
ホームページ >テクノロジー周辺機器 >AI >上海交通大学の新しいフレームワークは、CLIP の長文テキスト機能を解放し、マルチモーダル生成の詳細を把握し、画像検索機能を大幅に向上させます
上海交通大学の新しいフレームワークは、CLIP の長文テキスト機能を解放し、マルチモーダル生成の詳細を把握し、画像検索機能を大幅に向上させます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-01 09:26:33636ブラウズ
CLIP 長いテキスト機能が解放され、画像検索タスクのパフォーマンスが大幅に向上しました。
いくつかの重要な詳細もキャプチャできます。上海交通大学と上海AI研究所は、新しいフレームワーク Long-CLIP を提案しました。
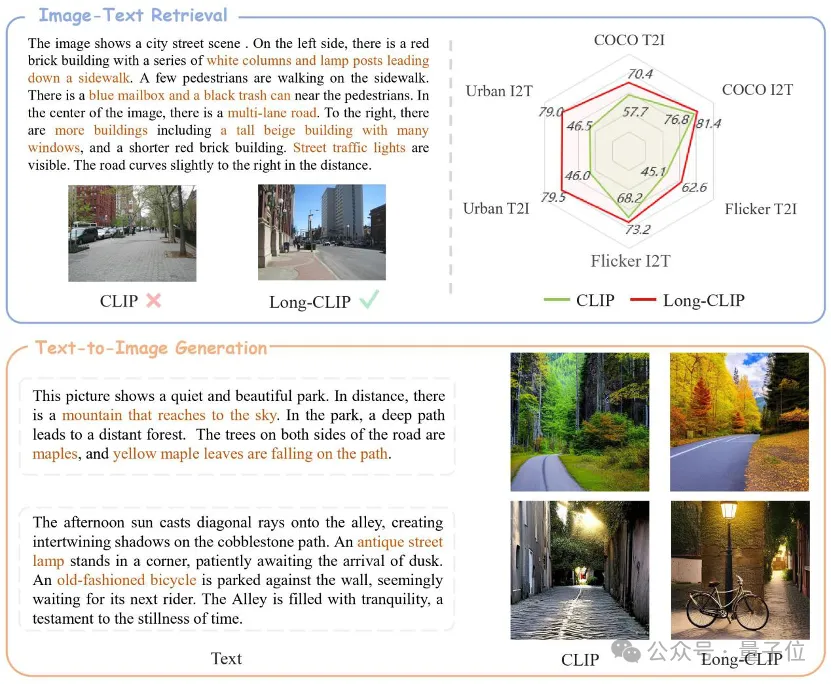
△茶色のテキストは 2 つの画像を区別する重要な詳細です
Long-CLIP は、CLIP の元の特徴空間を維持することに基づいています。画像生成などのダウンストリーム タスクにプラグアンドプレイして、長いテキストのきめ細かい画像生成を実現します。
長いテキスト画像の検索は 20% 増加し、短いテキスト画像の検索は 6% 増加しました。
CLIP ロング テキスト機能のロックを解除
CLIP は、ビジュアル モダリティとテキスト モダリティを調整し、強力なゼロショット汎化機能を備えています。したがって、CLIP は、画像分類、テキスト画像検索、画像生成などのさまざまなマルチモーダル タスクで広く使用されています。
しかし、CLIP の大きな欠点は、長いテキスト機能がないことです。
まず第一に、絶対位置エンコーディングの使用により、CLIP のテキスト入力の長さは 677 トークンに制限されます。それだけでなく、CLIP の実際の有効長は 20 トークンにも満たず、きめの細かい情報を表現するには十分ではないことが実験で証明されています。 しかし、この制限を克服するために、研究者たちは解決策を提案しました。テキスト入力に特定のタグを導入することで、モデルは重要な部分に焦点を当てることができます。入力内のこれらのトークンの位置と数は事前に決定されており、20 トークンを超えることはありません。 このようにして、CLIP は、テキスト入力を処理するときに、テキスト側で長いテキストが欠落している場合も
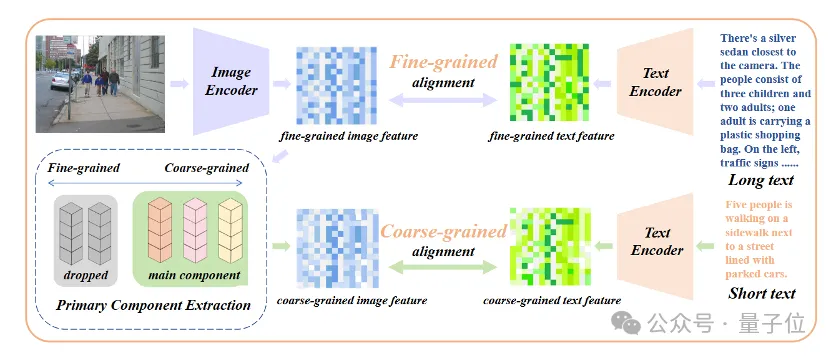
ビジュアル側の機能を制限することができます。短いテキストのみが含まれるため、CLIP のビジュアル エンコーダーは、さまざまな詳細を無視して、画像の最も重要なコンポーネントのみを抽出します。これは、クロスモーダル検索などのきめ細かいタスクにとって非常に有害です。
同時に、長いテキストがないため、CLIP は、因果推論などの複雑な機能を持たない、バッグオブフィーチャー (BOF) に似た単純なモデリング手法を採用します。
この問題に対応して、研究者は Long-CLIP モデルを提案しました。

