



以前に書いたもの&著者の個人的な理解
このディスカッション ペーパーで焦点を当てている主な問題は、自動運転のプロセスにおける 3D ターゲット検出技術の応用です。環境ビジョンカメラ技術の開発により、3D オブジェクト検出のための高解像度のセマンティック情報が提供されますが、この方法は、深度情報を正確にキャプチャできないことや、悪天候や低照度条件でのパフォーマンスの低下などの問題によって制限されます。この問題に対応して、議論ではサラウンドビューカメラと経済的なミリ波レーダーセンサーを組み合わせた新しいマルチモード3D目標検出方法RCBEVDetが提案されました。この方法は、複数のセンサーからの情報を総合的に使用することで、より豊富なセマンティック情報を提供し、悪天候や低照度条件でのパフォーマンスの低下などの問題の解決策を提供します。この問題に対応して、議論ではサラウンドビューカメラと経済的なミリ波レーダーセンサーを組み合わせた新しいマルチモード3D目標検出方法RCBEVDetが提案されました。 RCBEVDet は、マルチモード センサーからの情報を包括的に使用することで、高解像度のセマンティック情報を提供し、悪天候や低照度条件下でも優れたパフォーマンスを発揮することができます。自動
RCBEVDet を改善するこの方法の中核は、RadarBEVNet とクロスアテンション マルチレイヤー フュージョン モジュール (CAMF) という 2 つの主要な設計にあります。 RadarBEVNet は、レーダーの特徴を効率的に抽出するように設計されており、デュアルストリーム レーダー バックボーン ネットワーク RCS (レーダー クロス セクション) 対応 BEV (Bird's Eye View) エンコーダーが含まれています。このような設計では、点群ベースおよび変圧器ベースのエンコーダを使用して、レーダー ポイントを処理し、レーダー ポイントの特徴を対話的に更新し、レーダー固有の RCS 特性をターゲット サイズの事前情報として使用して、BEV 空間内のポイント フィーチャの分布を最適化します。 CAMF モジュールは、マルチモーダル クロス アテンション メカニズムを通じてレーダー ポイントの方位誤差問題を解決し、レーダーとカメラの BEV 特徴マップの動的位置合わせと、チャネルと空間融合によるマルチモーダル特徴の適応融合を実現します。 実装では、BEV 空間内の点特徴分布は、レーダー ポイント特徴を対話的に更新し、レーダー固有の RCS 特性をターゲット サイズの事前情報として使用することによって最適化されます。 CAMF モジュールは、マルチモーダル クロス アテンション メカニズムを通じてレーダー ポイントの方位誤差問題を解決し、レーダーとカメラの BEV 特徴マップの動的位置合わせと、チャネルと空間融合によるマルチモーダル特徴の適応融合を実現します。

この論文で提案されている新しい方法は、次の点を通じて既存の問題を解決します。
- 効率的なレーダー特徴抽出器 : デュアルストリーム レーダー バックボーンと RCS 対応 BEV エンコーダー設計を通じて、レーダー データの特性に合わせて特に最適化され、レーダー データを処理するために LIDAR 用に設計されたエンコーダーを使用する場合の欠点を解決します。
- 強力なレーダーとカメラの機能融合モジュール: 変形したクロスアテンション メカニズムを使用して、サラウンド画像とレーダー入力の間の空間的不整合の問題を効果的に処理し、融合効果を向上させます。
この論文の主な貢献は次のとおりです:
- 高精度、高効率、高精度を実現する新しいレーダーカメラ マルチモーダル 3D 目標検出器 RCBEVDet を提案しました。非常に堅牢な 3D オブジェクト検出。
- レーダー データの効率的な特徴抽出機能である RadarBEVNet が設計されており、デュアル ストリーム レーダー バックボーンと RCS 対応 BEV エンコーダーを通じて特徴抽出の効率と精度が向上します。
- クロスアテンション マルチレイヤー フュージョン モジュールは、変形クロスアテンション メカニズムを通じて、レーダーとカメラの機能の正確な位置合わせと効率的な融合を実現するために導入されています。
- 精度と速度の最適なバランスを実現しながら、nuScenes および VoD データセット上のレーダー カメラ マルチモーダル 3D オブジェクト検出で新しい最先端のパフォーマンスを達成し、センサー障害時の堅牢性を実証しました。状況。
#RCBEVDet の詳しい説明
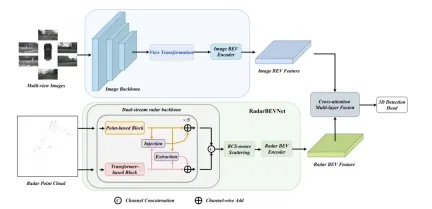
