
ホームページ >テクノロジー周辺機器 >AI >CMU Zhu Junyan 氏と Adobe の新作: 512x512 の画像推論、A100 はわずか 0.11 秒かかります
CMU Zhu Junyan 氏と Adobe の新作: 512x512 の画像推論、A100 はわずか 0.11 秒かかります

- PHPz転載
- 2024-03-21 16:31:25874ブラウズ
単純なスケッチをワンクリックでマルチスタイルの絵画に変換し、追加の説明を追加できることは、CMU と Adobe が共同で立ち上げた研究で実現されました。
CMU 助教授 Junyan Zhu はこの研究の著者であり、彼のチームは ICCV 2021 カンファレンスで関連研究を発表しました。この研究では、既存の GAN モデルを 1 つまたは少数の手描きのスケッチでカスタマイズして、そのスケッチに一致する画像を生成する方法を示します。

- #論文アドレス: https://arxiv.org/pdf/2403.12036.pdf
- #GitHub アドレス: https://github.com/GaParmar/img2img-turbo #トライアルアドレス: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- 論文タイトル: テキスト付きのワンステップ画像翻訳 - to-Image モデル
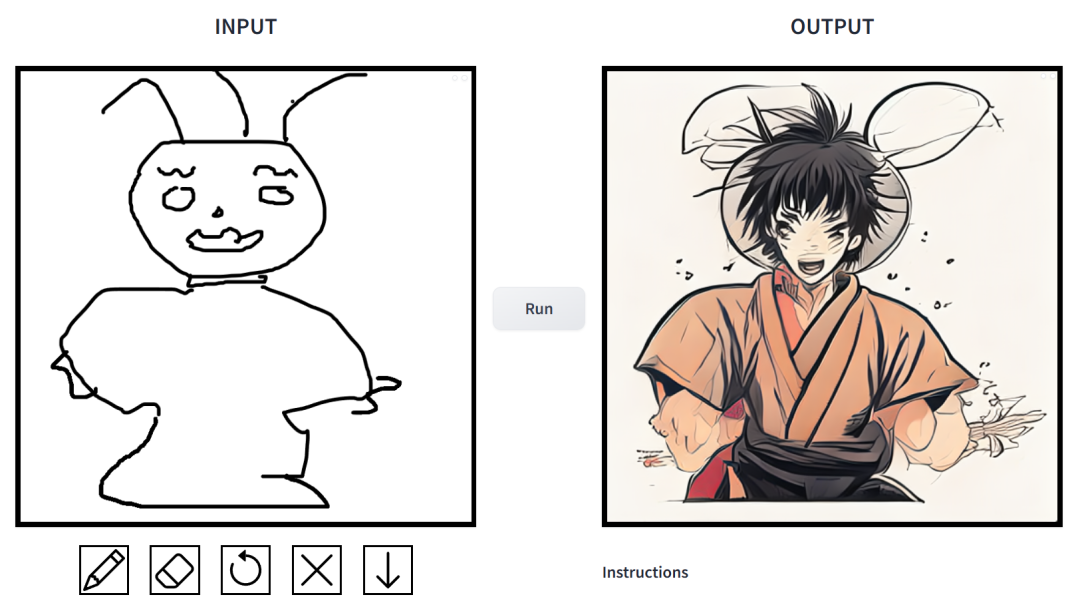
