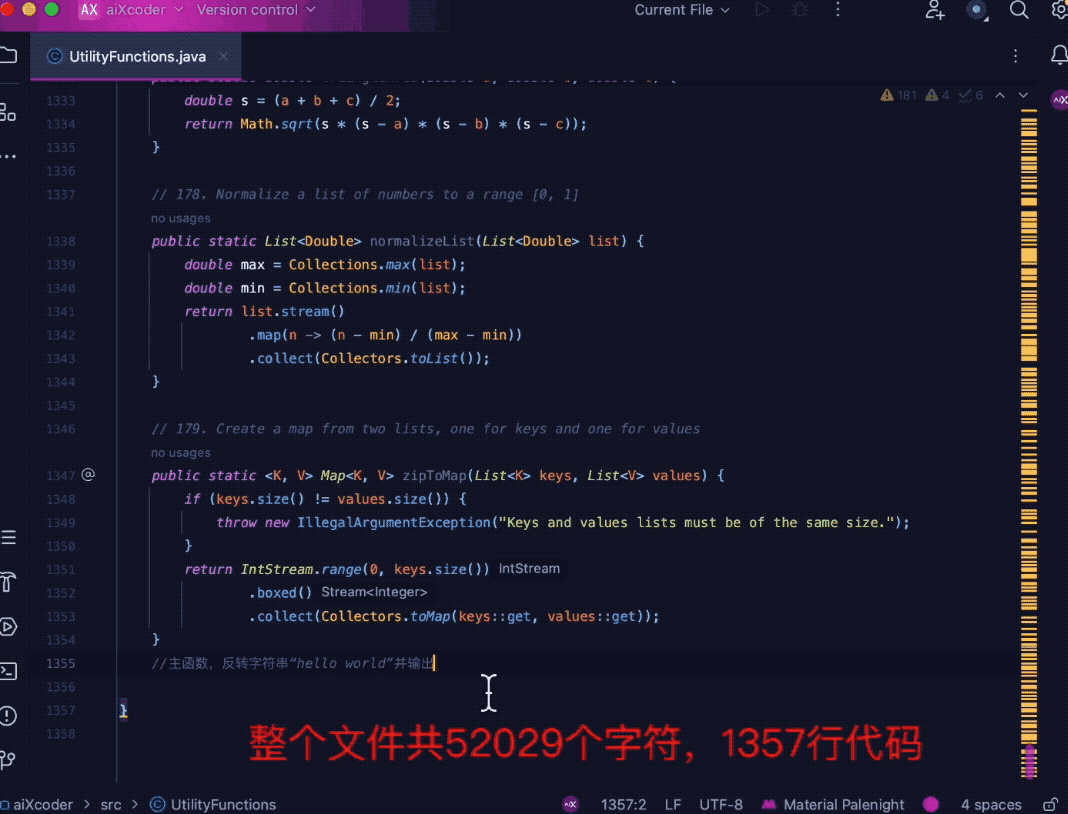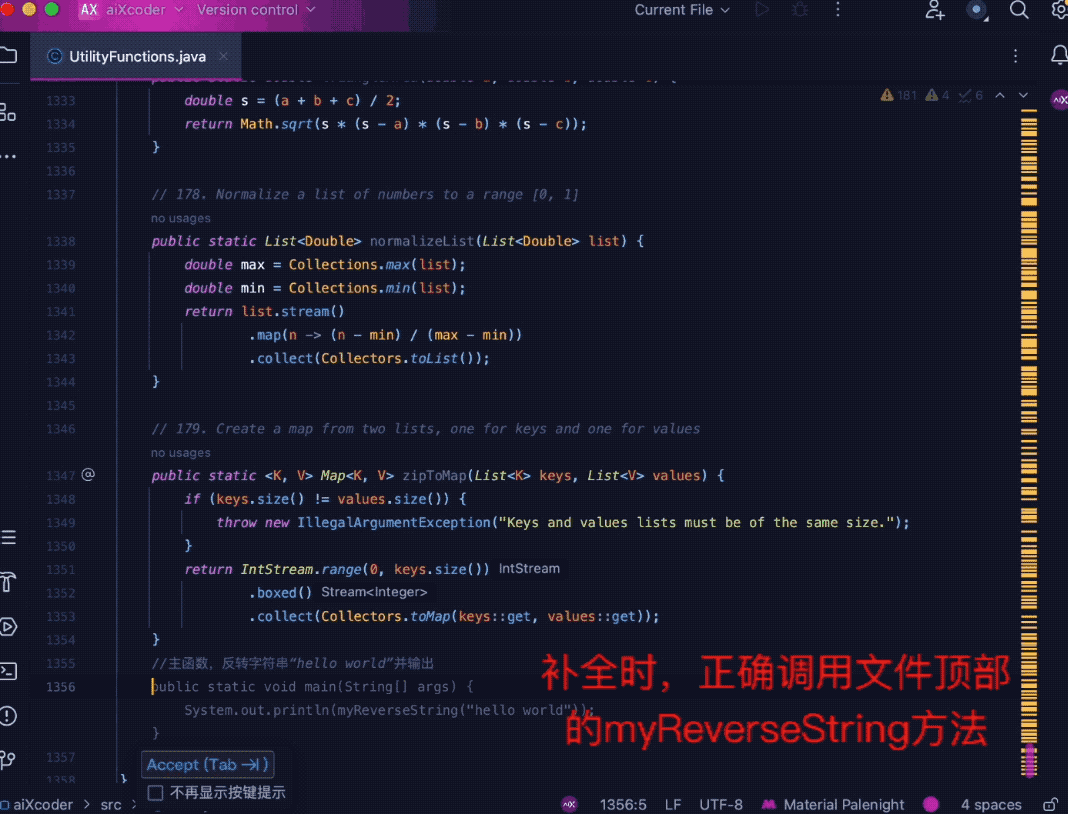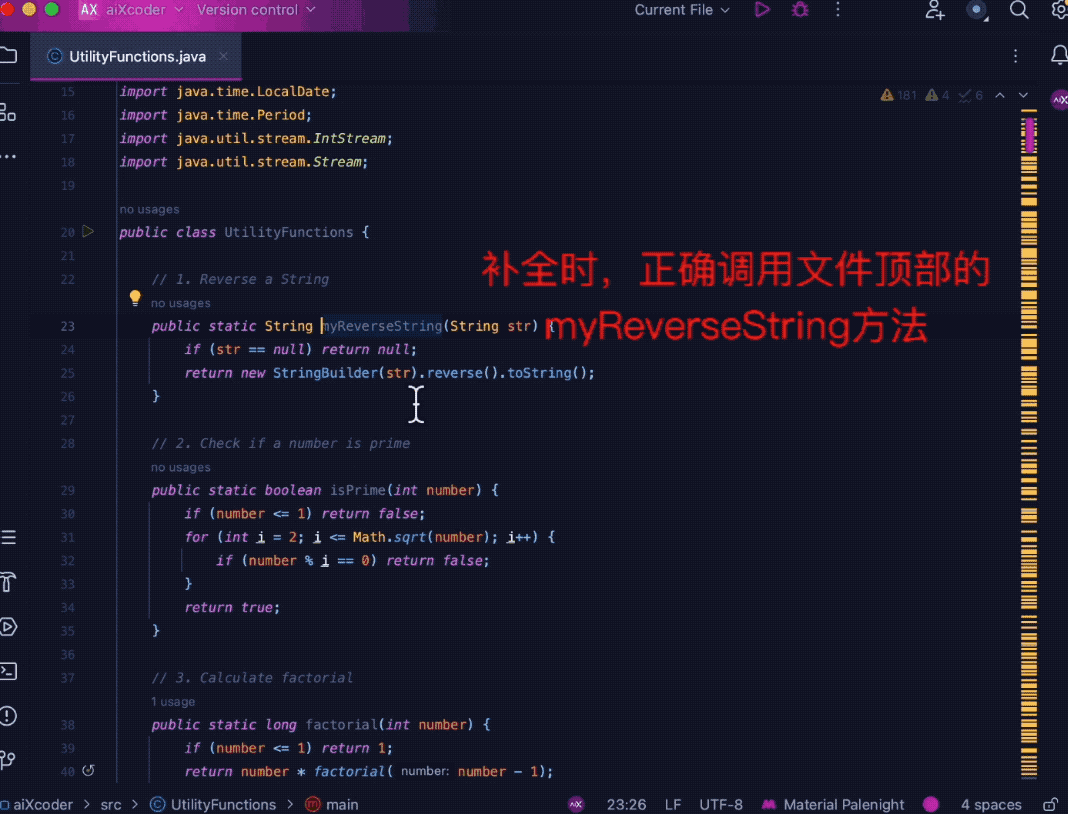
まず第一に、aiXcoder-7B Base バージョンは、ますます複雑なコード コンテキスト情報を理解し、コードの生成と補完を実行できます。モデルの事前トレーニングでサポートされるコンテキスト長は 32k で、推論フェーズの拡張は 32k に達します。 256k。
下の図に示すように、複数のツール関数を使用して 1,500 行を超えるコードをまとめ、ファイルの最後にコメントを付けてモデルにアクセスすると、関連する関数を正確に識別できます。ファイルの先頭に、関数情報の補完に関連するメソッドを組み合わせます。
 第 2 に、エンタープライズ開発シナリオでは、より重要なのは、複数のコード ファイルから必要なものを自動的に特定して抽出できるクロスファイル分析の機能です。
第 2 に、エンタープライズ開発シナリオでは、より重要なのは、複数のコード ファイルから必要なものを自動的に特定して抽出できるクロスファイル分析の機能です。
