


写真と音声だけで、キャラクターが話しているビデオを直接生成できます。
最近、Google の研究者がマルチモーダル拡散モデル VLOGGER をリリースし、バーチャル デジタル ヒューマンに一歩近づきました。

#論文アドレス: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger は、単一の入力画像を収集し、テキストまたはオーディオ ドライバーを使用して、口の形、表情、体の動きなどを含む非常に自然な人間の音声のビデオを生成できます。
まずはいくつかの例を見てみましょう:




ビデオ内での他の人の声の使用が少し矛盾していると感じる場合は、エディターが音をオフにするお手伝いをします:

VLOGGER は、人間を 3D モーションに変換するモデルや、時間と空間を介して制御するための新しい拡散ベースのアーキテクチャなど、拡散モデルの生成における最近の成功に基づいて構築されており、テキストで生成された画像。



 #以前の同様のモデルと比較して、VLOGGER は個人に対してトレーニングする必要がなく、トレーニングを行うことができます。顔の検出やトリミングに依存するのではなく、体の動き、胴体、背景もコミュニケーション可能な通常の人間の表現を構成します。
#以前の同様のモデルと比較して、VLOGGER は個人に対してトレーニングする必要がなく、トレーニングを行うことができます。顔の検出やトリミングに依存するのではなく、体の動き、胴体、背景もコミュニケーション可能な通常の人間の表現を構成します。
AI音声、AI表現、AIアクション、AIシーン、最初はデータを提供することが人間の価値ですが、将来的には価値がなくなるのでは?

 データ面では、研究者は以前の同様のデータセットよりも新しく多様なデータセット MENTOR を収集しました。データ セットは一桁大きく、トレーニング セットには 2,200 時間、800,000 人の異なる個人が含まれ、テスト セットには 120 時間、異なるアイデンティティを持つ 4,000 人の人々が含まれていました。
データ面では、研究者は以前の同様のデータセットよりも新しく多様なデータセット MENTOR を収集しました。データ セットは一桁大きく、トレーニング セットには 2,200 時間、800,000 人の異なる個人が含まれ、テスト セットには 120 時間、異なるアイデンティティを持つ 4,000 人の人々が含まれていました。
 研究者らは 3 つの異なるベンチマークで VLOGGER を評価し、このモデルが画質、アイデンティティの保持、最適な時間的一貫性。
研究者らは 3 つの異なるベンチマークで VLOGGER を評価し、このモデルが画質、アイデンティティの保持、最適な時間的一貫性。