- それはどの程度効果的ですか?試してみたところ、非常にプレイしやすいという結論に達しました。出力画像スタイルは映画スタイル、3Dモデル、アニメーション、デジタルアート、写真スタイル、ピクセルアート、ファンタジースクール、ネオンパンク、コミックなど多岐にわたります。
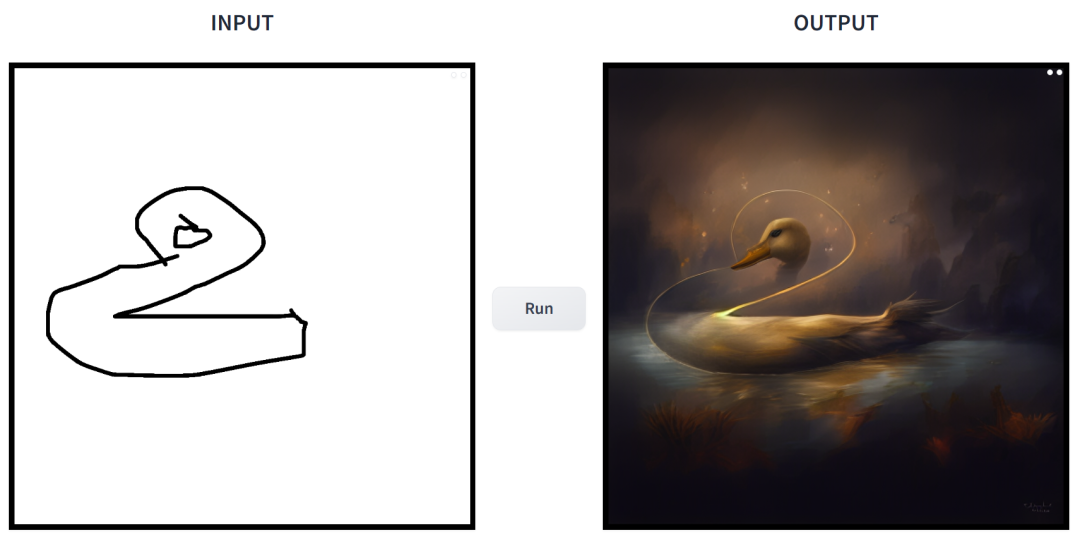 プロンプトは「アヒル」です。
プロンプトは「アヒル」です。
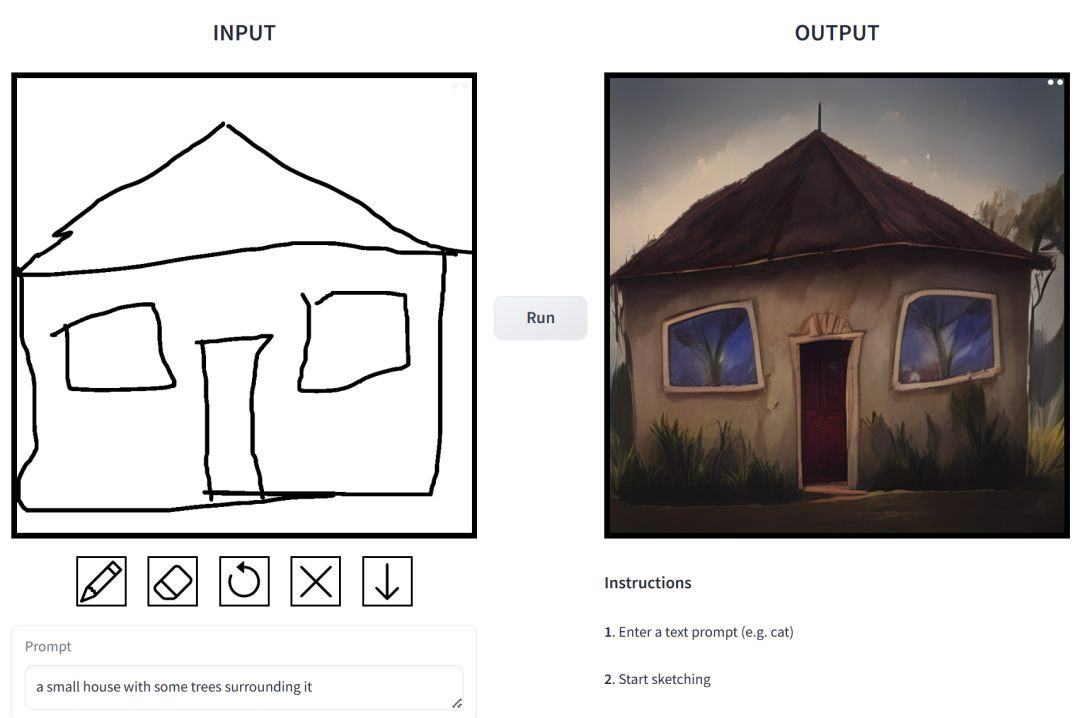 プロンプトは「植物に囲まれた小さな家」です。
プロンプトは「植物に囲まれた小さな家」です。
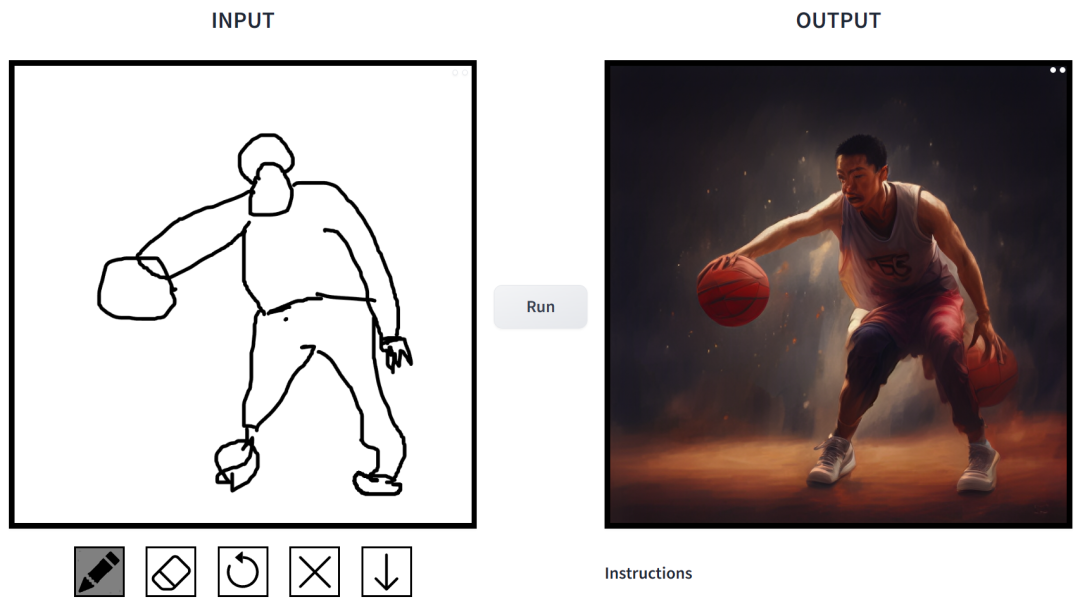 プロンプトは「バスケットボールをしている中国の少年たち」です。
プロンプトは「バスケットボールをしている中国の少年たち」です。
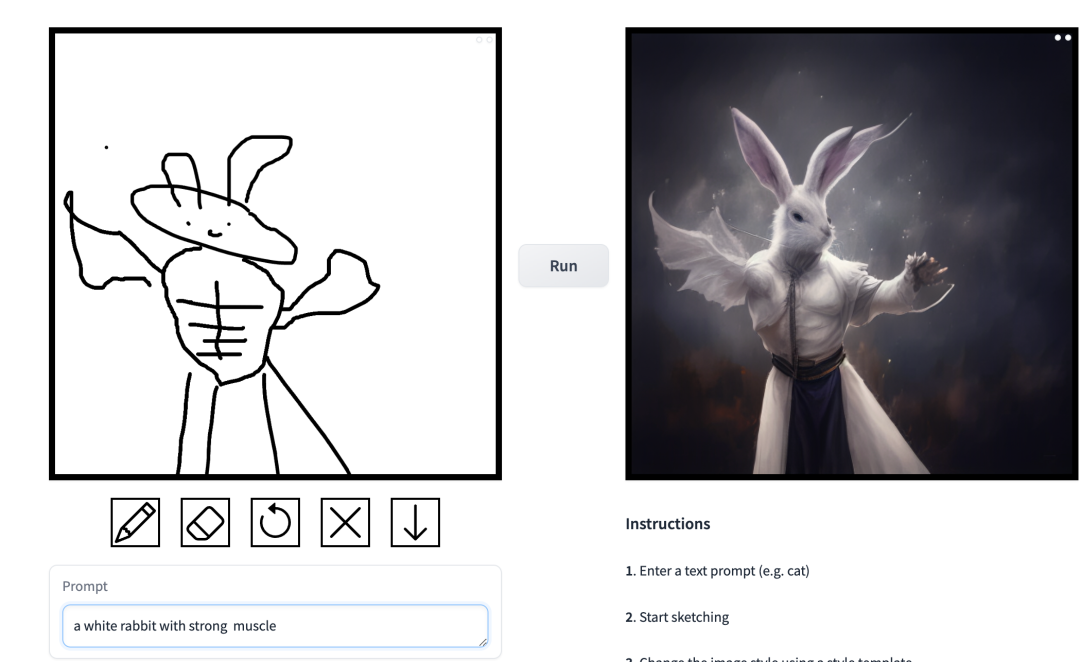 プロンプトは「マッスルマンウサギ」です。
プロンプトは「マッスルマンウサギ」です。

この研究では、研究者たちは、画像合成における条件付き拡散モデルの適用に存在する問題に対して的を絞った改善を行いました。このようなモデルを使用すると、ユーザーは、シーンのレイアウト、ユーザーのスケッチ、人間のポーズを正確に制御しながら、空間条件とテキスト プロンプトに基づいて画像を生成できます。
しかし問題は、拡散モデルの反復により推論速度が低下し、インタラクティブな Sketch2Photo などのリアルタイム アプリケーションが制限されることです。さらに、モデルのトレーニングには通常、大規模なペアのデータセットが必要ですが、これは多くのアプリケーションに多大なコストをもたらし、他の一部のアプリケーションでは実現不可能です。