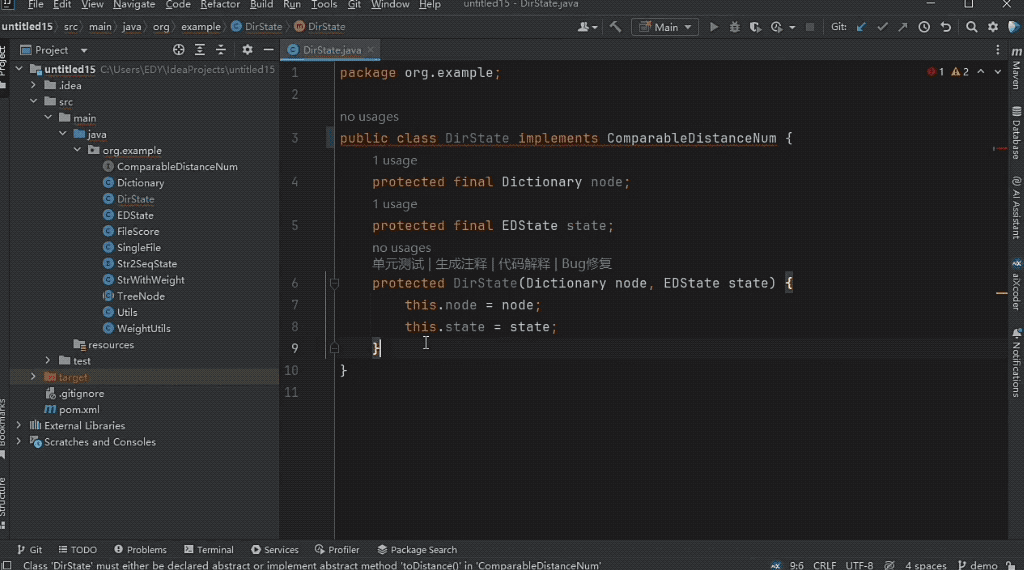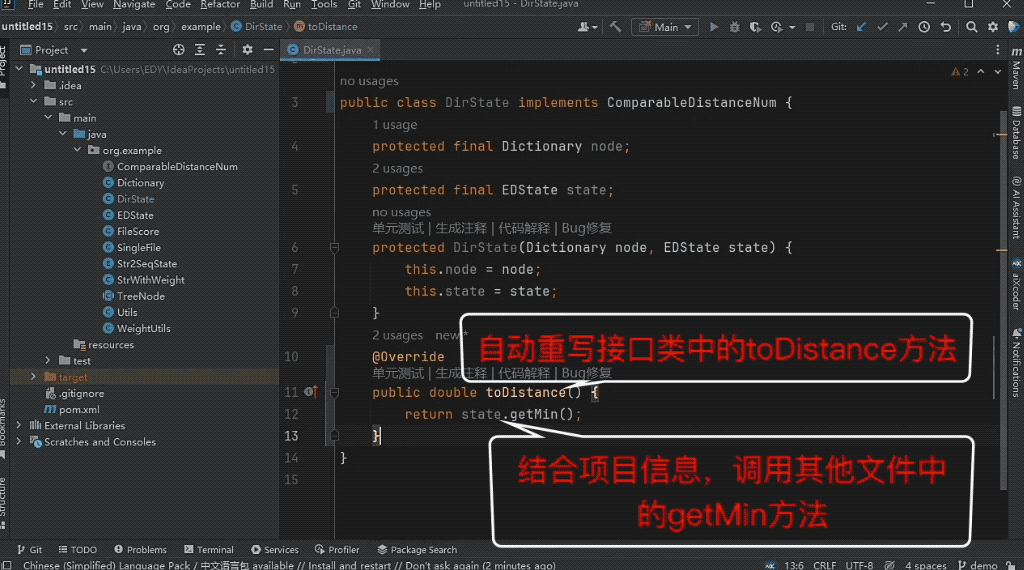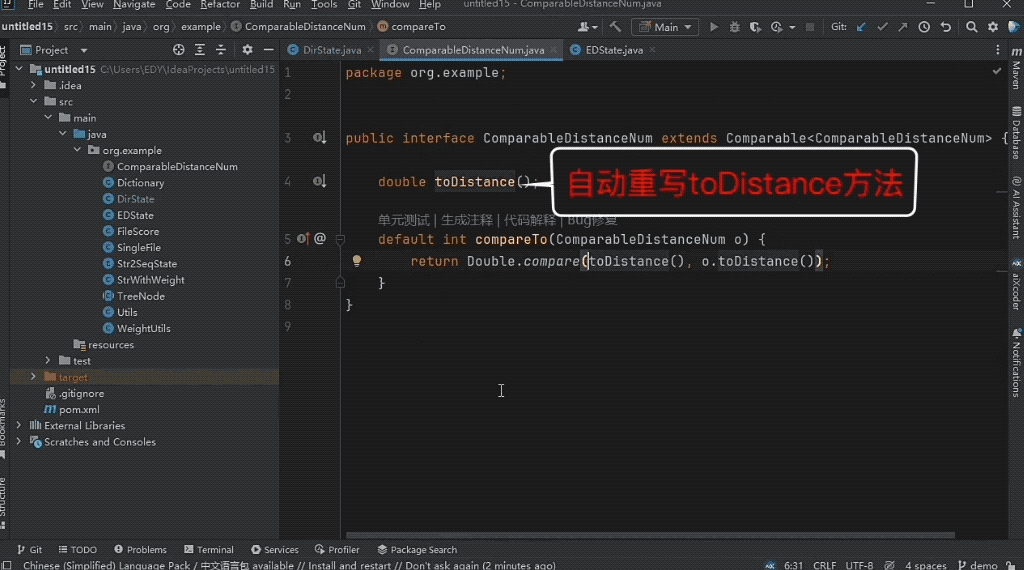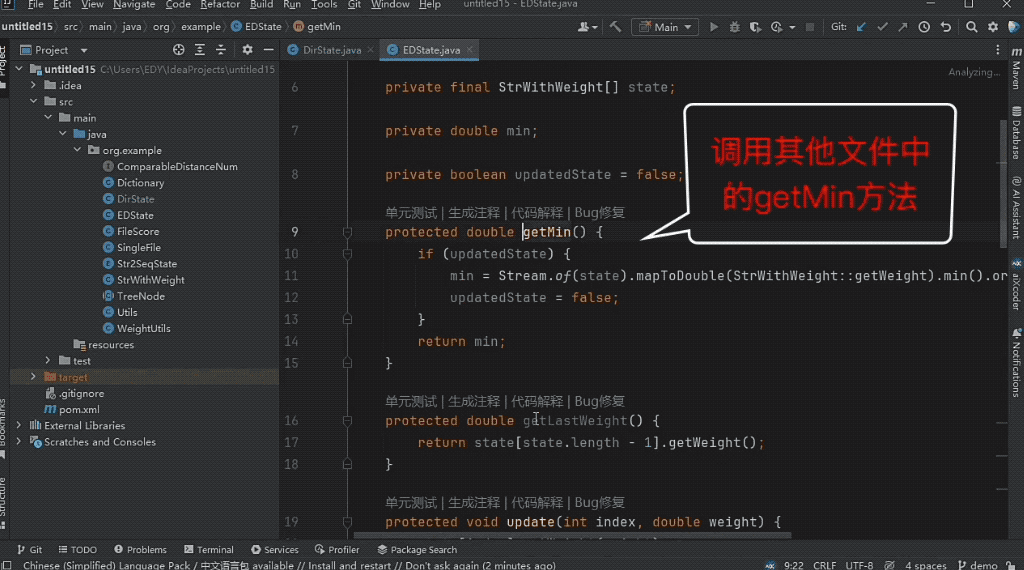
下の図に示すように、編集距離検索を実装するにはツリー構造に動的プログラミングを適用し、モデルがツリー構造上のディレクトリ ノードの動的プログラミング状態クラスを完成させる必要があります。
モデルは、編集距離の計算と別のファイルのローリング配列内の最小値の計算の間の関係を正確に識別するため、2 つの非現行ファイルを結合することで正しい予測結果が得られます。
 上記はまだ完了していません。aiXcoder-7B Base バージョンの完成度はまだかなり
上記はまだ完了していません。aiXcoder-7B Base バージョンの完成度はまだかなり
intelligent です。 たとえば、ユーザーの導入状況が調整されると、現在の導入状況に応じて完了の長さを自動的に調整します。