RadarBEVNet は、で提案されています。効果的な鉱山車両 BEV (バード ビュー) 特徴抽出に使用されるネットワーク アーキテクチャには、主に 2 つのコア コンポーネントが含まれています。デュアル ストリーム レーダー バックボーン ネットワークと RCS (レーダー断面積) センシング BEV エンコーダーです。 デュアルストリーム レーダー バックボーン ネットワークを使用して、マルチチャネル レーダー データから豊富な特徴表現を抽出します。これはディープ畳み込みニューラル ネットワーク (CNN) 上に構築されており、入れ子になった畳み込み層とプーリング層の間で特徴抽出と次元削減操作を交互に行い、段階的に抽出を取得します
#デュアルストリーム レーダー バックボーン
デュアルストリーム レーダー バックボーン ネットワークは、ポイントベースのバックボーンとコンバータベースのバックボーンで構成されます。ポイントベースのバックボーン ネットワークは、多層パーセプトロン (MLP) と最大プーリング操作を通じてレーダー フィーチャを学習します。プロセスは次の式に簡略化できます:
ここでレーダー ポイント フィーチャを表します。MLP を通じてフィーチャ ディメンションを追加した後を最大プーリング操作によりグローバル情報を抽出し、高次元の特徴と接続します。 コンバーターは干渉ブロックに基づいており、距離変調注意メカニズム (DMSA) を導入しています。レーダー ポイント間の距離情報を考慮することで、隣接する情報を収集するモデルの能力を最適化し、モデルの収束を促進します。 。 DMSA メカニズムのセルフアテンションは次のように表現できます:RCS 対応 BEV エンコーダ
従来のレーダー BEV エンコーダによって生成される BEV 特徴のスパース性問題を解決するために、RCS 対応 BEV エンコーダが提案されています。ターゲット サイズの事前情報として RCS を利用し、レーダー ポイントの特徴を単一ピクセルではなく BEV 空間内の複数のピクセルに分散して、BEV 特徴の密度を高めます。このプロセスは、次の式によって実装されます。
ここで、 は RCS に基づくガウス BEV 重みマップであり、すべてのレーダー ポイントの重みマップを最大化することによって最適化されます。最後に、RCS 拡散によって取得された特徴は MLP によって接続および処理され、最終的な RCS 対応 BEV 特徴が取得されます。
全体として、RadarBEVNet は、デュアルストリーム レーダー バックボーン ネットワークと RCS 対応 BEV エンコーダーを組み合わせることでレーダー データの特徴を効率的に抽出し、ターゲットのアプリオリとして RCS を使用することで BEV 空間の特徴分布を最適化します。サイズ。これは、その後のマルチモーダル融合のための強力な基盤を提供します。

クロスアテンション マルチレイヤー フュージョン モジュール
クロスアテンション マルチレイヤー フュージョン モジュール (CAMF) は、高度なマルチモーダル機能の動的な位置合わせと融合のためのネットワーク構造。特にレーダーとカメラによって生成される鳥瞰図 (BEV) 機能の動的な位置合わせと融合のために設計されています。このモジュールは、主にレーダー点群の方位誤差によって引き起こされるフィーチャの位置ずれの問題を解決し、変形可能なクロスアテンション メカニズム (Deformable Cross-Attention) を通じて、レーダー ポイントの小さな偏差を効果的に捕捉し、標準的なクロスアテンションを削減します。計算の複雑さ。
CAMF は、変形したクロスアテンション メカニズムを利用して、カメラとレーダーの BEV 機能を調整します。カメラとレーダーの BEV 特徴の合計が与えられると、学習可能な位置埋め込みが最初に合計に追加され、次にキーと値としてクエリおよび参照ポイントに変換されます。マルチヘッド変形クロス アテンションの計算は次のように表すことができます。
ここで、 はアテンション ヘッドのインデックス、 はサンプリング キーのインデックス、 はサンプリング キーの総数です。サンプリング オフセットを表し、 と によって計算されるアテンション ウェイトです。
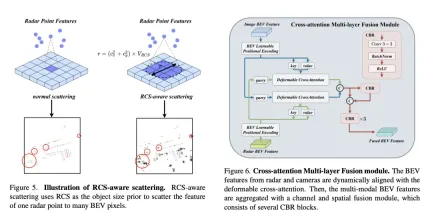
クロスアテンションを通じてカメラとレーダーの BEV 機能を調整した後、CAMF はチャネルおよび空間融合レイヤーを使用してマルチモーダル BEV 機能を集約します。具体的には、2 つの BEV 特徴が最初に連結され、次に CBR (畳み込みバッチ正規化活性化機能) ブロックに入力され、残りの接続を通じて融合された特徴が取得されます。 CBR ブロックは、畳み込み層、バッチ正規化層、ReLU 活性化関数から順に構成されます。その後、3 つの CBR ブロックが連続して適用され、マルチモーダル機能がさらに融合されます。
上記のプロセスを通じて、CAMF は正確な位置合わせとレーダーとカメラの BEV 機能の効率的な融合を効果的に実現し、3D ターゲット検出のための豊富で正確な機能情報を提供し、検出パフォーマンスを向上させます。
関連実験