条件付き拡散モデルの問題を解決するために、研究者は、敵対的学習目標を使用してシングルステップ拡散モデルを新しいタスクや新しい分野に適応させる一般的な方法を導入しました。具体的には、バニラ潜在拡散モデルの個々のモジュールを、トレーニング可能な小さな重みを備えた単一のエンドツーエンドの生成ネットワークに統合することで、過学習を低減しながら入力画像の構造を保持するモデルの機能を強化します。
研究者らは CycleGAN-Turbo モデルを立ち上げました。ペアになっていない設定では、このモデルは、昼夜などのさまざまなシーン変換タスクにおいて、既存の GAN や拡散ベースの手法よりも優れたパフォーマンスを発揮できます。 、霧、雪、雨などの気象効果を追加または削除します。
同時に、研究者らは独自のアーキテクチャの汎用性を検証するために、ペア設定で実験を実施しました。結果は、彼らのモデル pix2pix-Turbo が Edge2Image や Sketch2Photo に匹敵する視覚効果を実現し、推論ステップが 1 ステップに削減されることを示しています。
要約すると、この研究は、ワンステップで事前トレーニングされたテキストから画像へのモデルが、多くの下流の画像生成タスクの強力で汎用性の高いバックボーンとして機能できることを示しています。
方法の紹介
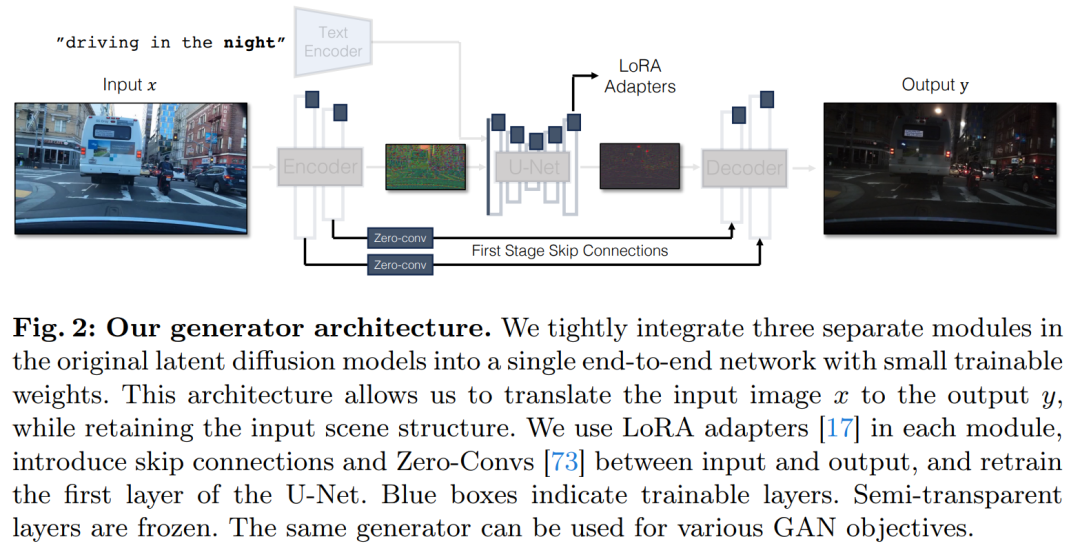
