
ホームページ >テクノロジー周辺機器 >AI >合体後のモデルは進化し、SOTAに直接勝利します! 『トランスフォーマー』著者の新たな起業家としての功績が人気
合体後のモデルは進化し、SOTAに直接勝利します! 『トランスフォーマー』著者の新たな起業家としての功績が人気

- 王林転載
- 2024-03-26 11:30:14651ブラウズ
Huggingface の 既成モデル を使用して「節約」します -
それらを直接組み合わせて新しい強力なモデルを作成できますか? !
日本の大手模型会社 sakana.ai は非常にクリエイティブでした (「トランスフォーマー エイト」の 1 人が設立した会社です) 統合モデルを進化させるためにこのようなクーデターを思いつきました。

この方法では、新しい基本モデルを自動的に生成できるだけでなく、パフォーマンスがまったく悪いです。:
彼ら 70 億のパラメータを含む日本の数学の大規模モデルを利用して、関連ベンチマークで最先端の結果を達成し、700 億パラメータの Llama-2 などの以前のモデルを上回りました。
最も重要なことは、このようなモデルに到達するのに勾配トレーニングが必要ないということです。そのため、必要なコンピューティング リソースが大幅に削減されます。 NVIDIA の科学者 Jim Fan は、この論文を読んだ後、次のように賞賛しました。