VLOGGER
VLOGGER の目標は、対象者が話すプロセス全体を描写する可変長のリアルなビデオを生成することです。 , 頭の動きやジェスチャーが含まれます。

上記のとおり、列 1 に示されている単一の入力画像とサンプル音声入力が与えられた場合、一連の合成画像が得られます。
頭の動き、視線、まばたき、唇の動きの生成、および以前のモデルではできなかった上半身とジェスチャーの生成が含まれており、これはオーディオ駆動合成の大きな進歩です。 。
VLOGGER は、ランダム拡散モデルに基づく 2 段階のパイプラインを採用し、音声からビデオへの 1 対多のマッピングをシミュレートします。
最初のネットワークは、音声波形を入力として受け取り、ターゲット ビデオ全体にわたって視線、顔の表情、ジェスチャーを制御する身体動作制御を生成します。
2 番目のネットワークは、大規模画像拡散モデルを拡張して、予測された身体制御を使用して対応するフレームを生成する時間的な画像間変換モデルです。このプロセスを特定のアイデンティティと一致させるために、ネットワークは対象者の参照画像を取得します。
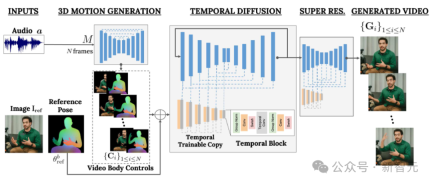
VLOGGER は、統計に基づいた 3D ボディ モデルを使用してビデオ生成プロセスを調整します。入力画像が与えられると、予測された形状パラメーターはターゲット ID の幾何学的特性をエンコードします。
まず、ネットワーク M は入力音声を取得し、3D の顔の表情と体のポーズの一連の N フレームを生成します。
動く 3D ボディの高密度表現は、ビデオ生成段階で 2D コントロールとして機能するようにレンダリングされます。これらの画像は、入力画像とともに、時間拡散モデルおよび超解像度モジュールへの入力として機能します。
オーディオ主導のモーション生成
パイプラインの最初のネットワークは、入力音声に基づいてモーションを予測するように設計されています。 。さらに、入力テキストはテキスト読み上げモデルを通じて波形に変換され、生成された音声は標準のメル スペクトログラムとして表現されます。
パイプラインは Transformer アーキテクチャに基づいており、時間次元に 4 つのマルチヘッド アテンション レイヤーがあります。フレーム番号と拡散ステップの位置エンコーディング、および入力オーディオと拡散ステップの埋め込み MLP が含まれます。
各フレームで因果マスクを使用して、モデルが前のフレームのみに焦点を当てるようにします。モデルは可変長ビデオ (TalkingHead-1KH データセットなど) を使用してトレーニングされ、非常に長いシーケンスを生成します。
研究者らは、統計に基づいて推定された 3D 人体モデルのパラメーターを使用して、合成ビデオの中間制御表現を生成します。
モデルは、顔の表情と体の動きの両方を考慮して、より表現力豊かでダイナミックなジェスチャーを生成します。
さらに、以前の顔生成作業は通常、ワープされた画像に依存していましたが、この方法は拡散ベースのアーキテクチャでは無視されてきました。
著者らは、歪んだ画像を使用して生成プロセスをガイドすることを推奨しています。これにより、ネットワークのタスクが容易になり、キャラクターの主体性の維持に役立ちます。
#話したり動く人間を生成する
#次の目標は、入力画像に対してモーション処理を実行することです。 person を作成し、事前に予測された体と顔の動きに追従させます。
ControlNet に触発されて、研究者らは最初にトレーニングされたモデルを凍結し、入力時間制御を使用してゼロ初期化されたトレーニング可能なエンコード層のコピーを作成しました。
著者は、時間領域で 1 次元の畳み込み層をインターリーブし、連続する N 個のフレームとコントロールを取得することでネットワークをトレーニングし、入力されたコントロールに基づいて参照キャラクターのアクション ビデオを生成します。
モデルは、作成者によって構築された MENTOR データセットを使用してトレーニングされます。トレーニング プロセス中に、ネットワークは一連の連続フレームと任意の参照画像を取得するため、理論上は任意のビデオはフレームを参照として指定できます。
ただし、実際には、サンプルが近いほど一般化の可能性が低くなるため、著者はターゲット クリップから遠く離れた参照をサンプリングすることを選択します。
ネットワークは 2 段階でトレーニングされます。最初に単一フレームで新しい制御層を学習し、次に時間コンポーネントを追加してビデオでトレーニングします。これにより、最初の段階で大規模なバッチを使用し、ヘッド リプレイ タスクをより速く学習できるようになります。
著者が採用した学習率は 5e-5 で、画像モデルは両方のステージでステップ サイズ 400k、バッチ サイズ 128 でトレーニングされています。
#多様性
次の図は、入力画像から生成されたターゲット ビデオの多様な分布を示しています。一番右の列は、生成された 80 個のビデオから得られたピクセルの多様性を示しています。

背景は固定されたままですが、人の頭と体は大きく動きます (赤はピクセルの色の多様性が高いことを意味します)。そして、多様性にもかかわらず、すべてビデオがリアルに見えます。
ビデオ編集

モデルの応用例の 1 つは、次のようなものです。既存のビデオを編集します。この場合、VLOGGER はビデオを撮影し、被写体の口や目を閉じるなどの表情を変えます。
実際には、作成者は拡散モデルの柔軟性を利用して、変更する必要がある画像の部分を修復し、ビデオ編集を元の変更されていないピクセルと一致させます。
ビデオ翻訳
モデルの主な用途の 1 つはビデオ翻訳です。この場合、VLOGGER は特定の言語で既存のビデオを取得し、新しい音声 (スペイン語など) に合わせて唇と顔の領域を編集します。
以上がたった1枚の写真からAI動画が生成できる! Googleの新たな普及モデルでキャラクターが動くの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