この研究では、シングルステップ拡散モデル (SD-Turbo など) と敵対的学習を組み合わせた一般的な方法を提案します。新しいタスクとドメインに適応します。これにより、事前トレーニングされた拡散モデルの内部知識が活用され、効率的な推論が可能になります (たとえば、512x512 画像の場合、A6000 では 0.29 秒、A100 では 0.11 秒)。
さらに、シングルステップ条件付きモデル CycleGAN-Turbo および pix2pix-Turbo は、ペアごとの設定と非ペアごとの設定の両方に適したさまざまな画像間の変換タスクを実行できます。 CycleGAN-Turbo は既存の GAN ベースおよび拡散ベースの手法を上回っており、pix2pix-Turbo は Sketch2Photo や Edge2Image 用の ControlNet などの最近の研究と同等ですが、シングルステップ推論の利点を備えています。
条件付き入力を追加します
テキストから画像へのモデルを画像変換モデルに変換するには、最初に行うことは、入力画像 x をモデルに組み込む効率的な方法を見つけることです。
条件付き入力を拡散モデルに組み込むための一般的な戦略は、図 3 に示すように、追加のアダプター ブランチを導入することです。
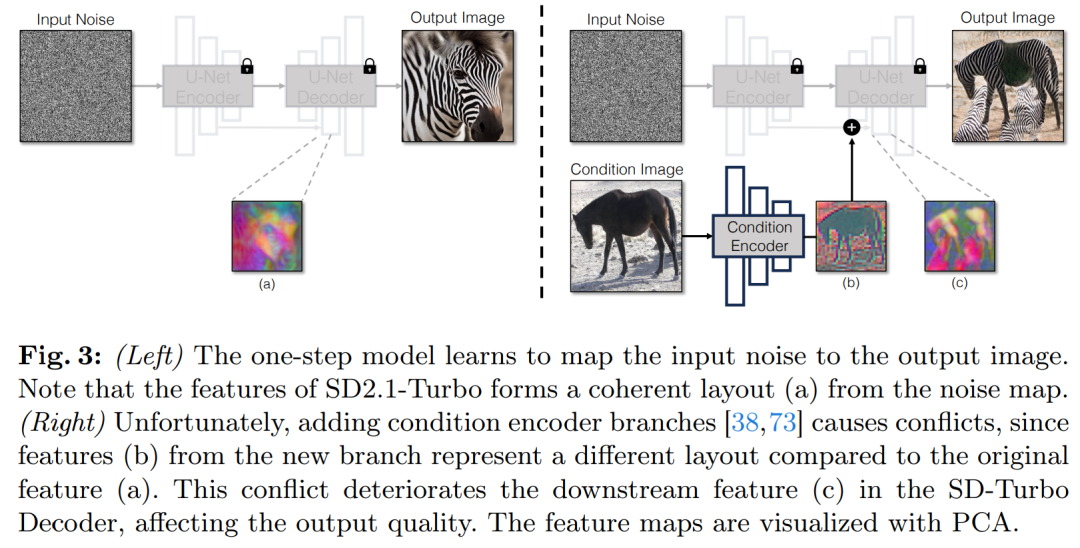
具体的には、この調査では 2 番目のエンコーダーを初期化し、それを条件エンコーダー (条件エンコーダー) としてラベル付けします。コントロール エンコーダーは入力画像 x を受け入れ、残留接続を通じて複数の解像度の特徴マップを事前トレーニングされた安定拡散モデルに出力します。この方法は、拡散モデルの制御において顕著な結果をもたらします。
