




強化学習アルゴリズム (RL) と進化的アルゴリズム (EA) は、機械学習の分野における 2 つのユニークなアルゴリズムです。どちらも機械学習のカテゴリに属しますが、問題解決の手法や考え方には明らかな違いがあります。
強化学習アルゴリズム:
強化学習は機械学習手法であり、その核となるのは、エージェントが環境と対話し、累積を最大化するための試行錯誤を通じて最適な行動戦略を学習することです。褒美 。強化学習の鍵は、エージェントが常にさまざまな行動を試み、報酬信号に基づいて戦略を調整することです。エージェントは環境と対話することで、確立された目標を達成するために意思決定プロセスを徐々に最適化します。この手法は人間の学習方法を模倣し、継続的な試行錯誤と調整を通じてパフォーマンスを向上させ、エージェントが複雑な方法で学習できるようにします。強化学習の主な構成要素には、環境、エージェント、状態、アクション、報酬が含まれます。
一般的な強化学習アルゴリズムには、Q ラーニング、DeepQ-Networks (DQN)、PolicyGradient などが含まれます。
進化的アルゴリズム:
進化的アルゴリズムは、生物進化理論にヒントを得た最適化手法であり、問題を解決するために自然選択と遺伝的メカニズムをシミュレートします。これらのアルゴリズムは、集団内の個体の突然変異、交叉、選択を通じてソリューションを徐々に最適化します。このアプローチは、解空間内でのグローバルな検索を可能にして最適な解を見つけることができるため、複雑な問題を扱う場合に優れています。進化のプロセスをシミュレートすることにより、進化アルゴリズムは候補解を継続的に改善および調整して、新しい個体を生成できるようにすることができます。
一般的な進化アルゴリズムには、遺伝的アルゴリズム、進化戦略、遺伝的プログラミングなどが含まれます。
強化学習と進化的アルゴリズムは、その起源と思想的基盤が異なりますが、いくつかの側面では共通点もあります。たとえば、進化的アルゴリズムを使用して、強化学習のパラメータを最適化したり、強化学習の特定の下位問題を解決したりできます。さらに、これら 2 つの手法を組み合わせて、それぞれの手法の限界を克服する融合手法を形成することもあります (たとえば、ニューラル ネットワーク アーキテクチャの探索への応用では、進化的アルゴリズムと強化学習の考え方を組み合わせます)。
強化学習と進化アルゴリズムは、人工知能モデルをトレーニングする 2 つの異なる方法を表しており、それぞれに独自の利点と用途があります。
強化学習 (RL) では、エージェントはタスクを完了するために周囲の環境と対話することで意思決定スキルを獲得します。これには、エージェントが環境内でアクションを実行し、それらのアクションの結果に基づいて報酬またはペナルティの形でフィードバックを受け取ることが含まれます。時間の経過とともに、エージェントは報酬を最大化し、目標を達成するために意思決定プロセスを最適化する方法を学習します。強化学習は、自動運転、ゲーム、ロボット工学など、多くの分野で効果的に使用されています。
一方、進化的アルゴリズム (EA) は、自然選択のプロセスにヒントを得た最適化手法です。これらのアルゴリズムは、問題に対する潜在的な解決策 (個別または候補解決策として表される) が選択、複製、および突然変異を受けて新しい候補解決策を繰り返し生成する進化のプロセスをシミュレートすることによって機能します。 EA は、従来の最適化手法では困難が生じる可能性がある、複雑で非線形の探索空間を伴う最適化問題を解決するのに特に適しています。
AI モデルをトレーニングする場合、強化学習と進化アルゴリズムの両方に独自の利点があり、さまざまなシナリオに適しています。強化学習は、環境が動的で不確実であり、最適な解決策を事前に知ることができないシナリオで特に効果的です。たとえば、強化学習は、エージェントがビデオ ゲームをプレイするようにトレーニングするために使用され、成功しています。この場合、エージェントは、高スコアを達成するために、複雑で変化する環境をナビゲートする方法を学習する必要があります。
一方、進化的アルゴリズムは、巨大な探索空間、複雑な目的関数、およびマルチモーダル問題を伴う最適化問題を解決するのが得意です。たとえば、進化的アルゴリズムは、特徴選択、ニューラル ネットワーク アーキテクチャの最適化、ハイパーパラメータ調整などのタスクに使用されていますが、検索空間の次元が高いため、最適な構成を見つけることが困難です。
実際には、強化学習と進化アルゴリズムのどちらを選択するかは、問題の性質、利用可能なリソース、必要なパフォーマンス指標などのさまざまな要因によって異なります。場合によっては、2 つの方法の組み合わせ (ニューロエボリューションと呼ばれます) を使用して、RL と EA の利点を最大限に活用できます。 Neuroevolution では、強化学習技術を使用してトレーニングしながら、進化的アルゴリズムを使用してニューラル ネットワークのアーキテクチャとパラメータを進化させます。
まとめ
