
ホームページ >テクノロジー周辺機器 >AI >顧客のプライバシーを保護するために、Ruby を使用してオープンソース AI モデルをローカルで実行します。
顧客のプライバシーを保護するために、Ruby を使用してオープンソース AI モデルをローカルで実行します。

- 王林転載
- 2024-03-18 21:40:03750ブラウズ
#翻訳者| Chen Jun
##査読者| Chonglou最近、カスタマイズされた人工知能 (AI) プロジェクトを実装しました。当事者 A が非常に機密性の高い顧客情報を保持していることを考慮すると、セキュリティ上の理由から、その情報を
OpenAI や他の独自モデルに渡すことはできません。したがって、オープンソース AI モデルを AWS 仮想マシンにダウンロードして実行し、完全に管理下に置きました。同時に、Rails アプリケーションは安全な環境で AI への API 呼び出しを行うことができます。もちろん、セキュリティの問題を考慮する必要がない場合は、OpenAI と直接協力することを希望します。

#Ruby スクリプトを実行します。 #カスタマイズする理由
#このプロジェクトの動機は単純です。それはデータのセキュリティです。機密性の高い顧客情報を扱う場合、通常、最も信頼できるアプローチは社内で行うことです。したがって、より高いレベルのセキュリティ制御とプライバシー保護を提供する役割を果たすために、カスタマイズされた AI モデルが必要です。
#オープンソース モデル
過去の6
過去数か月間、Mistral、Mixtral、Lama などの製品が登場しました。 ## やその他多くのオープンソース AI モデルが市場に登場しました。 GPT-4 ほど強力ではありませんが、その多くのパフォーマンスは GPT-3.5 を上回っています。時間が経つにつれて、彼らはますます強くなります。もちろん、どのモデルを選択するかは、処理能力と何を達成する必要があるかによって決まります。 #AI モデルをローカルで実行するため、約 4GB
のサイズが選択されましたミストラル。ほとんどの指標で GPT-3.5 を上回ります。 Mixtral は Mistral よりもパフォーマンスが優れていますが、少なくとも 48GB# が必要な大容量のモデルです。 ##メモリは実行できます。 パラメータ
大規模な言語モデル (LLM) についての話)、パラメータのサイズについて言及することをよく検討します。ここで、ローカルで実行する
Mistral モデルは、7,000 万個のパラメータを持つ 70# モデルです (もちろん Mixtral には 700 億のパラメータがあり、GPT-3.5 には約 があります。 1750 億パラメータ)。 # 通常、大規模な言語モデルではニューラル ネットワーク ベースの手法が使用されます。ニューラル ネットワークはニューロンで構成され、各ニューロンは次の層の他のすべてのニューロンに接続されます。
上の図に示すように、各接続には重みがあります。 、通常はパーセンテージで表されます。各ニューロンにはバイアスもあり、データがノードを通過するときにデータを修正します。 ニューラル ネットワークの目的は、高度なアルゴリズム、つまりパターン マッチング アルゴリズムを「学習」することです。大量のテキストでトレーニングを受けることで、テキストのパターンを予測し、与えられた合図に有意義に応答する能力を徐々に学習します。簡単に言うと、パラメーターはモデル内の重みとバイアスの数です。これにより、ニューラル ネットワーク内にいくつのニューロンが存在するかがわかります。たとえば、70 億個のパラメーターを持つモデルの場合、約 100 層があり、それぞれに数千のニューロンが含まれます。 オープン ソース モデルをローカルで実行するには、次のことを行う必要があります。まずは関連アプリケーションをダウンロードしてください。市場には多くのオプションがありますが、IntelMac で実行するのに最も簡単で簡単だと思うのは Ollama です。 ただし、Ollama は現在 Mac でのみ利用可能です。 Linux 上で動作しますが、将来的には Windows でも動作する予定です。もちろん、WSL (Linux 用 Windows サブシステム) を使用して、Windows 上で Linux シェル# を実行することもできます。 ####。 Ollama を使用すると、さまざまなオープン ソース モデルをダウンロードして実行できるだけでなく、ローカル ポートでモデルを開くこともできます。 Ruby コードで API 呼び出しを行うことができます。これにより、Ruby 開発者は、ローカル モデルと統合できる Ruby アプリケーションを簡単に作成できるようになります。 Get Mac# および Linux システムに Ollama をインストールするのは非常に簡単です。