図 3 に示すように、この調査では、シングル ステップ モデルで 2 つのエンコーダー (U-Net エンコーダーと条件付きエンコーダー) を使用して、ノイズの多い画像を処理し、入力画像に課題が発生します。マルチステップ拡散モデルとは異なり、シングルステップ モデルのノイズ マップは、生成されたイメージのレイアウトとポーズを直接制御しますが、これは多くの場合、入力イメージの構造と矛盾します。したがって、デコーダは異なる構造を表す 2 セットの残差特徴を受け取るため、トレーニング プロセスがより困難になります。
#直接条件付き入力。図 3 は、事前トレーニングされたモデルによって生成された画像構造がノイズ マップ z によって大きく影響されることも示しています。この洞察に基づいて、研究では条件付き入力をネットワークに直接フィードすることを推奨しています。バックボーン モデルを新しい条件に適応させるために、研究では U-Net のさまざまなレイヤーにいくつかの LoRA 重みを追加しました (図 2 を参照)。
入力詳細の保持
潜在拡散モデル (LDM) 画像エンコーダは、入力画像を空間的に分解して動作します。レート圧縮は 8 倍になり、チャネル数が 3 から 4 に増加して、拡散モデルのトレーニングと推論プロセスが高速化されます。この設計ではトレーニングと推論を高速化できますが、入力画像の詳細を保持する必要がある画像変換タスクには理想的ではない可能性があります。