これは、私が最近読んだ論文の中で最も想像力豊かな論文の 1 つです。 マージと進化、新しい基本モデルの自動生成
マージと進化、新しい基本モデルの自動生成
オープンソースの大規模モデル ランキングで最もパフォーマンスの高いモデルのほとんどが廃止されましたLLaMA または、Mistral のような「オリジナル」モデルですが、モデルを微調整したり結合したりすると、次のことがわかります。
新しいトレンドが出現しました。
Sakana.ai は、オープンソースの基本モデルを何百もの異なる方向に簡単に拡張および微調整でき、新しい分野で優れたパフォーマンスを発揮する新しいモデルを生成できることを紹介しました。
これらの中で、
モデルのマージは大きな可能性を示しています。
 しかし、それは直感と専門知識に大きく依存する一種の「黒魔術」かもしれません。
しかし、それは直感と専門知識に大きく依存する一種の「黒魔術」かもしれません。
したがって、より体系的な
アプローチが必要です。 自然界の自然選択にインスピレーションを得たSakana.aiは、進化アルゴリズムに焦点を当て、「進化モデルのマージ」の概念を導入し、最適なモデルを発見できる手法を提案しました。組み合わせ。
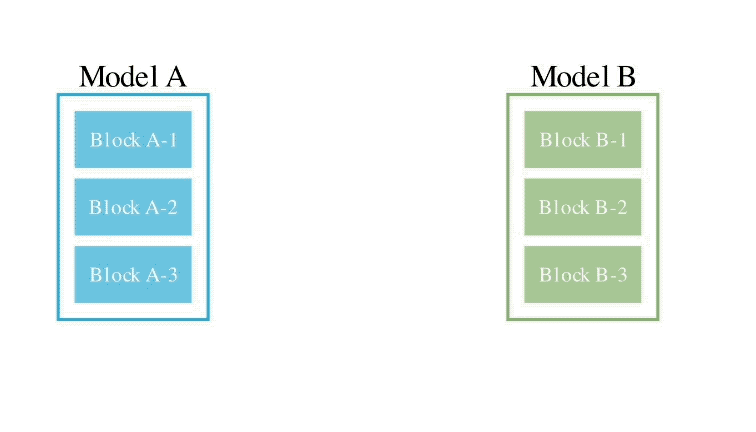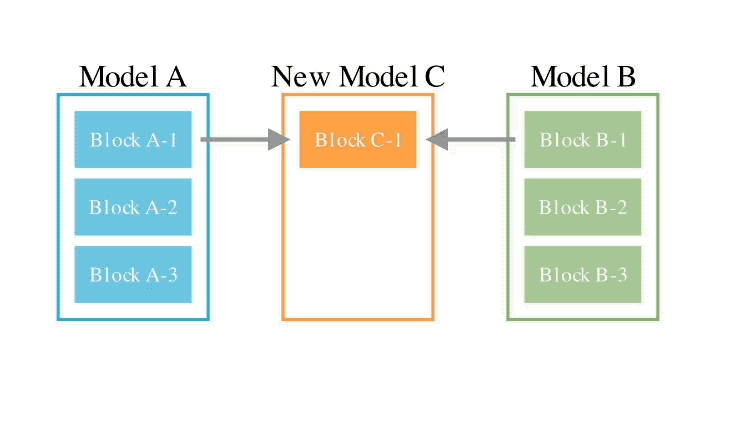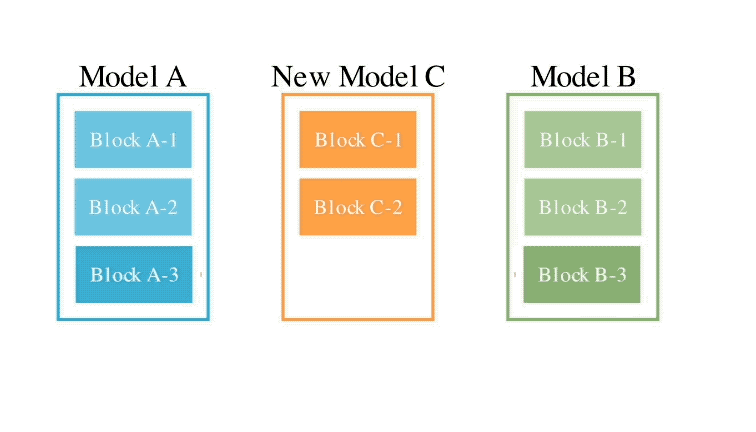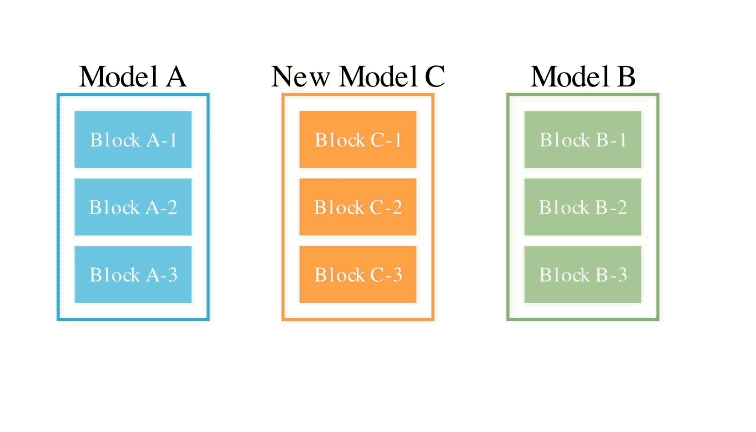