リンク #https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5 から Ollama をダウンロードするだけです。5# を費やしてください。 ##ソフトウェア パッケージをインストールしてモデルを実行するには、約 1 分かかります。 #最初のモデルをインストールします ##ollama run misstral #Mistral は約 4GB であるため、ダウンロードが完了するまでに時間がかかります。ダウンロードが完了すると、Mistral と対話して通信するための Ollama プロンプトが自動的に開きます。 では、対応するモデルを直接実行できます。 #カスタマイズされたモデル # に作成します。Ollama を通じて、基本モデルをカスタマイズできます。ここでは、カスタム モデルを簡単に作成できます。より詳細なケースについては、Ollama のオンライン ドキュメントを参照してください。 まず、Modelfile (モデル ファイル) を作成し、その中に次のテキストを追加します。 FROM misstral# 温度を設定します応答のランダム性または創造性を設定しますPARAMETER 温度 0.3# システム メッセージを設定しますSYSTEM ”””あなたは抜粋の Ruby 開発者です。Ruby プログラミング言語について質問されます。コード例とともに説明します。””” #上記のシステム メッセージは、AI モデルの特定の応答の基礎です。 ollama create 私たちのプロジェクトの場合、モデルにRuby##という名前を付けました。 #。 ollam create Ruby -f './Modelfile'同時に、以下を使用できます。自分自身をリストして表示するには、次のコマンドを実行します。 既存のモデル: この時点で、次のコマンドを使用してカスタム モデルを実行できます: Ollama にはまだ専用の gem がありませんが、 Ruby 開発者は、基本的な HTTP リクエスト メソッドを使用してモデルを操作できます。バックグラウンドで実行されている Ollama は、11434 ポートを介してモデルを開くことができるため、「https://www.php」経由でモデルを開くことができます。 cn/link/ dcd3f83c96576c0fd437286a1ff6f1f0」とアクセスしてください。さらに、OllamaAPI のドキュメントでは、チャット会話や埋め込みの作成などの基本的なコマンド用のさまざまなエンドポイントも提供しています。 このプロジェクトの場合、/api/chat エンドポイントを使用して、プロンプトをAIモデル。以下の画像は、モデルと対話するための基本的な Ruby コードを示しています。 上記の Ruby コード スニペットの機能には次のものが含まれます: 翻訳者紹介 Julian Chen )、51CTO コミュニティ編集者は、IT プロジェクトの実装に 10 年以上の経験があり、社内外のリソースとリスクの管理と制御に優れ、ネットワークと情報セキュリティの知識と経験の普及に重点を置いています。 #元のタイトル: ##Ruby を使用してオープンソース AI モデルをローカルで実行する方法 ケイン・フーパー著 ##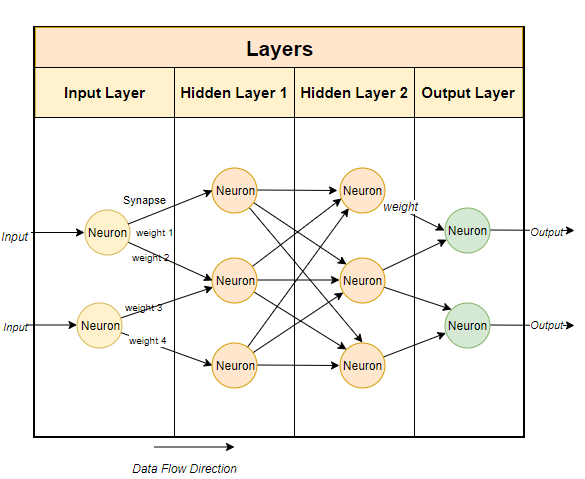
#モデルをローカルで実行する
OllamaOllama は主に以下に基づいているため、コマンドラインを使用するため、
Ollama をセットアップして実行すると、ブラウザのタスクバーに Ollama アイコンが表示されます。これは、バックグラウンドで実行されており、モデルを実行できることを意味します。モデルをダウンロードするには、ターミナルを開いて次のコマンドを実行します:
##OpenAI のものと同様## カスタマイズされた GPT
を 次に、ターミナルで次のコマンドを実行して新しいモデルを作成できます:
Ruby との統合
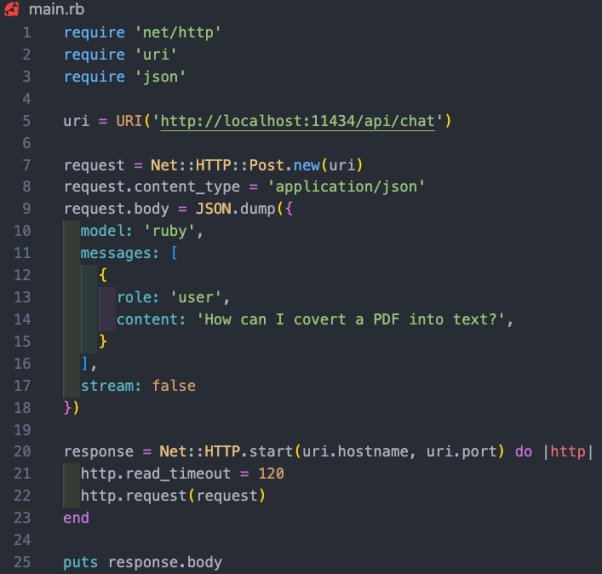
モデル キーは、今回のモデルである "
メッセージ ハッシュは、AI モデルと交差するパターンに従います。キャラクターとコンテンツが付属しています。ここでの役割は、システム、ユーザー、および補助です。このうち、
前述のように、ローカル AI モデルを実行します本当の価値は、機密データを保持し、電子メールや文書などの非構造化データを処理し、貴重な構造化情報を抽出する企業を支援することにあります。私たちが参加したプロジェクト ケースでは、顧客関係管理 (CRM) システム内のすべての顧客情報に対してモデル トレーニングを実施しました。これにより、ユーザーは何百ものレコードを調べなくても、顧客について質問できるようになります。
以上が顧客のプライバシーを保護するために、Ruby を使用してオープンソース AI モデルをローカルで実行します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。