



私はあなたに会ったことはありませんが、あなたを「知る」ことは可能です。これは、人々が人工知能が「一目見た」後に達成することを望んでいる状態です。
この目標を達成するために、従来の画像認識タスクでは、さまざまなカテゴリ ラベルを持つ多数の画像サンプルでアルゴリズム モデルをトレーニングし、モデルが次の能力を獲得できるようにします。これらの画像を認識します。ゼロショット学習 (ZSL) タスクでは、人々はモデルが推論を導き、トレーニング段階で画像サンプルを見ていないカテゴリを識別できることを期待しています。
生成ゼロショット学習 (GZSL) は、ゼロショット学習の効果的な方法と考えられています。 GZSL では、最初のステップは、目に見えないカテゴリの視覚的特徴を合成するようにジェネレーターをトレーニングすることです。この生成プロセスは、属性ラベルなどの意味論的な記述を条件として利用することによって推進されます。これらの仮想視覚特徴が生成されたら、従来の分類子と同じように、目に見えないクラスを認識できる分類モデルのトレーニングを開始できます。
ジェネレーターのトレーニングは、生成ゼロショット学習アルゴリズムにとって非常に重要です。理想的には、意味論的記述に基づいてジェネレータによって生成された目に見えないカテゴリの視覚的特徴サンプルは、そのカテゴリの実際のサンプルの視覚的特徴と同じ分布を有するべきである。これは、高度な一貫性と信頼性を備えたサンプルを生成するために、ジェネレータが視覚的特徴間の関係とパターンを正確にキャプチャできる必要があることを意味します。ジェネレーターをトレーニングすることにより、さまざまなカテゴリ間の視覚的特徴の違いを効果的に学習できます。
既存の生成ゼロショット学習方法では、ジェネレーターはトレーニング中および使用中にガウス ノイズを発生させます。カテゴリ全体の意味記述が条件付けされているため、ジェネレータは各サンプル インスタンスを説明するのではなくカテゴリ全体を最適化するのみに制限されているため、実際のサンプルの視覚的特徴を正確に反映することが困難であり、一般化パフォーマンスが低下します。モデル。さらに、見えるクラスと見えないクラスによって共有されるデータセットの視覚情報、つまりドメイン知識は、ジェネレーターのトレーニングプロセスでは十分に活用されず、見えるクラスから見えないクラスへの知識の伝達が制限されます。
これらの問題を解決するために、華中科技大学の大学院生とアリババの銀泰商業グループの技術専門家は、Visually Enhanced Dynamic Semantic Prototyping (VADS) と呼ばれる手法を提案しました。このアプローチにより、認識されたクラスの視覚的特徴がセマンティック条件にさらに完全に導入され、プッシュ ジェネレーターが正確なセマンティックと視覚のマッピングを学習できるようになります。本研究論文「生成ゼロショット学習のための視覚拡張動的セマンティックプロトタイプ」が、コンピュータビジョン分野のトップ国際学会であるCVPR 2024に採択されました。
具体的には、上記の研究は 3 つの革新的な点を示しています。
ゼロショット学習では、視覚的な機能を使用してジェネレーターを強化します。信頼性の高い視覚的特徴を生成するための革新的な方法です。
研究では、VDKL と VOSU という 2 つのコンポーネントも導入されました。これらのコンポーネントの助けを借りて、データ セットの視覚的事前情報が効果的に取得され、データ セットの視覚的特徴が動的に更新されます。画像、予測 定義されたカテゴリの意味的説明が更新されました。この手法は視覚的な特徴を有効に活用しています。