このメソッドは、2 つの異なるアイデアを組み合わせたものです: (1) データ フロー スペース
(レイヤー)でモデルを結合する、および (2) パラメーター スペースを結合する
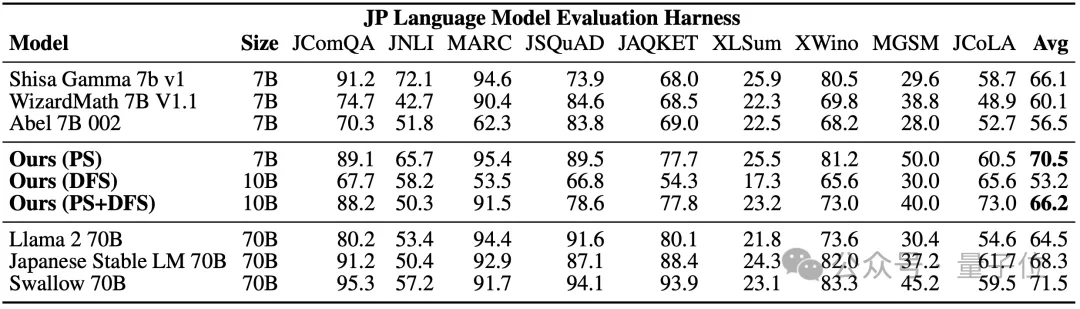
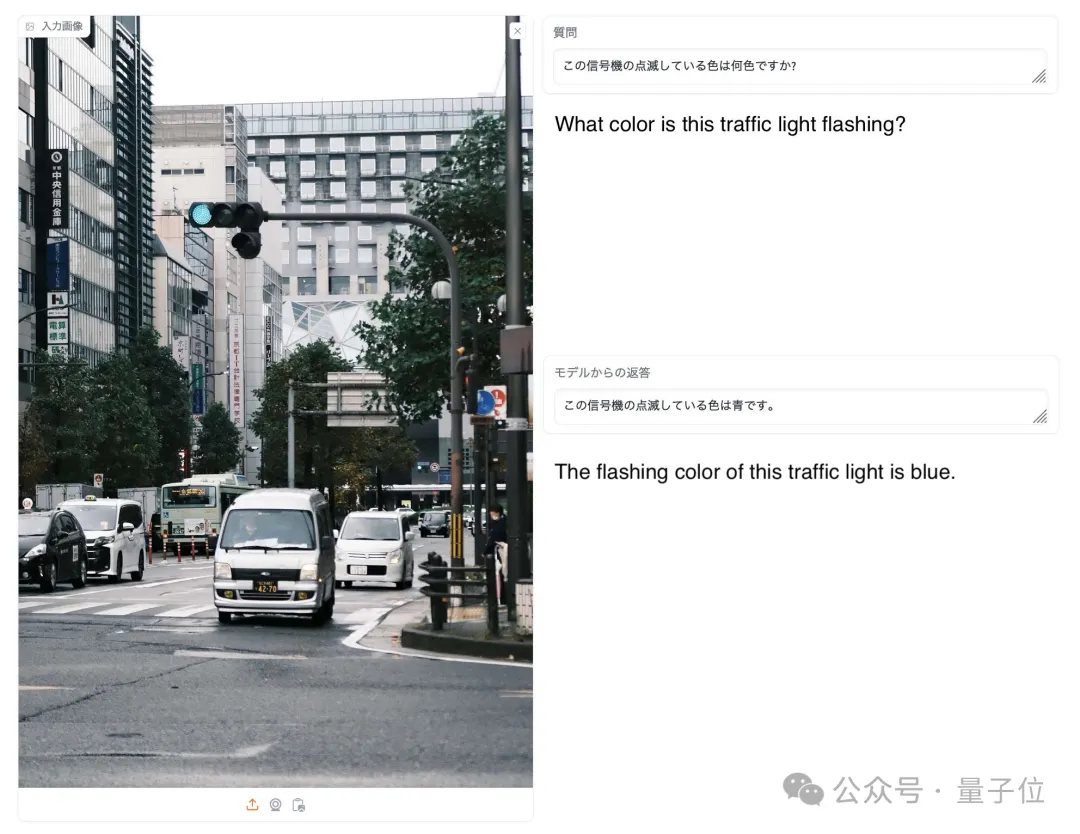
(重み) モデル ()。 具体的には、最初のデータ フロー スペース手法では、進化を使用して、新しいモデルを形成するためのさまざまなモデル層の最適な組み合わせを発見します。 これまで、コミュニティは、モデルのどのレイヤーを別のモデルのレイヤーとどのように組み合わせることができるかを決定するために直感に頼っていました。 しかし実際には、この問題には膨大な組み合わせの探索空間があり、進化アルゴリズムなどの最適化アルゴリズムによる探索に最適であるとSakana.aiは紹介しました。 操作例は次のとおりです。 2 番目のパラメータ空間方法では、複数のモデルの重みを混合して新しいモデルを形成します。 実際には、この方法を実装する方法は無数にあり、原理的には、混合の各層で異なる混合比、さらにはそれ以上の混合比を使用できます。 そしてここで、進化的手法を使用すると、より新しいハイブリッド戦略を効果的に見つけることができます。 