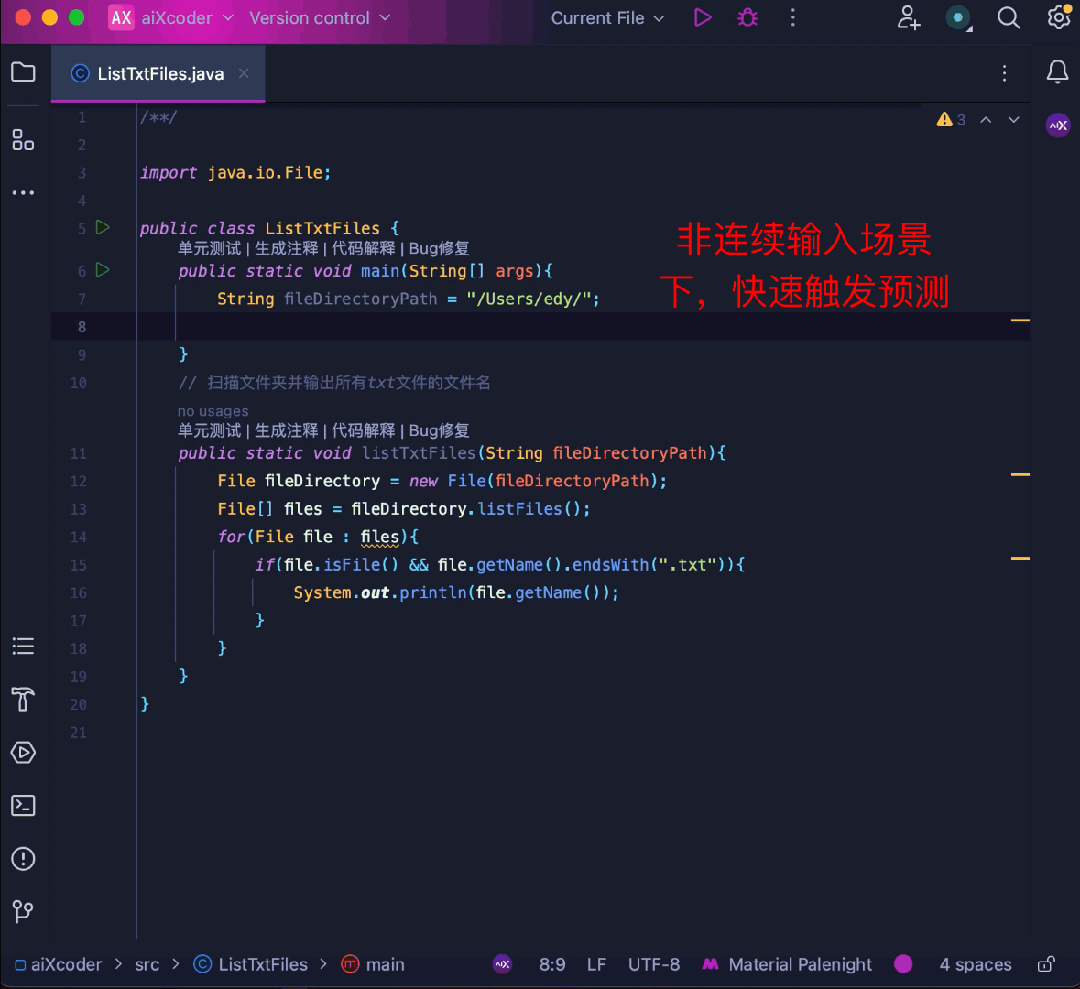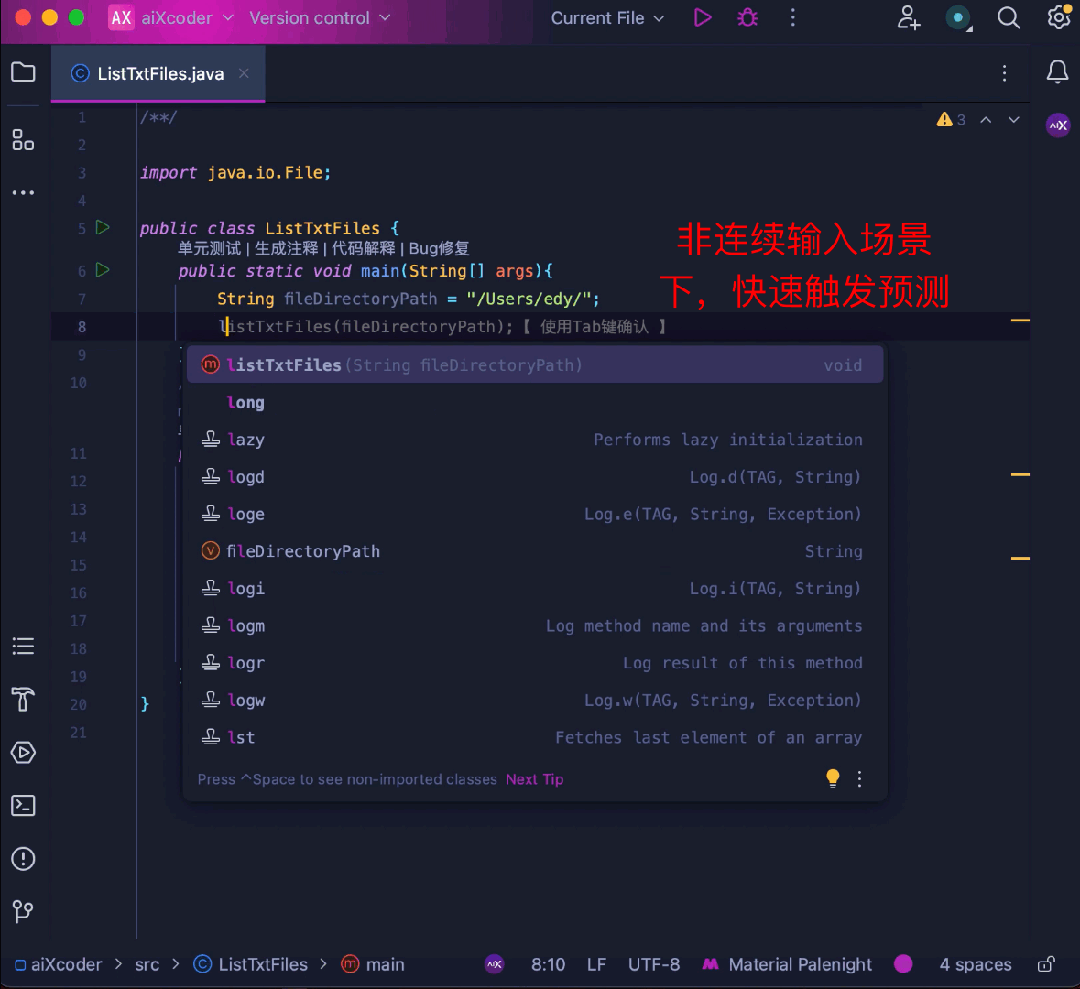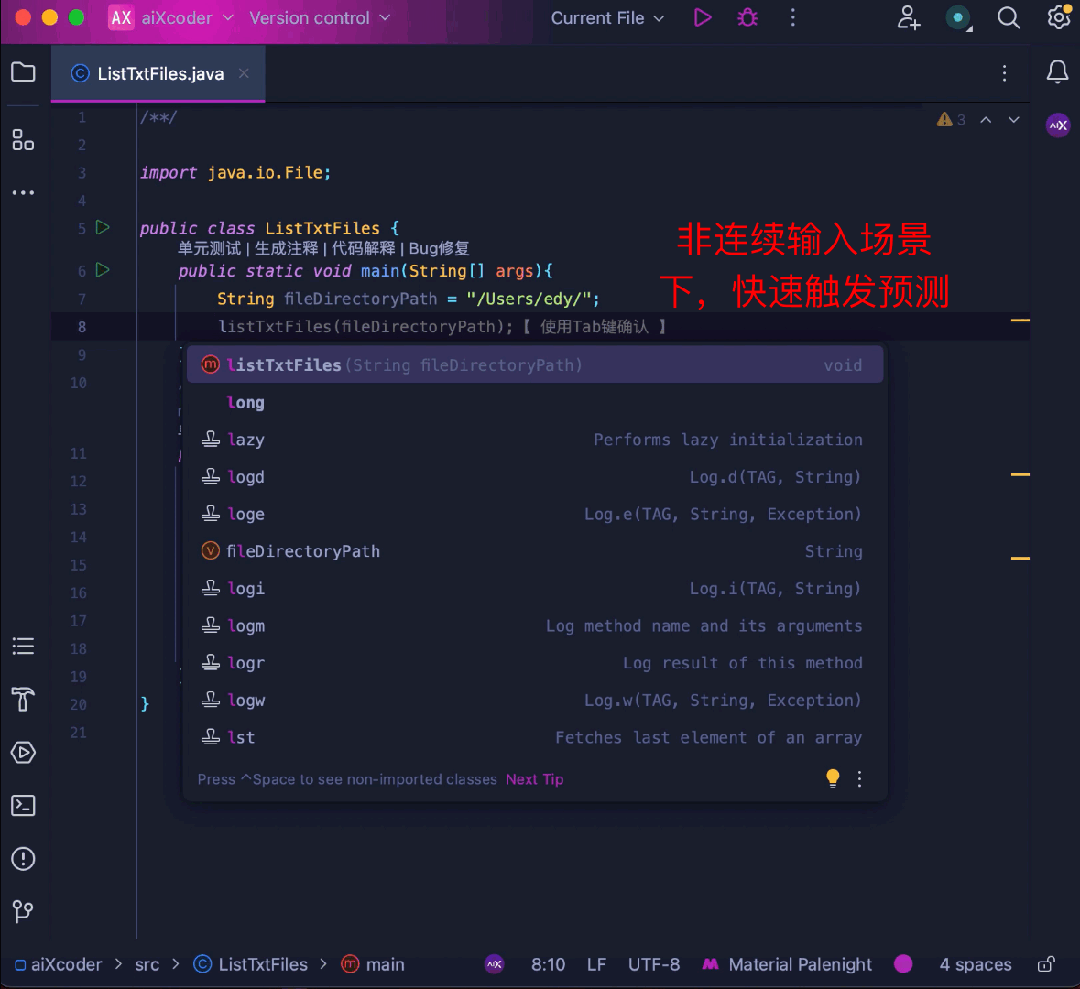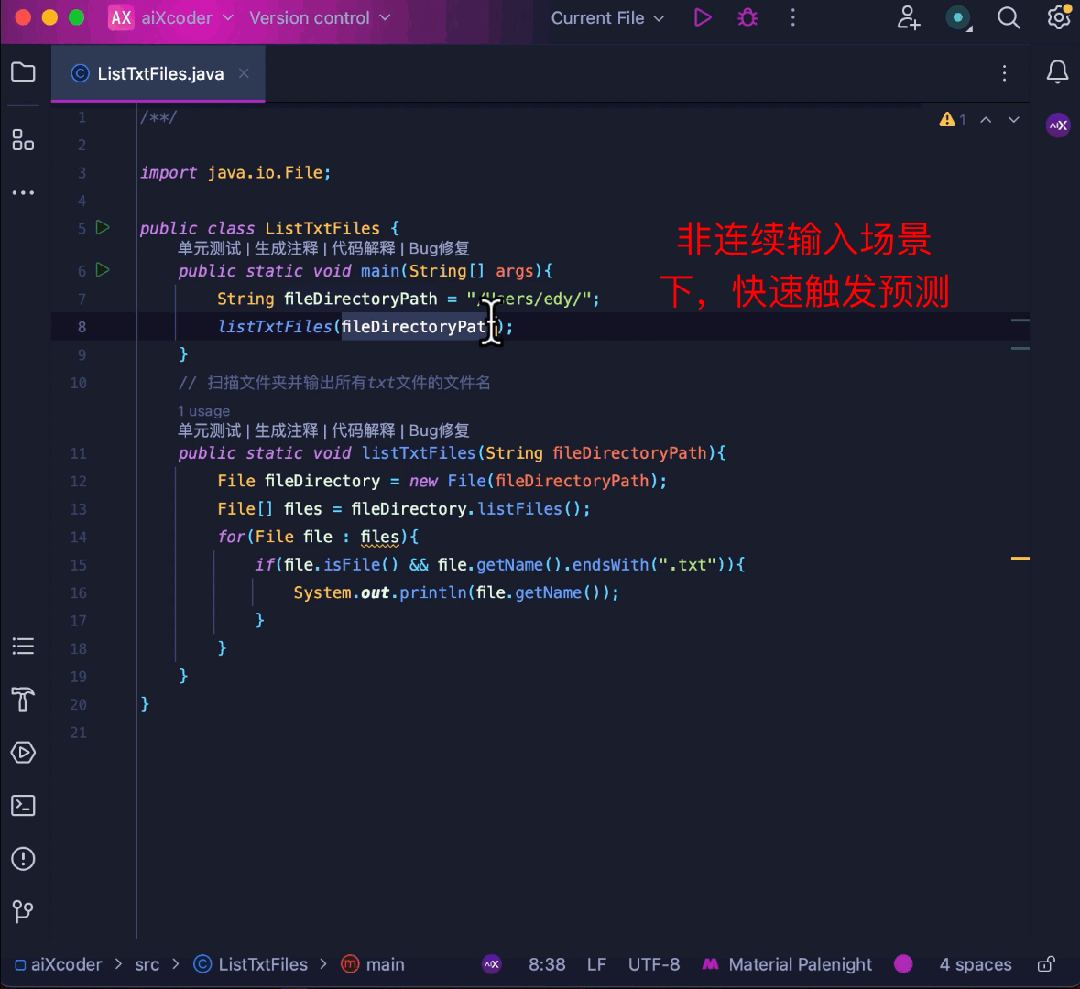
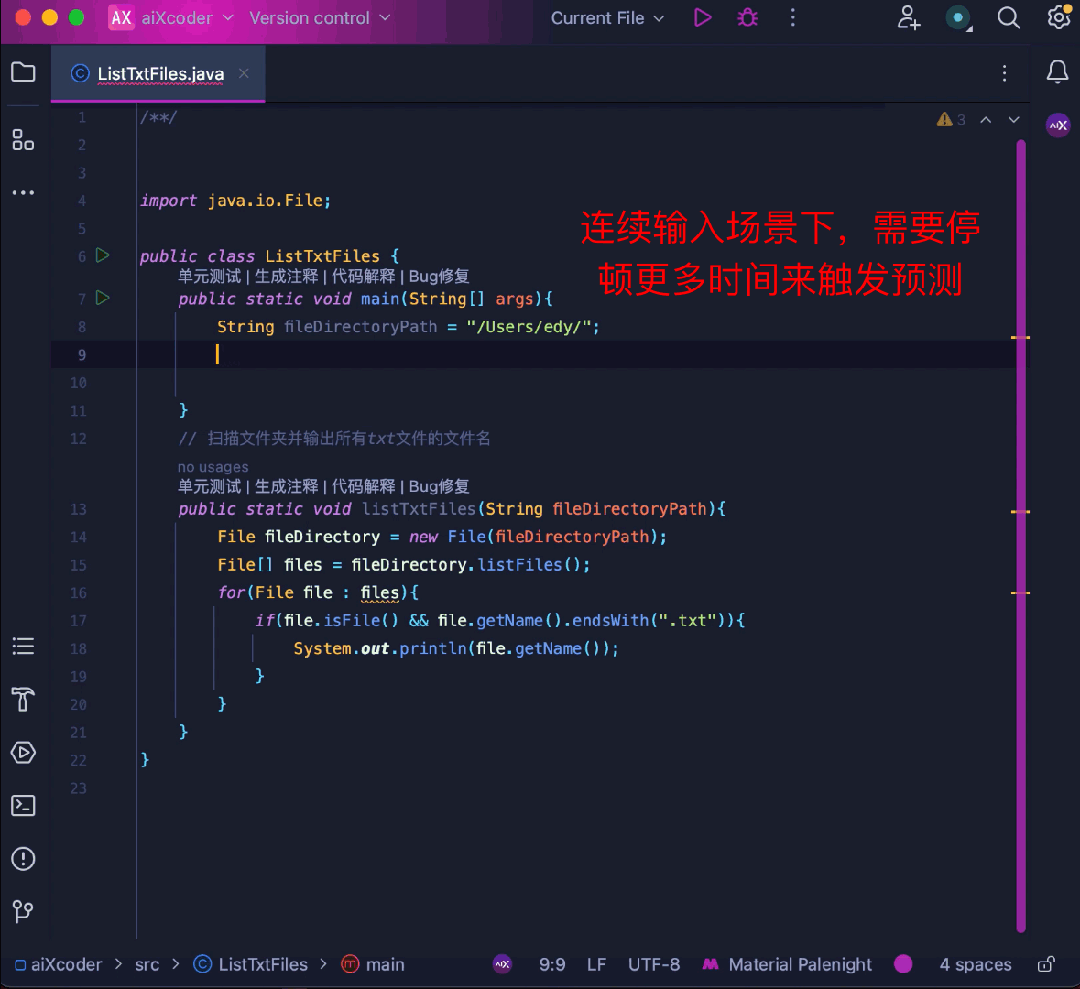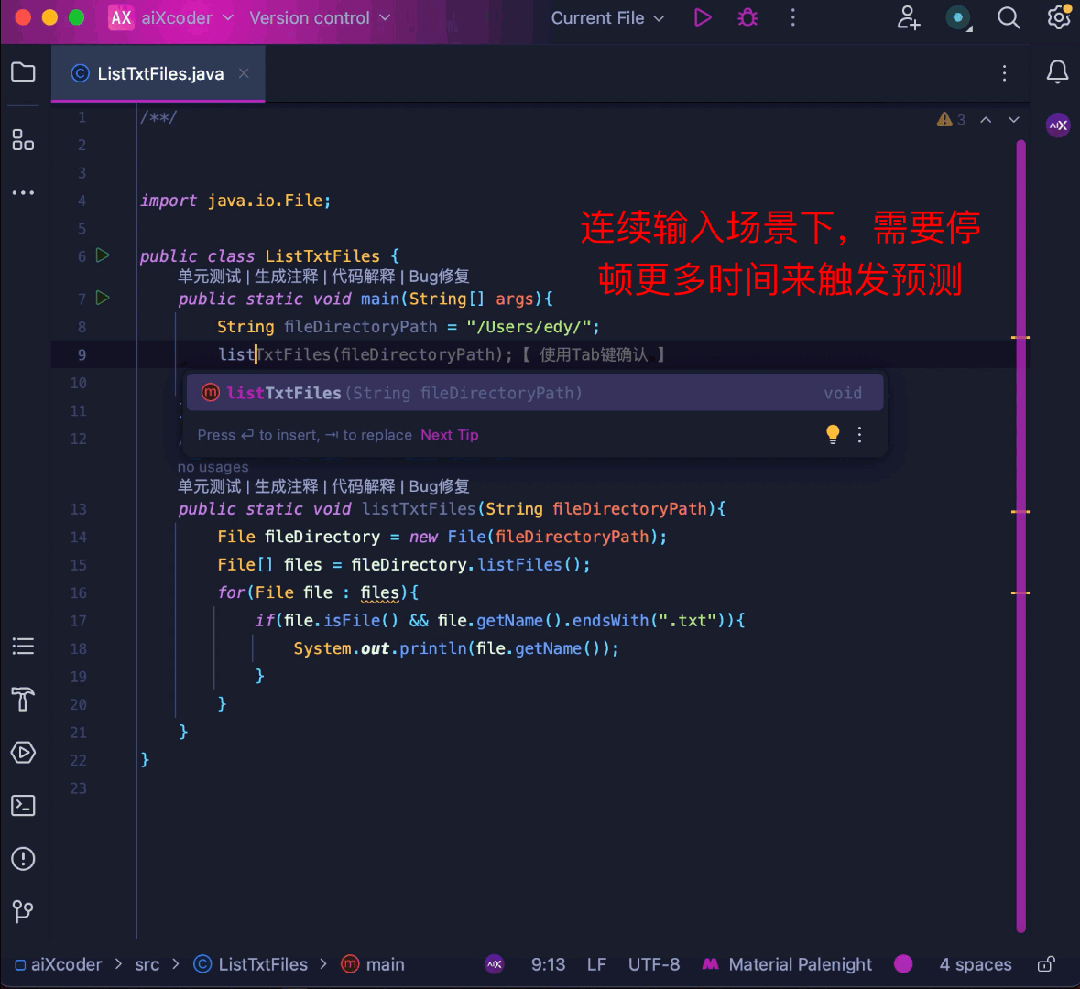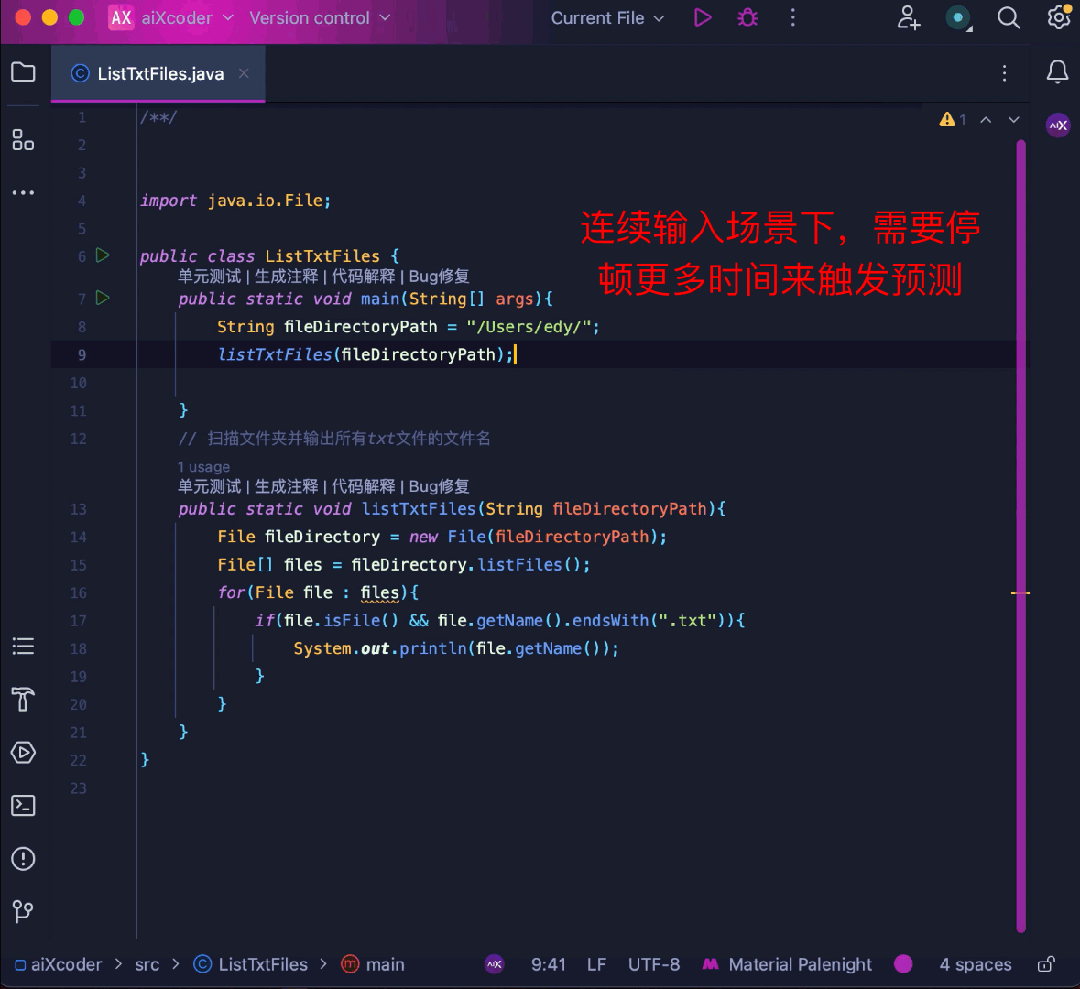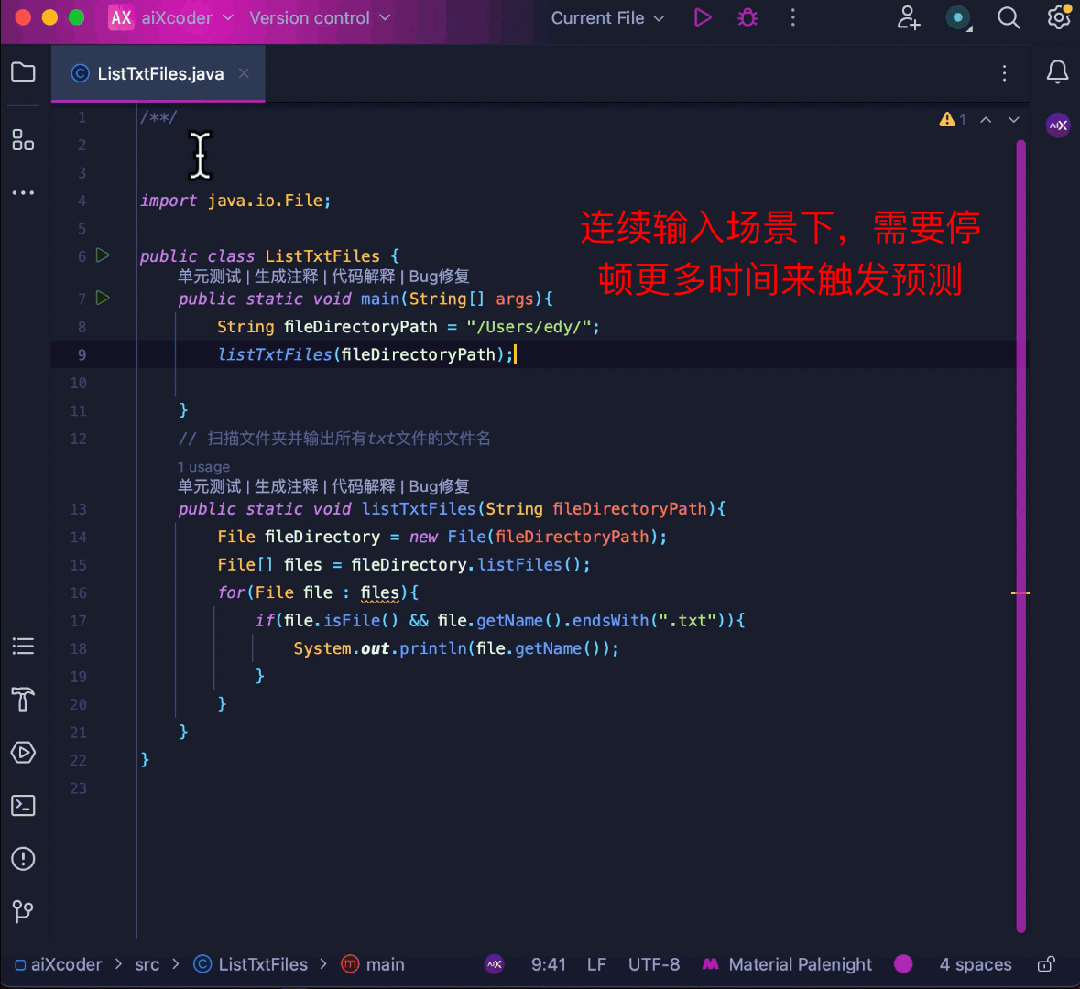
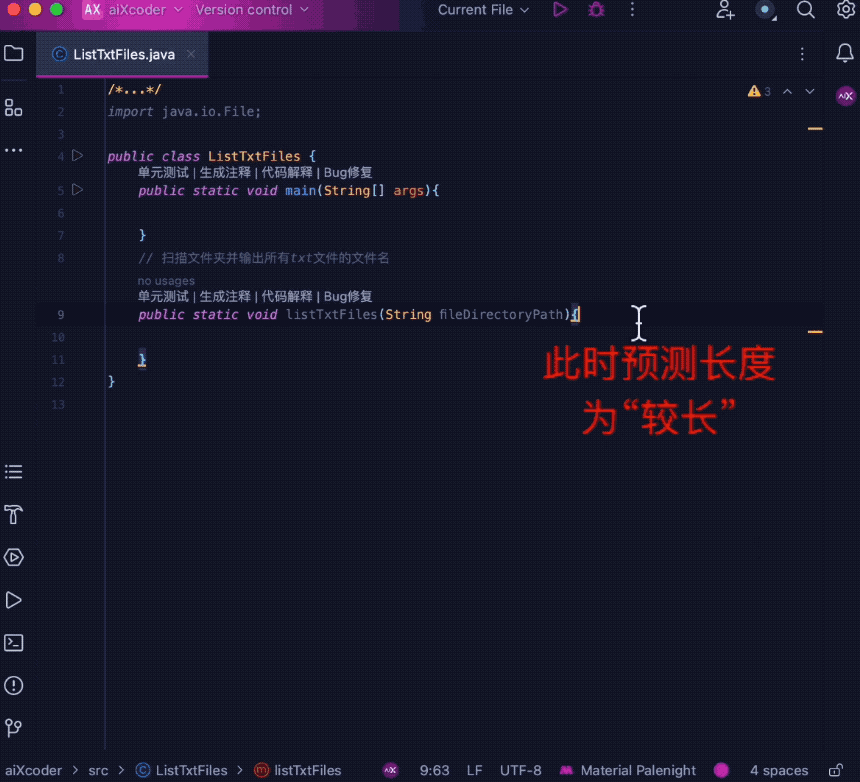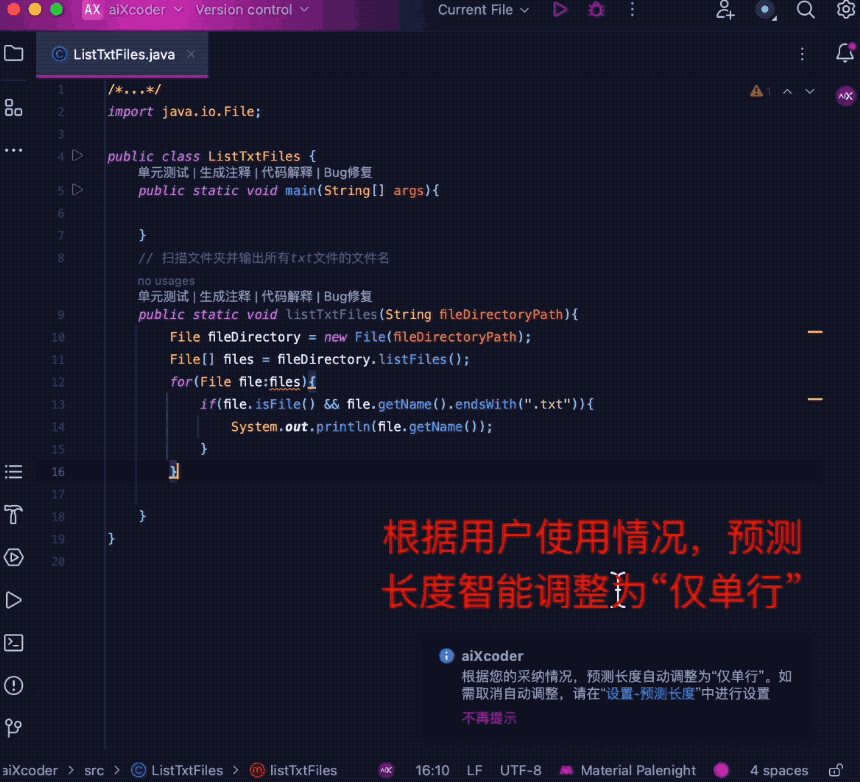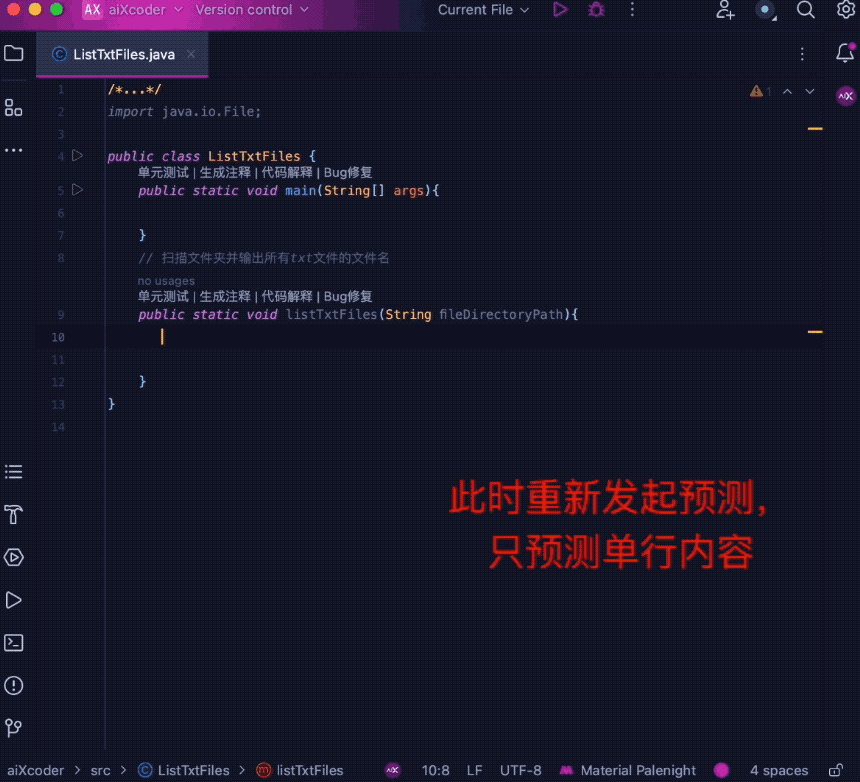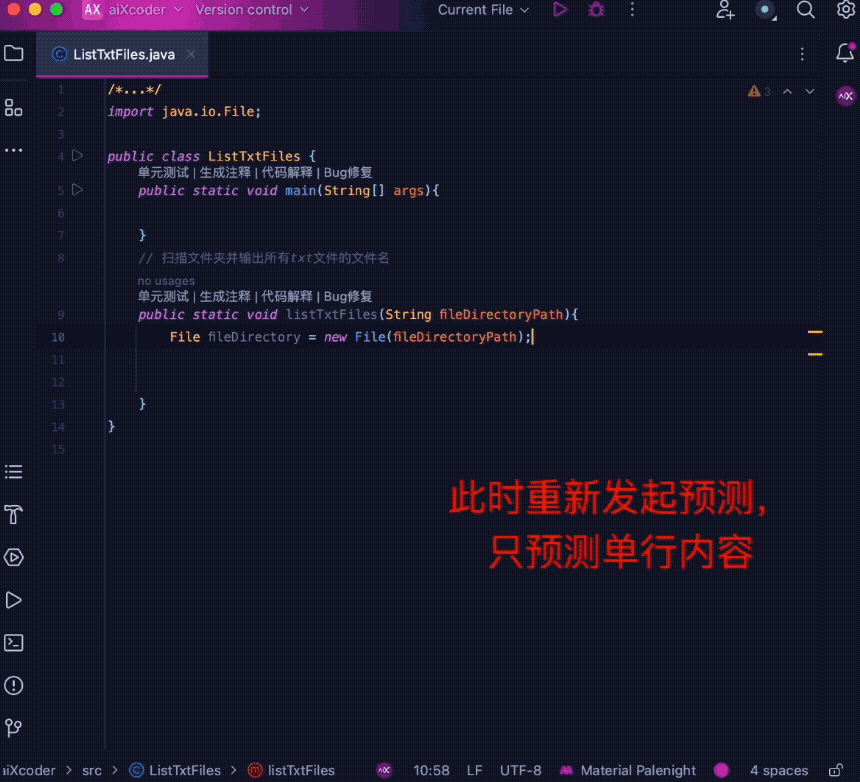 同時に、コード補完のエキスパートとして、ユーザー入力の流暢さ