図 4 はこの問題を示しています。ここでは、昼間の運転の入力画像 (左) を取得し、スキップ接続を使用しないアーキテクチャ (中央) を使用して、それを夜間の運転の対応する画像に変換します。文字、道路標識、遠くの車などの細かい部分が保存されていないことがわかります。対照的に、スキップ接続を含むアーキテクチャを使用して変換されたイメージ (右) は、これらの複雑な詳細をよりよく保存しています。

入力画像の詳細な視覚的詳細をキャプチャするために、この研究ではエンコーダ ネットワークとデコーダ ネットワークの間にスキップ接続を追加しました (図 2 を参照) 。具体的には、この研究では、エンコーダ内の各ダウンサンプリング ブロックの後に 4 つの中間アクティベーションを抽出し、それらをデコーダ内の対応するアップサンプリング ブロックに供給する前に、1 × 1 のゼロ畳み込み層を通じて処理します。このアプローチにより、画像変換中に複雑な詳細が確実に保持されます。
実験
この研究では、CycleGAN-Turbo と以前の GAN ベースの非ペア画像変換を組み合わせています。方法を比較しました。定性分析から、図 5 と図 6 は、GAN ベースの方法でも拡散ベースの方法でも、出力画像のリアリズムと構造の維持との間のバランスを達成できないことを示しています。


研究では、CycleGAN-Turbo と CycleGAN および CUT も比較されました。表 1 および 2 は、8 つのペアになっていないスイッチング タスクに関する定量的比較の結果を示しています。