実験結果は、この研究で視覚的機能を使用してジェネレーターを強化する効果が非常に重要であることを示しています。このプラグアンドプレイのアプローチは汎用性が高いだけでなく、発電機のパフォーマンスの向上にも優れています。
研究詳細
VADSは2つのモジュールで構成されています: (1) 視覚知覚領域知識学習モジュール(VDKL)は、視覚特徴の局所偏差と大域事前確率を学習します。 、純粋なガウス ノイズを置き換え、より豊富な事前ノイズ情報を提供するドメイン視覚知識 (2) ビジョン指向セマンティック更新モジュール (VOSU) は、サンプルの視覚的表現と更新されたドメインに従ってセマンティック プロトタイプを更新する方法を学習します。視覚的な知識もセマンティック プロトタイプに含まれます。
最後に、研究チームは、ジェネレーターの条件として、2 つのモジュールの出力を動的セマンティック プロトタイプ ベクトルに連結しました。多くの実験により、VADS 手法は、一般的に使用されるゼロショット学習データセットに対して既存の手法よりも大幅に優れたパフォーマンスを達成し、他の生成ゼロショット学習手法と組み合わせて精度を全体的に向上させることができることが示されています。
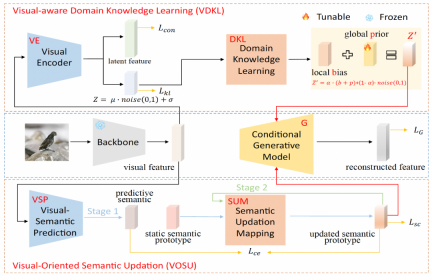
視覚認識ドメイン知識学習モジュール (VDKL) では、研究チームはビジュアル エンコーダー (VE) とドメイン知識学習ネットワーク ( DKL)。このうち、VE は視覚的特徴を潜在特徴と潜在エンコーディングにエンコードします。ジェネレーターのトレーニング段階で、表示されたクラス画像サンプルを使用して VE をトレーニングするためにコントラスト損失を使用することにより、VE は視覚特徴のクラス分離性を強化できます。
ZSL 分類器をトレーニングするとき、ジェネレーターによって生成された目に見えない視覚特徴も VE に入力され、取得された潜在特徴は、最終的な視覚特徴サンプルとして生成された視覚特徴と接続されます。 。 VE のもう 1 つの出力、つまり潜在エンコーディングは、DKL 変換後にローカル偏差 b を形成します。学習可能なグローバル事前 p およびランダム ガウス ノイズとともに、ドメイン関連の視覚的事前ノイズに結合され、他の生成ゼロ サンプルを置き換えます。 . ジェネレーター生成条件の一部として学習で一般的に使用される純粋なガウス ノイズ。
ビジョン指向セマンティック更新モジュール (VOSU) では、研究チームは視覚的セマンティック予測子 VSP とセマンティック更新マッピング ネットワーク SUM を設計しました。 VOSU のトレーニング フェーズでは、VSP は画像の視覚的特徴を入力として受け取り、ターゲット画像の視覚的パターンをキャプチャできる予測セマンティック ベクトルを生成します。同時に、SUM はカテゴリ セマンティック プロトタイプを入力として受け取り、それを更新して取得します。更新されたセマンティック プロトタイプと、予測されたセマンティック ベクトルと更新されたセマンティック プロトタイプの間のクロス エントロピー損失を最小限に抑えることによって、VSP と SUM がトレーニングされます。 VOSU モジュールは、視覚的な特徴に基づいてセマンティック プロトタイプを動的に調整できるため、ジェネレーターは新しいカテゴリの特徴を合成するときに、より正確なインスタンス レベルのセマンティック情報に依存できます。
実験部分では、上記の研究では、学術界で一般的に使用されている 3 つの ZSL データセット、属性 2 を持つ動物 (AWA2)、SUN 属性 (SUN)、および Caltech-USCD Birds-200 を使用しました。 -2011 (CUB)、従来のゼロショット学習および一般化されたゼロショット学習の主要指標と他の最近の代表的な手法との包括的な比較。