同時に、コード補完のエキスパートとして、ユーザー入力の流暢さ
完了によって関数が勝手にトリガーされ、作業ステータスが中断されることはありません。
 言わざるを得ません。とても良い香りがします。
言わざるを得ません。とても良い香りがします。
大多数のプログラマーが本当に必要としているのは、
一般的なコードを理解するだけでなく、「当社の」コードも理解できる aiXcoder のような AI プログラミング ツールです。では、このような現実的なモデルはどのようにして作成されるのでしょうか?
チームによると、このモデルは完全に自己開発されています。最初はトレーニング データです
:合計 1.2T ユニーク##が含まれています# 7B パラメーター レベルのトークン モデルでは、トレーニング データの量が非常に多くなります。
チームは、「量の勝利」だけでなく、このデータで「質の勝利」も達成しました: 彼らは、数十の主流言語の構文分析とフィルタリングに多くの時間を費やし、静的分析により 163 個のバグと 197 個のバグを除去しました。 。
2 つ目は、対象を絞ったトレーニング方法です。チームは、モデルの効果を完全に保証するために、実際の環境でプロジェクト レベルのコードに対してコード構造化されたセマンティック トレーニングを特別に実施します。
最後に、トレーニング プロセス では、複数のファイルを処理する問題が最初から十分に考慮され、クラスタリング、コード呼び出しグラフなどを組み合わせることによって複数のファイル間の相互注意が構築されました。 。 関係。
最終的に、より実際の開発シナリオに適した aiXcoder-7B Base バージョンが誕生しました。 aiXcoder の背後にあるチーム このモデルの背後にある関係者を調べた結果、その起源は単純ではないことがわかりました。まず第一に、aiXcoder チームです。は北京出身で、大学ソフトウェア工学研究所が支援しており、2013 年からコード生成に取り組んでいます。最も初期の国際的な深層学習ベースのコード生成論文は彼らからのものです;
2 番目に、過去 10 年間で、チームは NeurIPS、ACL、IJCAI、ICSE、FSE、ASE などのトップ会議で 100 以上の関連論文を発表してきました。