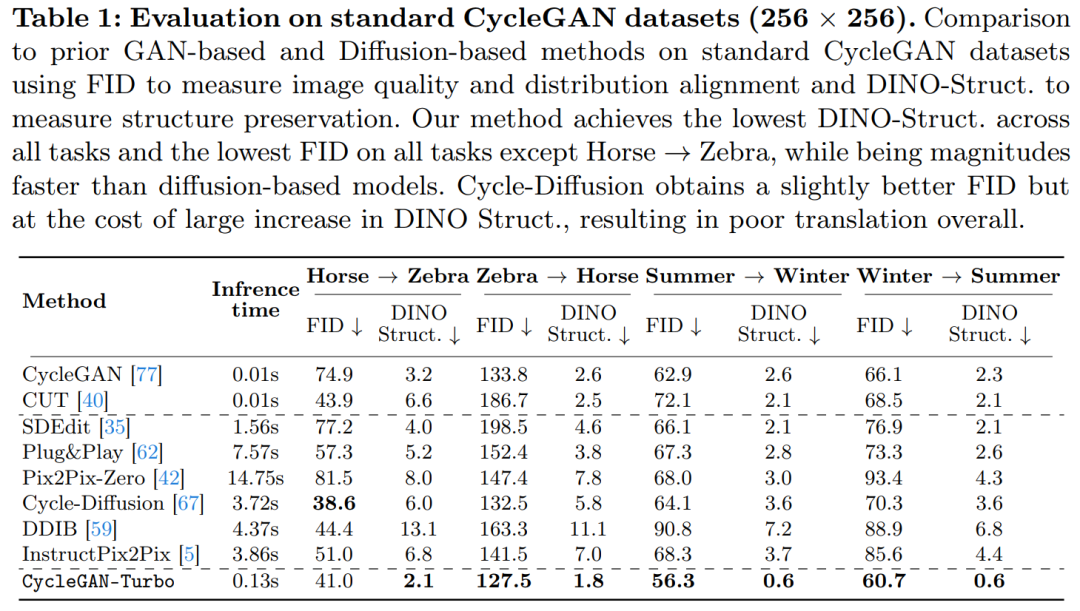
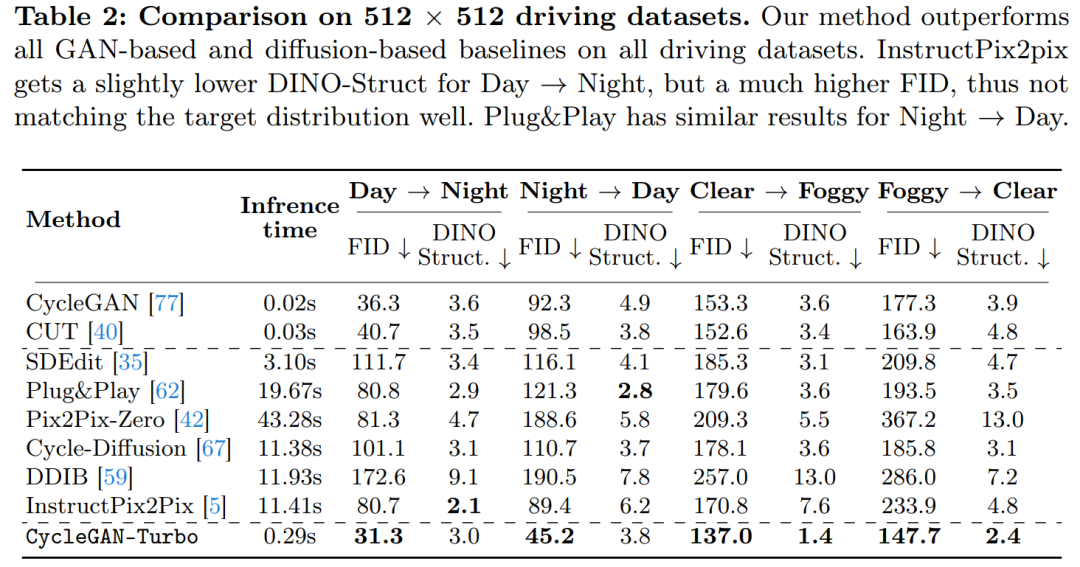
CycleGAN とよりシンプルなオブジェクト中心のデータの CUT セット上では、次のような馬 → シマウマ (図 13) のように、効果的なパフォーマンスを示し、低い FID および DINO-Structure スコアを達成します。私たちの方法は、FID および DINO-Structure 距離メトリックにおいて、これらの方法よりわずかに優れています。

運転データセットでは、これらの編集方法のパフォーマンスは次の 3 つの理由により大幅に低下します: (1) モデルは複数のオブジェクトを含む複雑なシーンを生成するのが難しい、(2) これらの方法 (Instruct を除く) -pix2pix) 最初に画像をノイズ マップに反転する必要があり、潜在的な人的エラーが発生します。(3) 事前トレーニングされたモデルは、走行データセットによってキャプチャされたものと同様のストリート ビュー画像を合成できません。表 2 と図 16 は、4 つの運転移行タスクすべてで、これらの方法が低品質の画像を出力し、入力画像の構造に従っていないことを示しています。

 #
#
以上がCMU Zhu Junyan 氏と Adobe の新作: 512x512 の画像推論、A100 はわずか 0.11 秒かかりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。