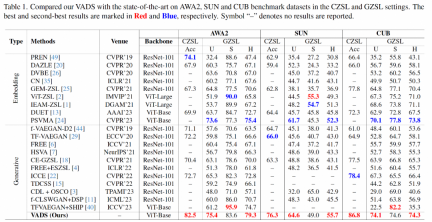
従来のゼロショット学習の Acc 指標に関して、この研究で研究された方法は、既存の方法と比較して大幅な精度の向上を達成しました。 3 つのデータセットではそれぞれ 8.4%、10.3%、8.4% リードしています。一般化されたゼロショット学習シナリオでは、上記の研究方法は、未見のクラスの調和平均指数 H と既知のクラスの精度でも主導的な位置にあります。
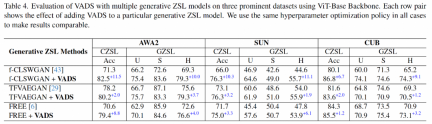
VADS メソッドは、他の生成ゼロショット学習メソッドと組み合わせることもできます。たとえば、CLSWGAN、TF-VAEGAN、および FREE の 3 つの方法と組み合わせた後、3 つのデータセットの Acc および H インジケーターは大幅に改善され、3 つのデータセットの平均改善率は 7.4%/5.9%、5.6% です。 /6.4%と3.3%/4.2%。
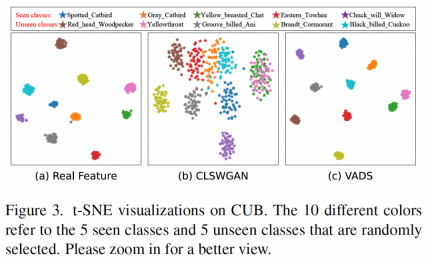
ジェネレーターによって生成された視覚的特徴を視覚化すると、次のようないくつかのカテゴリの特徴がもともと混同されていたことがわかります。図 (b) のように、可視クラス「Yellow Breasted Chat」と目に見えないクラス「Yellowthroat」に示されている 2 種類の特徴は、VADS 手法を使用した後、図 (c) の 2 つのクラスターに明確に分離できるため、分類 マシントレーニング中の混乱。
インテリジェント セキュリティおよび大規模モデルの分野に拡張可能
Machine Heart は、研究チームが焦点を当てているゼロショット学習は、トレーニング段階で画像サンプルなしでモデルが新しいカテゴリを認識できるようにすることを目的としており、インテリジェントセキュリティの分野で潜在的な価値があります。
まず、セキュリティ シナリオにおける新たなリスクに対処します。新しい脅威の種類や異常な動作パターンは引き続きセキュリティ シナリオに出現するため、以前のトレーニング データに出現する可能性があります。 には出現しませんでした。ゼロショット学習により、セキュリティ システムは新しいリスク タイプを迅速に特定して対応できるため、セキュリティが向上します。
2 番目に、サンプル データへの依存を減らす: 効果的なセキュリティ システムをトレーニングするために十分な注釈付きデータを取得するには、費用と時間がかかります。ゼロショット学習により、システムの多数への依存が軽減されます。画像サンプルの依存性を高め、研究開発コストを節約します。
第三に、動的環境での安定性の向上: ゼロショット学習では、セマンティック記述を使用して、目に見えないクラス パターンを認識します。画像の特徴に完全に依存する従来の方法と比較して、視覚環境の変化自然により安定します。
このテクノロジーは、画像分類問題を解決するための基盤テクノロジーとして、人、物品、車両、オブジェクトの属性認識など、視覚的分類テクノロジーに依存するシナリオにも実装できます。 、行動認識など。特に、識別する新しいカテゴリを迅速に追加する必要があり、トレーニング サンプルを収集する時間がない、または大量のサンプルを収集するのが難しいシナリオ (リスク識別など) では、ゼロショット学習テクノロジーは大きな利点をもたらします。従来の方法よりも。
この研究技術は、現在の大型モデルの開発に参考になりますか?