次は、2 つの異なるモデルの重みを混合して新しいモデルを取得する例です: 上記 2 つの方法を組み合わせるだけです : 具体的に見てください。 1. EvoLLM-JP GSM8K データセットの多言語バージョンである MGSM の日本語評価セットで次の結果を達成しました。 : このうち、モデル 4 はパラメータ空間のみで最適化されており、モデル 6 はモデル 4 をデータ フロー空間でさらに最適化した結果です。 データ機能と一般的な日本語スキルの両方を評価する日本語 lm-evaluation-harness ベンチマークでは、EvoLLM-JP は、わずか 70 億のパラメーターを使用して、9 つのタスクで最高平均スコア 70.5 を達成しました。 700億個のラマ2など。 チームは、EvoLLM-JP は一般的な日本語モデルとして使用し、いくつかの興味深い例を解決するのに十分であると述べています: たとえば、特定の日本語文化が必要です。数学の知識の問題や、関西弁で日本のジョークを言ったりします。 2、EvoVLM-JP 画像の質問と回答の次の 2 つのベンチマーク データ セットでは、スコアが高いほど、モデルは回答します。日本語での説明はより正確です。 結果として、ベースとなっている英語版 VLM LLaVa-1.6-Mistral-7B よりも優れているだけでなく、既存の日本語 VLM よりも優れています。 