VoD 検証セットでの 3D ターゲット検出結果の比較では、RadarBEVNet がカメラとレーダーのデータを融合し、注釈領域全体および対象領域内の平均精度 (mAP) パフォーマンスの点で優れたパフォーマンスを示します。具体的には、注釈付きエリア全体で、RadarBEVNet は自動車、歩行者、自転車の検出においてそれぞれ 40.63%、38.86%、70.48% の AP 値を達成し、総合的な mAP は 49.99% に増加しました。対象領域、つまり車両に近い走行チャネルでは、RadarBEVNet のパフォーマンスはさらに優れており、車、歩行者、車両の検出において AP 値が 72.48%、49.89%、87.01% に達しました。それぞれサイクリストを対象とし、総合的な mAP は 69.80% に達しました。
これらの結果から、いくつかの重要な点が明らかになりました。まず、RadarBEVNet は、カメラとレーダーの入力を効果的に融合することで、2 つのセンサーの相補的な利点を最大限に活用し、全体的な検出パフォーマンスを向上させることができます。 PointPillar や RadarPillarNet などのレーダーのみを使用する方法と比較して、RadarBEVNet は包括的な mAP が大幅に向上しています。これは、マルチモーダル融合が検出精度を向上させるために特に重要であることを示しています。第 2 に、RadarBEVNet は関心のある領域で特に優れたパフォーマンスを発揮します。これは、関心のある領域内のターゲットが通常、リアルタイムの運転決定に最大の影響を与えるため、自動運転アプリケーションにとって特に重要です。最後に、RadarBEVNet の AP 値は、自動車や歩行者の検出において一部のシングルモーダルまたは他のマルチモーダル手法よりわずかに低いものの、自転車検出と包括的な mAP パフォーマンスにおいて、RadarBEVNet の全体的なパフォーマンス上の利点が示されています。 RadarBEVNet は、カメラとレーダーからのマルチモーダル データを融合することにより、VoD 検証セットで優れたパフォーマンスを実現し、特に自動運転にとって重要な関心領域での強力な検出機能を実証し、3D オブジェクト検出方法の可能性としての有効性を証明しています。

このアブレーション実験は、RadarBEVNet が主要コンポーネントを段階的に追加することで 3D オブジェクト検出パフォーマンスが継続的に向上していることを示しています。ベースライン モデル BEVDepth から始まり、各ステップで追加されたコンポーネントにより、NDS (検出精度と完全性を反映するコア メトリック) と mAP (オブジェクトを検出するモデルの能力を反映する平均精度) が大幅に向上します。
- 時間情報の追加: 時間情報を導入することにより、NDS と mAP はそれぞれ 4.4 パーセント ポイントと 5.4 パーセント ポイント改善されました。これは、時間情報が 3D オブジェクト検出の精度とロバスト性を向上させるのに非常に効果的であることを示しています。これはおそらく、時間次元によって、モデルがシーンとオブジェクトの動的特性をよりよく理解するのに役立つ追加の動的情報が提供されるためです。
- PointPillar BEVFusion に参加 (レーダーとカメラの融合に基づく): このステップにより、NDS と mAP がさらに改善され、それぞれ 1.7 パーセント ポイントと 1.8 パーセント ポイント増加します。これは、レーダーとカメラのデータを融合することで、モデルがより包括的なシーンの理解を取得し、単一モーダル データの制限を補うことができることを示しています。
- RadarBEVNetのご紹介: NDSとmAPは、それぞれ2.1パーセントと3.0パーセントポイント再び増加しました。 RadarBEVNet は、効率的なレーダー特徴抽出ツールとして、レーダー データの処理を最適化し、全体的な検出パフォーマンスを向上させるために重要な機能の品質と有効性を向上させます。
- CAMF (クロス アテンション マルチレイヤー フュージョン モジュール) の追加: 微細な機能の位置合わせと融合により、NDS が 0.7 パーセント ポイント増加し、mAP が 45.6 にわずかに改善され、改善が示されています。機能融合の有効性の側面において。このステップでの改善は前のステップほど顕著ではありませんが、マルチモーダル融合プロセス中の検出パフォーマンスを向上させるには正確な特徴位置合わせの重要性が証明されています。
- 時間監視の追加: 最後に、時間監視の導入後、NDS は 0.4 パーセント ポイント増加して 56.8 となり、mAP は 0.3 パーセント ポイント減少して 45.3 になりました。これは、mAP への貢献は特定の実験設定やデータ分布の影響によってわずかに制限される可能性があるものの、時間的監視によって時間的次元でのモデルのパフォーマンスをさらに向上させることができることを示しています。