研究者らは、生成ゼロショット学習の中核となるアイデアは、視覚言語モデル (CLIP など) と一致する意味空間と視覚特徴空間を調整することであると信じています。 ) 現在のマルチモーダル大規模モデルでは、研究目的は一貫しています。
それらの最大の違いは、生成ゼロショット学習は事前定義された限定されたカテゴリ データセットでトレーニングおよび使用されるのに対し、視覚言語の大規模モデルは大規模なデータセットでトレーニングされることです。データは、限られたカテゴリに限定されない普遍的な意味論的表現力と視覚的表現力を獲得しており、基本モデルとしてより幅広い応用範囲を持っています。
テクノロジーの適用シナリオが特定の分野である場合、大規模なモデルをこの分野に適応させて微調整することを選択できます。そのプロセスでは、同じまたは類似した分野で作業します。この記事のような研究の方向性、理論は、いくつかの有用なインスピレーションをもたらす可能性があります。
著者紹介
Hou Wenjin は華中科技大学の修士課程の学生で、コンピュータ ビジョン、生成モデリング、少数ショット学習などの研究に興味を持っています。 、など。彼はアリババで働いています。この論文の作業は、銀泰ビジネスでのインターンシップ中に完了しました。
Wang Yan 氏、Alibaba-Intime コマーシャル テクノロジー ディレクター、深セン Xiang インテリジェント チームのアルゴリズム リーダー。
Alibaba-Intime Business のシニア アルゴリズム エキスパートである Feng Xuetao は、主にオフライン小売業界やその他の業界におけるビジュアルおよびマルチモーダル アルゴリズムのアプリケーションに焦点を当てています。
以上が生成ゼロショット学習機能を改善し、視覚的に強化された動的セマンティック プロトタイピング手法が CVPR 2024 に選ばれましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AM
Gemma Scope:AI'の思考プロセスを覗くためのGoogle'の顕微鏡Apr 17, 2025 am 11:55 AMジェマの範囲で言語モデルの内部の仕組みを探る AI言語モデルの複雑さを理解することは、重要な課題です。 包括的なツールキットであるGemma ScopeのGoogleのリリースは、研究者に掘り下げる強力な方法を提供します
 ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AM
ビジネスインテリジェンスアナリストは誰で、どのようになるか?Apr 17, 2025 am 11:44 AMビジネスの成功のロック解除:ビジネスインテリジェンスアナリストになるためのガイド 生データを組織の成長を促進する実用的な洞察に変換することを想像してください。 これはビジネスインテリジェンス(BI)アナリストの力です - GUにおける重要な役割
 SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析VidhyaApr 17, 2025 am 11:43 AMSQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM
ビジネスアナリストとデータアナリストApr 17, 2025 am 11:38 AM導入 2人の専門家が重要なプロジェクトで協力している賑やかなオフィスを想像してください。 ビジネスアナリストは、会社の目標に焦点を当て、改善の分野を特定し、市場動向との戦略的整合を確保しています。 シム
 ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AM
ExcelのCountとCountaとは何ですか? - 分析VidhyaApr 17, 2025 am 11:34 AMExcelデータカウントと分析:カウントとカウントの機能の詳細な説明 特に大規模なデータセットを使用する場合、Excelでは、正確なデータカウントと分析が重要です。 Excelは、これを達成するためにさまざまな機能を提供し、CountおよびCounta関数は、さまざまな条件下でセルの数をカウントするための重要なツールです。両方の機能はセルをカウントするために使用されますが、設計ターゲットは異なるデータ型をターゲットにしています。 CountおよびCounta機能の特定の詳細を掘り下げ、独自の機能と違いを強調し、データ分析に適用する方法を学びましょう。 キーポイントの概要 カウントとcouを理解します
 ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AM
ChromeはAIと一緒にここにいます:毎日何か新しいことを体験してください!!Apr 17, 2025 am 11:29 AMGoogle Chrome'sAI Revolution:パーソナライズされた効率的なブラウジングエクスペリエンス 人工知能(AI)は私たちの日常生活を急速に変換しており、Google ChromeはWebブラウジングアリーナで料金をリードしています。 この記事では、興奮を探ります
 ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AM
ai' s Human Side:Wellbeing and the Quadruple bottuntApr 17, 2025 am 11:28 AMインパクトの再考:四重材のボトムライン 長い間、会話はAIの影響の狭い見方に支配されており、主に利益の最終ラインに焦点を当てています。ただし、より全体的なアプローチは、BUの相互接続性を認識しています
 5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM
5ゲームを変える量子コンピューティングの使用ケースあなたが知っておくべきであるApr 17, 2025 am 11:24 AM物事はその点に向かって着実に動いています。量子サービスプロバイダーとスタートアップに投資する投資は、業界がその重要性を理解していることを示しています。そして、その価値を示すために、現実世界のユースケースの数が増えています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

WebStorm Mac版
便利なJavaScript開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