彼の論文の多くは国際的な学者によって「最初の成果」とみなされており、彼は複数の ACM Outstanding Paper Award を受賞しています。 体力や強さが必要であり、実績や成果も必要であると言えます。
2017 年に、aiXcoder のオリジナル プロトタイプ
aiXcoder1.0がリリースされ、自動コード補完と検索機能が提供されました。 2021 年 4 月、チームは、コード補完と自然言語レコメンデーションをサポートする、完全に独立した知的財産権を持つ 10 億レベルのパラメーター コード大規模モデルである
aiXcoder L バージョンをリリースしました。また、国内初の「大型モデル」によるインテリジェントプログラミング商品化となります。その後、チームは懸命の努力を続け、2022 年 6 月に、メソッド レベルのコード生成をサポートする国内初の数百億レベルのパラメーター モデル aiXcoder XL バージョン
をリリースしました。完全に独立した知的財産権も持っています。2023 年 7 月、aiXcoder チームは、自動コード補完、自動コード生成、コード欠陥の検出と修復、自動ユニットなどの機能を備えた エンタープライズへの適応に焦点を当てた aiXcoder Europa
を立ち上げました。テスト生成です。aiXcoder Europa は、企業のデータ セキュリティとコンピューティング能力の要件に基づいて、民営化された展開とパーソナライズされたトレーニング サービスを企業に提供し、大規模なコード モデルのアプリケーション コストを効果的に削減し、研究開発の効率を向上させることができると理解されています。
現在に至るまで、aiXcoder-7B Base バージョンが誕生しました。 科学技術の輝く銀河系では、あらゆる技術的進歩は新しい星の誕生のようなものであり、未来の無限の可能性を照らします。 大規模なコード モデルの機能が向上するにつれ、複雑なプログラミング問題を解決する際のその優れたパフォーマンスは、ソフトウェア開発の効率と品質の向上に重要な役割を果たすだけでなく、プログラミングの波を促進する役割も果たします。重要な役割を果たすことで、プログラマーの革新的な可能性も刺激され、探索と作成により多くのエネルギーを注ぐことができます。 言い換えれば、この最先端のコード モデルである aiXcoder-7B は、ソフトウェア開発自動化のプロセスを加速するだけでなく、テクノロジー業界の生態系を再構築し、将来の開発トレンドをリードします:
##ソフトウェア開発の自動化を加速します。
これは業界の一般的な傾向であるだけでなく、開発において避けられない選択でもあります。 幸いなことに、私たちはこの転換点の前に立ち、このトレンドの台頭と実現を目の当たりにしています。
aiXcoder オープン ソース リンク
:https://github.com/aixcoder-plugin/aiXcoder-7Bhttps:// gitee .com/aixcoder-model/aixcoder-7bhttps://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
以上が北京大学の最も強力なオープンソース aiXcoder-7B コード モデル!実際の開発シナリオに重点を置き、企業のプライベート展開向けに設計の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。