下の写真に示すように、写真の信号灯の色は何色ですかと尋ねたところ、EvoVLM-JP だけが「青」と正解しました。 3. EvoSDXL-JP 日本語のみをサポートするこの SDXL モデルには 4 つの拡散モデルが必要ですを実行でき、生成速度は非常に高速です。 具体的なランニングスコアはまだ発表されていないが、チームは「非常に有望」であることを明らかにした。 いくつかの例をお楽しみいただけます: プロンプトの単語には、味噌ラーメン、最高品質の浮世絵、葛飾北斎、江戸時代が含まれます。 上記の 3 つの新しいモデルについて、チームは次のことを指摘しました: 原理的には、勾配ベースの逆伝播を使用して、これらのモデルのパフォーマンスを上回ります。 しかし、 は使用しません。今の目的は、バックプロパゲーションがなくても、現在のモデルに対抗する十分に高度な基本モデルを取得できることを示すことだからです。 「高価なパラダイム」。 ネチズンは次々にこれを気に入りました。 Jim Fan は次のようにも追加しました: 基本モデルの分野では、 現在のコミュニティはモデルに学習させることにほぼ完全に焦点を当てており、あまり注意を払っていません。 search ですが、後者は実際にはトレーニング (つまり、この記事で提案する進化的アルゴリズム) と推論段階で大きな可能性を秘めています。 つまり、ネチズンが言ったように: 私たちは現在、モデルのカンブリア紀にいます。