具体的には、位置埋め込みの知識保持ストレッチング (位置埋め込みの知識保持ストレッチング) と、コア コンポーネントのアライメントを追加する微調整戦略 (プライマリ コンポーネント マッチング) の 2 つの主要な戦略を提案しました。
知識を保持した位置エンコーディングの拡張
入力長を拡張し、長いテキストの機能を強化する簡単な方法は、まず位置エンコーディングを固定比率で補間することです 1
を選択し、長文で微調整します。 研究者らは、CLIP の位置エンコーディングが異なるとトレーニングの程度が異なることを発見しました。トレーニング テキストは主に短いテキストである可能性が高いため、下位位置のコーディングはより完全にトレーニングされ、絶対位置を正確に表すことができますが、上位位置のコーディングはおおよその相対位置しか表すことができません。したがって、異なる位置でコードを補間するコストは異なります。上記の観察に基づいて、研究者は最初の 20 個の位置コードを保持し、残りの 57 個の位置コードについて、より大きな比率 λ2
で補間すると、計算式は次のように表すことができます。 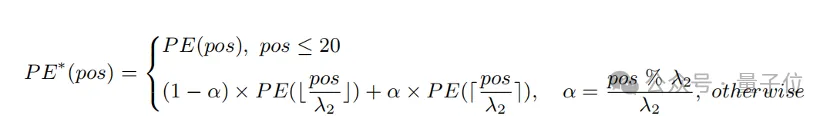
たとえば、画像とテキストの検索では、Long-CLIP は画像とテキスト モードでより詳細な情報をキャプチャできるため、類似した画像とテキストを区別する能力が強化され、画像とテキストの検索パフォーマンスが大幅に向上します。
従来の短いテキスト検索 (COCO、Flickr30k) であっても、長いテキスト検索タスクであっても、Long-CLIP は再現率を大幅に向上させました。
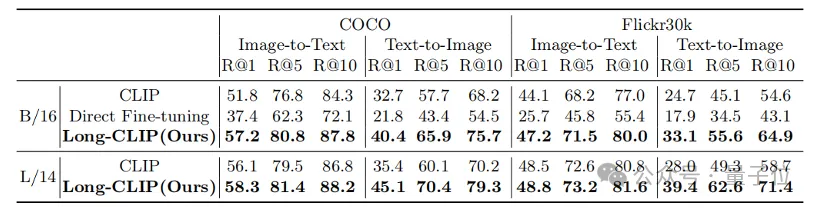
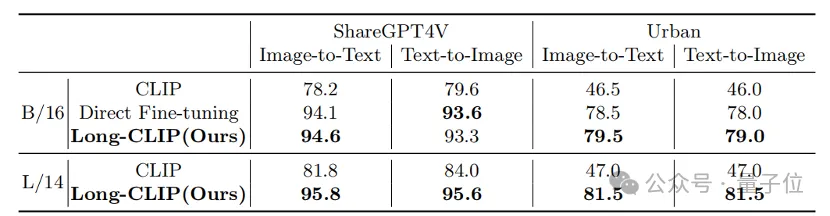 ##△長いテキスト画像の検索実験結果
##△長いテキスト画像の検索実験結果
 △長いテキストと画像の検索の視覚化、茶色のテキストが 2 つの画像を区別する重要な詳細です
△長いテキストと画像の検索の視覚化、茶色のテキストが 2 つの画像を区別する重要な詳細です
さらに、CLIP のテキスト エンコーダーは、テキストを画像に生成するためによく使用されます安定拡散シリーズなどのモデルただし、長いテキスト機能がないため、画像の生成に使用されるテキストの説明は通常非常に短く、さまざまな詳細をカスタマイズすることはできません。
Long-CLIP は 77 トークンの制限を突破し、チャプターレベルの画像生成を実現できます (右下)。
また、77 個のトークン内でさらに詳細をモデル化して、きめの細かい画像生成を実現することもできます (右上)。

https://arxiv.org/abs/2403.15378コードリンク:
https://github.com/beichenzbc/Long-CLIP
以上が上海交通大学の新しいフレームワークは、CLIP の長文テキスト機能を解放し、マルチモーダル生成の詳細を把握し、画像検索機能を大幅に向上させますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。