全体として、強化学習と進化アルゴリズムはどちらも人工知能モデルをトレーニングするための強力なツールであり、人工知能の分野の大幅な進歩に貢献してきました。特定の問題に対して最も適切な手法を選択し、AI モデルのトレーニング作業の効果を最大化するには、各アプローチの長所と限界を理解することが重要です。
以上がAI モデルのトレーニング: 強化アルゴリズムと進化アルゴリズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 PIXTRAL 12B対QWEN2-VL-72BApr 12, 2025 am 09:52 AM
PIXTRAL 12B対QWEN2-VL-72BApr 12, 2025 am 09:52 AM導入 AI革命は、テキストからイメージのモデルが芸術、デザイン、テクノロジーの交差点を再定義している創造性の新しい時代を生み出しました。 Pixtral 12bおよびqwen2-vl-72bは、2つの先駆的な力のドリビンです
 Paperqaとは何ですか、そしてそれは科学研究をどのように支援しますか?Apr 12, 2025 am 09:51 AM
Paperqaとは何ですか、そしてそれは科学研究をどのように支援しますか?Apr 12, 2025 am 09:51 AM導入 AIの進歩により、科学的研究では大きな変革が見られました。さまざまなテクノロジーやセクターで毎年何百万もの論文が掲載されています。しかし、この情報の海をretrに移動します
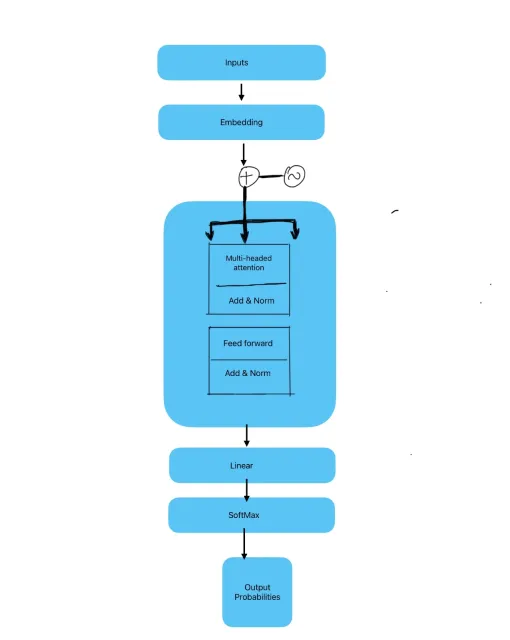 Datagemma:幻覚に対するLLMの接地 - 分析VidhyaApr 12, 2025 am 09:46 AM
Datagemma:幻覚に対するLLMの接地 - 分析VidhyaApr 12, 2025 am 09:46 AM導入 大規模な言語モデルは、産業を急速に変革しています。Todayは、銀行業務におけるパーソナライズされたカスタマーサービスからグローバルコミュニケーションのリアルタイム言語翻訳まで、あらゆるものを動かしています。彼らはクエストに答えることができます
 CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM
CrewaiとOllamaでマルチエージェントシステムを構築する方法は?Apr 12, 2025 am 09:44 AM導入 APIにお金を費やしたくないのですか、それともプライバシーを心配していますか?それとも、LLMSをローカルに実行したいだけですか?心配しないで;このガイドは、ローカルLLMSを使用してエージェントとマルチエージェントフレームワークを構築するのに役立ちます
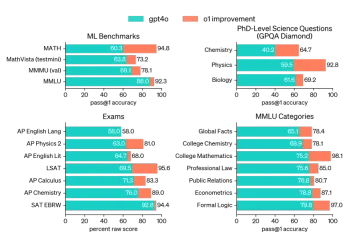 AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM
AVバイト:Openai' S O1モデル、Apple'の視覚的なAIなど - 分析VidhyaApr 12, 2025 am 09:38 AM導入 今週は、人工知能の世界(AI)の主要な更新が詰め込まれています。 OpenaiのO1モデルから、高度な推論の紹介からAppleの画期的な視覚知能技術、Techまで
 生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM
生産グレードのエージェントRAGパイプラインを監視する方法は?Apr 12, 2025 am 09:34 AM導入 2022年、CHATGPTの立ち上げにより、ハイテク産業と非テクノロジーの両方の業界の両方に革命をもたらし、個人や組織にAIを生成しました。 2023年を通じて、大規模な言語モードの活用に集中しました
 Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AM
Star Schemaを使用してデータウェアハウスを最適化する方法は?Apr 12, 2025 am 09:33 AMStar Schemaは、データウェアハウジングとビジネスインテリジェンスで使用される効率的なデータベース設計です。データを整理し、周囲の寸法テーブルにリンクされた中央のファクトテーブルになります。この星のような構造は、複雑なqを簡素化します
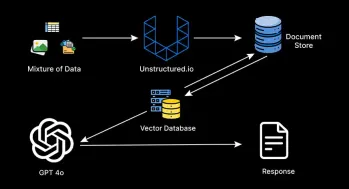 マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AM
マルチモーダルRAGシステムの構築に関する包括的なガイドApr 12, 2025 am 09:29 AMRAGシステムとしてよく知られている検索拡張生成システムは、高価な微調整の手間なしでカスタムエンタープライズデータに関する質問に答えるインテリジェントAIアシスタントを構築するための事実上の標準となっています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