全体として、この一連のアブレーション実験は、時間情報の導入から複雑なマルチモダリティ Fusion 戦略に至るまで、RadarBEVNet の各主要コンポーネントが 3D 物体検出パフォーマンスの向上に貢献していることを明確に示しており、各ステップがもたらす効果は次のとおりです。モデルのパフォーマンスが向上します。特に、レーダーとカメラのデータの高度な処理と融合戦略は、複雑な自動運転環境におけるマルチモーダル データ処理の重要性を証明しています。
ディスカッション
この論文で提案されている RadarBEVNet 手法は、カメラとレーダーからのマルチモーダル データを融合することにより、3D ターゲット検出の精度とロバスト性を効果的に向上させます。複雑な自動運転シナリオにも適しています。 RadarBEVNet とクロスアテンション多層融合モジュール (CAMF) を導入することにより、RadarBEVNet はレーダー データの特徴抽出プロセスを最適化するだけでなく、レーダー データとカメラ データの間の正確な特徴位置合わせと融合を実現し、単一のデータを使用する際の問題を克服します。センサーデータの制限(レーダー方位エラーや、低照度または悪天候時のカメラの性能低下など)。
利点の観点から見ると、RadarBEVNet の主な貢献は、マルチモーダル データ間の補完情報を効果的に処理して利用し、検出精度とシステムの堅牢性を向上させる能力です。 RadarBEVNet の導入によりレーダー データの処理がより効率的になり、CAMF モジュールにより異なるセンサー データが効果的に融合され、それぞれの欠点が補われます。さらに、RadarBEVNet は、実験で複数のデータセット、特に自動運転において重要な関心領域で優れたパフォーマンスを実証し、実用的なアプリケーションシナリオでの可能性を示しました。
欠点としては、RadarBEVNet はマルチモーダル 3D ターゲット検出の分野で目覚ましい成果を上げていますが、それに応じて実装の複雑さも増し、より多くのコンピューティング リソースと処理時間が必要になる可能性があります。リアルタイム アプリケーション シナリオでの展開がある程度制限されます。さらに、RadarBEVNet は自転車検出と全体的なパフォーマンスでは優れていますが、特定のカテゴリ (自動車や歩行者など) でのパフォーマンスにはまだ改善の余地があり、これを解決するにはさらなるアルゴリズムの最適化やより効率的な機能融合戦略が必要になる可能性があります。
つまり、RadarBEVNet は、革新的なマルチモーダル フュージョン戦略を通じて、3D ターゲット検出の分野でパフォーマンスに大きな利点があることを実証しました。計算の複雑さの高さや特定の検出カテゴリでのパフォーマンス向上の余地など、いくつかの制限はありますが、自動運転システムの精度と堅牢性を向上させる可能性は無視できません。今後の作業は、実際の自動運転アプリケーションにおける RadarBEVNet の広範な展開を促進するために、アルゴリズムの計算効率を最適化し、さまざまなターゲット検出におけるパフォーマンスをさらに向上させることに焦点を当てることができます。
結論
この論文では、カメラとレーダーのデータを融合することにより、RadarBEVNet とクロスアテンション多層融合モジュール (CAMF) を紹介し、3D ターゲット検出の分野で重要な結果を示しています。特に自動運転の主要なシナリオにおけるパフォーマンスが向上しました。マルチモーダルデータ間の補完情報を効果的に利用して、検出精度とシステムの堅牢性を向上させます。計算の複雑さが高く、一部のカテゴリーではパフォーマンス向上の余地があるという課題にもかかわらず、私たちの技術は、自動運転技術の開発促進、特に自動運転システムの知覚能力の向上において大きな可能性と価値を示しています。今後の作業は、アルゴリズムの効率を最適化し、リアルタイム自動運転アプリケーションのニーズによりよく適応するために検出パフォーマンスをさらに向上させることに重点を置くことができます。
以上がRVフュージョンのパフォーマンスがすごい! RCBEVDet: レーダーにも春、最新の SOTA があります!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、
 Openaiを使用した3つの実験的な実験' s O1を確認する必要があります-AnalyticsVidhyaApr 13, 2025 am 11:06 AM
Openaiを使用した3つの実験的な実験' s O1を確認する必要があります-AnalyticsVidhyaApr 13, 2025 am 11:06 AM導入 あなたが話す前に、あなたはどれくらいの頻度で本当に考え、推論しますか?現在の最先端のLLMであるGPT-4Oは、多くの時間をかけて応答することなく、すでに印象的な反応を提供していました。しかし、それが取られ始めたら想像してみてください


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ドリームウィーバー CS6
ビジュアル Web 開発ツール