大爆発の時代ですか? 論文アドレス: https://arxiv.org/abs/2403.13187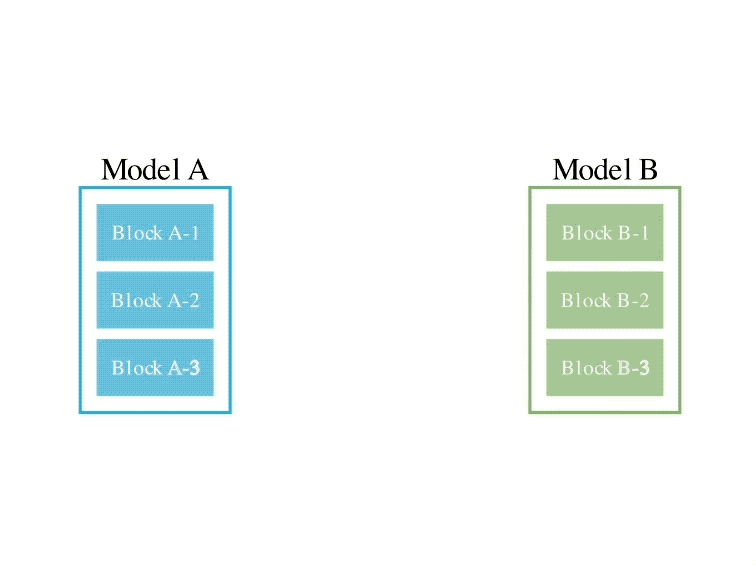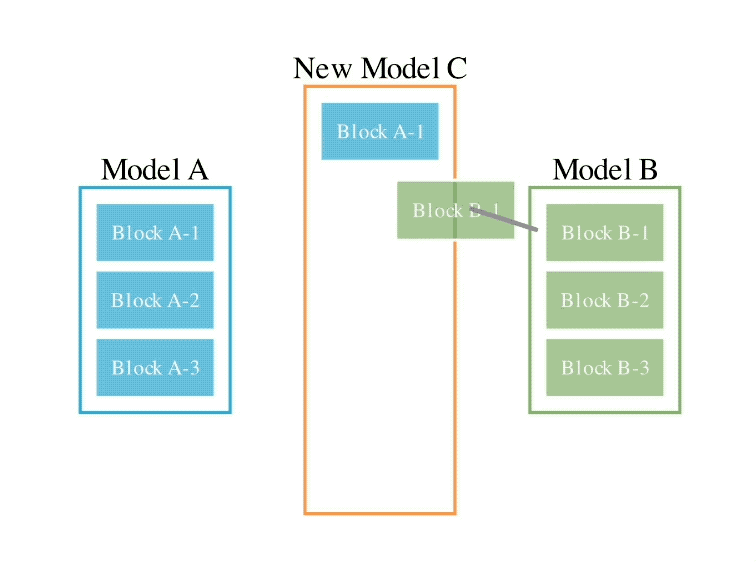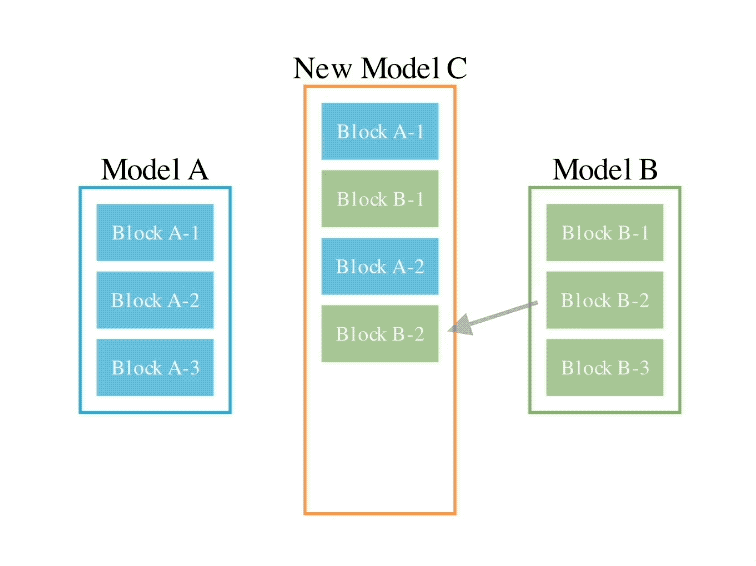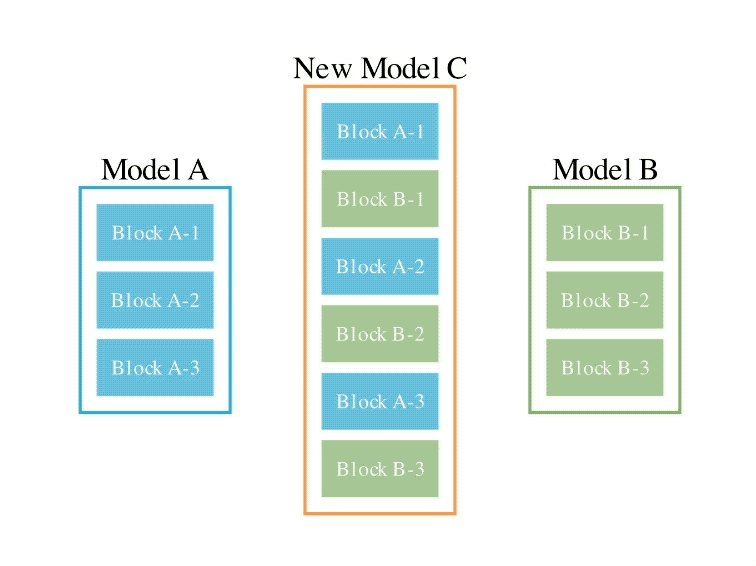
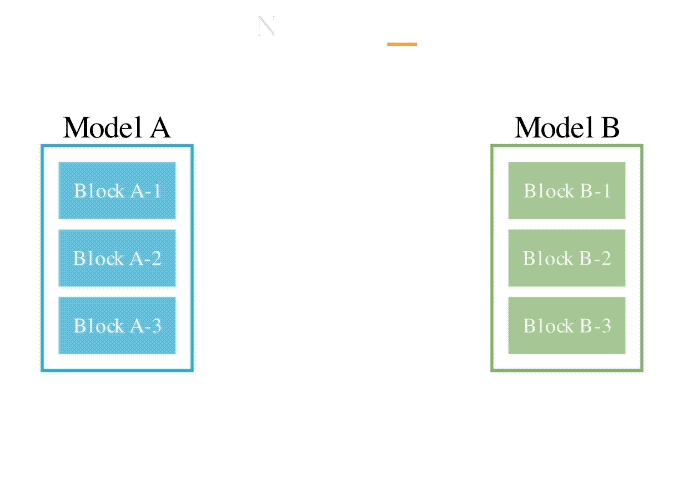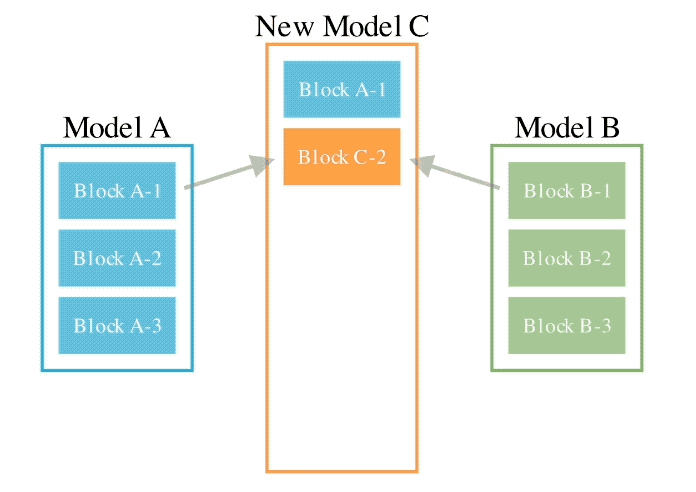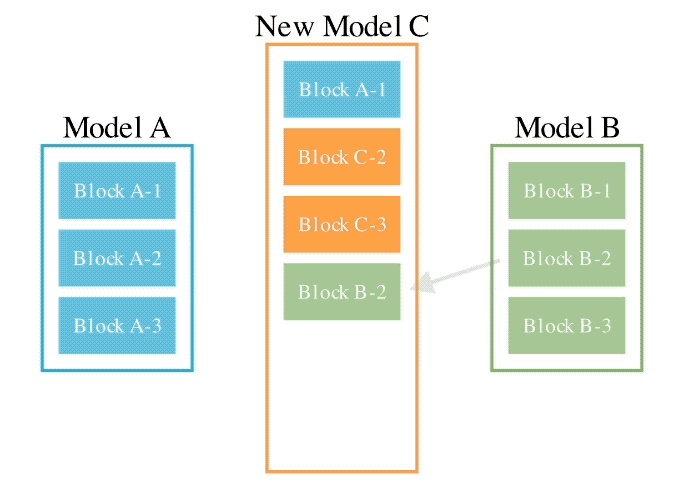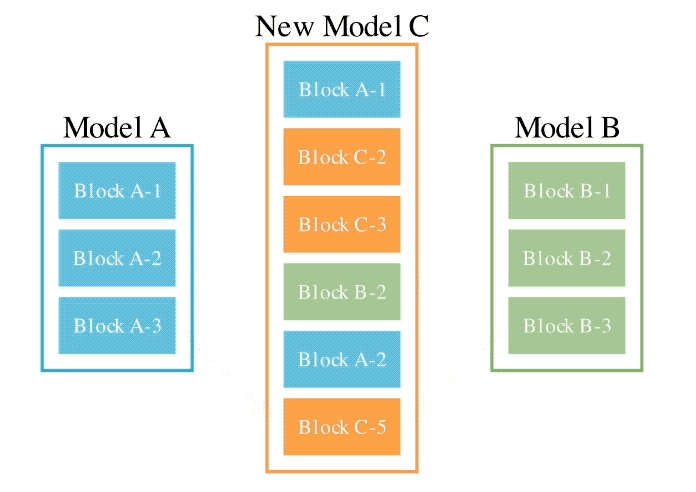
は、大規模な日本語モデル Shisa-Gamma と大規模な数学モデル WizardMath/Abel を統合して形成されており、日本の数学の問題を解くのが得意で、100 年にわたって進化しています。 -150世代。
#画像生成モデル EvoSDXL-JP


△マスク氏のお気に入り

以上が合体後のモデルは進化し、SOTAに直接勝利します! 『トランスフォーマー』著者の新たな起業家としての功績が人気の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。